1375
Яким чином можна довіряти соціологічні дослідження?
193308
Причиною написання цієї статті було це дослідження, яке було обговорення раніше.
З моєю вищою технічною освітою та любов’ю точної науки та особливо математики, я оціню та поважати теорії, які застосовні в житті та надавати практичні переваги (всупереч поширеній вірі, що теорія релятивності не має відношення до повсякденного життя, варто вивчити теорію GPS-систем та зйомки ракет на планетарному масштабі). З цієї точки зору ми розглянемо таку частину статистики як соціологічні опитування. Дуже модний.
Давайте подивимося на неї очима людини далеко від формул.
У нас є село, де 100 людей живуть. Ми хочемо дізнатися, як мешканці цього селища почуваються про будівництво хімічного заводу. Ви повинні інтерв'ю всіх 100 осіб, право? З них 20% проти, 40% все ще за:
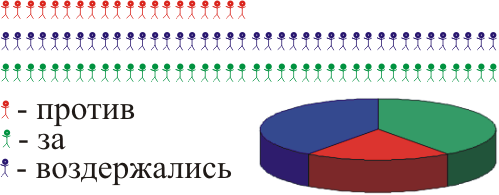
Але ви не можете попросити всіх мешканців, ви не знаєте. Поговоримо про її частину, принаймні половина.
Ми можемо зробити це: розділіть всі села на деякі групи: скажемо, фрілансери, зайняті та неробочі. З кожної групи беруть кілька людей і отримують представницький зразок:
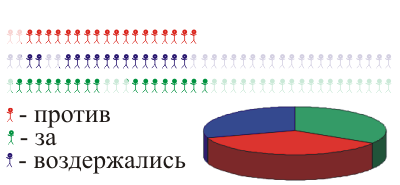 р.
р.
Або ще ми зробимо це по-різному: вони розсіюються в випадковому режимі, який був спійманий і спійманий. Ми підраховуємо половину села, і ми отримали імовірнісний зразок.
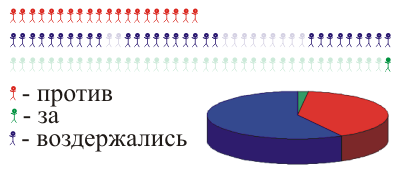 Габаритний зображення
Габаритний зображення
Ви можете зробити щось більш елегантним: з генератором випадкових чисел, ми вибираємо деякі вулиці і перейдіть туди. Ви можете поділити жителів квотами. В цілому ми діємо методами неробочого відбору:
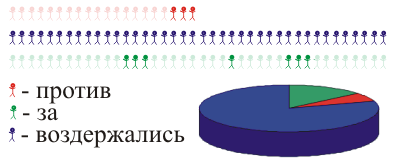 р.
р.
Чи є вони "для", "перевага" або "гайнст"?
У цьому випадку більш-менш очевидний. Але це те, що ми знаємо повний результат. Якщо ми опитуємо більше половини населення, ми можемо вимагати відносно реальних знань. Або ми можемо випити невелику кількість випадково відібраних мешканців багато разів, щоб в цілому ми інтерв'ю кілька разів більше жителів, ніж у селі.
У будь-якому опитуванні необхідно переконатися, що ви інтерв'юєте тих, хто потребує. Наприклад, в разі запилення сексуальної жінки в світі, це не так страшно зробити помилку. Але в будь-якому важливому питанні – наприклад, вибори Президента країни – дуже важливо, щоб вижити тих, хто живе там, психічно здоровий і принаймні живий, від усіх, хто не впаде до цієї категорії. Зробіть всі голоси за себе один раз.
Друга проблема – кількість людей, які проходять співбесіду. Якщо ви займаєтесь середньоєвропейською країною 10 млн осіб, то 1% - 100 000 осіб. Таке опитування паперу практично неможливо.
Відразу бронювання: паперова важка, але електронна легше. Але відразу ж виникає велика проблема, що висихає тих, хто необхідний в опитуванні, і хто не є.
З іншого боку, можна провести надійну паперову опитування таких (і значно більше) населення, але це вимагає величезних зусиль. Класичний приклад – соціологічні опитування, які називають «референдум», «президентські вибори».
І тепер повернувся до реального опитування, яке тут прокоментувало:
25-28 квітня 2014 року на представнику Всеукраїнського зразка міського та сільського населення серед 1,602 осіб віком 18 років та старше 130 населених пунктів 45 областей країни. Розподіл відповідей надається у відсотках загальної кількості респондентів разом з даними попередніх опитувань. Статистична похибка цих досліджень не перевищує 3,4%.
Що я отримую тут?
Які висновки? Я думаю, що це очевидно ...
Чи є Центр Левада так званий безкомпетентний? Ні, це проблема будь-яких опитувань у великих країнах, таких як Росія.
Які інші проблеми існують? Я не повторю її занадто багато – читати велику статтю на тему. Ознайомитися з цією статтею, яка показує кількість приватних та громадських шкіл США:
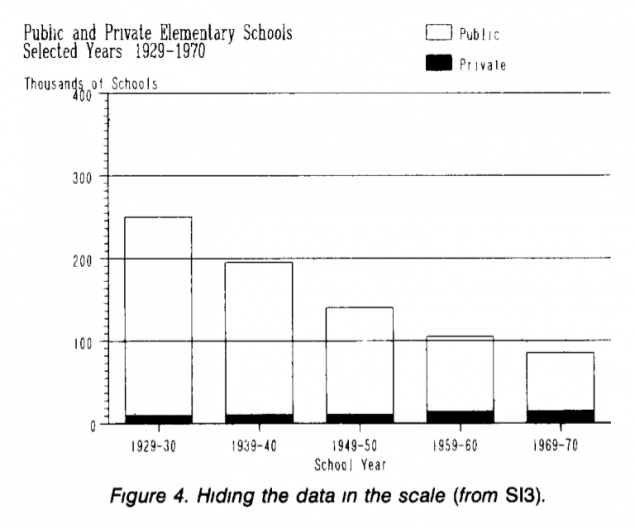
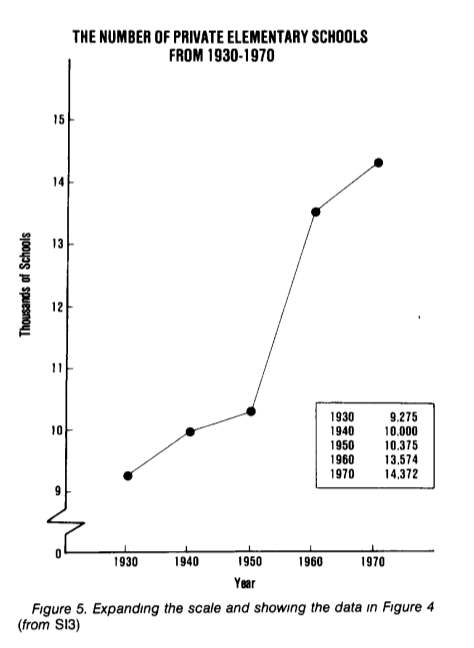
На графіку показано, що державні школи стають меншими, а приватні школи не додаються. Зареєструватися Ми уважно дивимося - і приватні, чорні, стає все більш! Дивитися на графіку, де показано кількість приватних шкіл окремо:
 р.
р.
Красивий, huh?
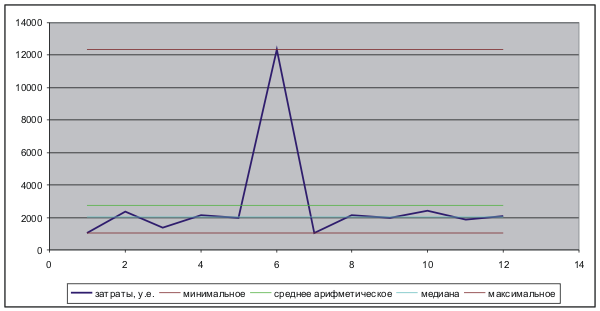
Тепер невеликий приклад від мого особистого життя. Повідомляємо, що у мене є статистика. За минулий рік я мав ці витрати:
Щомісячні витрати, США Січень 1047 Лютий 2354 Березень 1358 Квітень 2123 Травень 1984 Червень 12346 Липень 1023 Серпень 2136 Вересень 1986 Жовтень 2431 Листопад 1856 Грудень 2113 Я хочу мати відкладений розмір, який допоможе мені, якщо мій дохід різко падає. Я вирішив аналізувати таблицю і вирішувати на наступний рік: скільки потрібно зберегти, щоб середня була достатньо? Перше, що я шукаю в липні 1023. Далі я дивитися максимум - червень, 12346. Отже, слід взяти арифметичне значення від мінімального і максимального? Я отримую (1023 +12346) / 2 = 6684. Чи відображає мої витрати? Переміщення.
Якщо ми беремо арифметичне значення всіх місяців, ми отримуємо 2729. Чи відображає мої витрати? Я витрачав менше грошей щомісяця, крім того, я витратив багато більше в червні. Переміщення.
Пам'ятайте, що медіан: грубо кажучи, в розподілі ймовірностей буде посередині. У цьому випадку 2049 р. Половина часу я витратив менше, половина більше. Закрити до фактичного стану справ. Питання: Ви часто бачите медіан в результаті соціологічних досліджень?
Негативний момент обчислення медіану складніше розрахувати, ніж арифметичне значення. Так, але у віці N-core процесорів у телефоні, що аргумент звучить непарно.
Графік відображає ці міркування.
Я думаю, що кожен знайде для себе. Я дізнався, що опитування не відображають реальну громадську думку. На жаль...
Джерело: habrahabr.ru/post/222773/
Причиною написання цієї статті було це дослідження, яке було обговорення раніше.
З моєю вищою технічною освітою та любов’ю точної науки та особливо математики, я оціню та поважати теорії, які застосовні в житті та надавати практичні переваги (всупереч поширеній вірі, що теорія релятивності не має відношення до повсякденного життя, варто вивчити теорію GPS-систем та зйомки ракет на планетарному масштабі). З цієї точки зору ми розглянемо таку частину статистики як соціологічні опитування. Дуже модний.
Давайте подивимося на неї очима людини далеко від формул.
У нас є село, де 100 людей живуть. Ми хочемо дізнатися, як мешканці цього селища почуваються про будівництво хімічного заводу. Ви повинні інтерв'ю всіх 100 осіб, право? З них 20% проти, 40% все ще за:

Але ви не можете попросити всіх мешканців, ви не знаєте. Поговоримо про її частину, принаймні половина.
Ми можемо зробити це: розділіть всі села на деякі групи: скажемо, фрілансери, зайняті та неробочі. З кожної групи беруть кілька людей і отримують представницький зразок:
 р.
р.Або ще ми зробимо це по-різному: вони розсіюються в випадковому режимі, який був спійманий і спійманий. Ми підраховуємо половину села, і ми отримали імовірнісний зразок.
 Габаритний зображення
Габаритний зображенняВи можете зробити щось більш елегантним: з генератором випадкових чисел, ми вибираємо деякі вулиці і перейдіть туди. Ви можете поділити жителів квотами. В цілому ми діємо методами неробочого відбору:
 р.
р.Чи є вони "для", "перевага" або "гайнст"?
У цьому випадку більш-менш очевидний. Але це те, що ми знаємо повний результат. Якщо ми опитуємо більше половини населення, ми можемо вимагати відносно реальних знань. Або ми можемо випити невелику кількість випадково відібраних мешканців багато разів, щоб в цілому ми інтерв'ю кілька разів більше жителів, ніж у селі.
У будь-якому опитуванні необхідно переконатися, що ви інтерв'юєте тих, хто потребує. Наприклад, в разі запилення сексуальної жінки в світі, це не так страшно зробити помилку. Але в будь-якому важливому питанні – наприклад, вибори Президента країни – дуже важливо, щоб вижити тих, хто живе там, психічно здоровий і принаймні живий, від усіх, хто не впаде до цієї категорії. Зробіть всі голоси за себе один раз.
Друга проблема – кількість людей, які проходять співбесіду. Якщо ви займаєтесь середньоєвропейською країною 10 млн осіб, то 1% - 100 000 осіб. Таке опитування паперу практично неможливо.
Відразу бронювання: паперова важка, але електронна легше. Але відразу ж виникає велика проблема, що висихає тих, хто необхідний в опитуванні, і хто не є.
З іншого боку, можна провести надійну паперову опитування таких (і значно більше) населення, але це вимагає величезних зусиль. Класичний приклад – соціологічні опитування, які називають «референдум», «президентські вибори».
І тепер повернувся до реального опитування, яке тут прокоментувало:
25-28 квітня 2014 року на представнику Всеукраїнського зразка міського та сільського населення серед 1,602 осіб віком 18 років та старше 130 населених пунктів 45 областей країни. Розподіл відповідей надається у відсотках загальної кількості респондентів разом з даними попередніх опитувань. Статистична похибка цих досліджень не перевищує 3,4%.
Що я отримую тут?
- Вони інтерв'юли 1,602 осіб. Його населення за результатами Всеукраїнського перепису 2010 р. становить 142 856 536 осіб. Дивид 1602 на 142856536 і отримати 1.1*10-5. Це 0.001 відсотків. Так, за результатами опитування 0,001% росіян, проводиться висновок для всіх росіян.
- Враховуємо, що люди старше 18 років були опитані. Згідно з тими ж результатами, населення у віці 19 становить 28,026,172 осіб, або 19,6%. Всі права, відняти дітей: розділіть 1620 по 114,830,364. Змінено результат: 1.4*10-5. Це 0.0014%. Це велика різниця?
- Проведено опитування в 130 населених пунктах. Суддя за результатами Всеукраїнського перепису 2010 р. Росії є 1,100 міст, 1,285 ПГТ і 153,124 сільських населених пунктів - всього 155,509 населених пунктів. Дивід 130 по 155 509 і отримати 8.4*10-4. Це 0.083%. Таким чином, за результатами опитування, 0,083% населених пунктів укладаються для всіх населених пунктів Росії.
- Дослідження проводилося в 45 регіонах. Сьогодні це 85 регіонів (російська Росія включила Крим). Діду 45 по 85 і отримати 52 відсотків. Так, за результатами опитування половини регіонів Росії, наведено висновок для всіх регіонів.
- «Статистична помилка» – що це? Про що?
Які висновки? Я думаю, що це очевидно ...
Чи є Центр Левада так званий безкомпетентний? Ні, це проблема будь-яких опитувань у великих країнах, таких як Росія.
Які інші проблеми існують? Я не повторю її занадто багато – читати велику статтю на тему. Ознайомитися з цією статтею, яка показує кількість приватних та громадських шкіл США:

На графіку показано, що державні школи стають меншими, а приватні школи не додаються. Зареєструватися Ми уважно дивимося - і приватні, чорні, стає все більш! Дивитися на графіку, де показано кількість приватних шкіл окремо:
 р.
р.Красивий, huh?
Тепер невеликий приклад від мого особистого життя. Повідомляємо, що у мене є статистика. За минулий рік я мав ці витрати:
Щомісячні витрати, США Січень 1047 Лютий 2354 Березень 1358 Квітень 2123 Травень 1984 Червень 12346 Липень 1023 Серпень 2136 Вересень 1986 Жовтень 2431 Листопад 1856 Грудень 2113 Я хочу мати відкладений розмір, який допоможе мені, якщо мій дохід різко падає. Я вирішив аналізувати таблицю і вирішувати на наступний рік: скільки потрібно зберегти, щоб середня була достатньо? Перше, що я шукаю в липні 1023. Далі я дивитися максимум - червень, 12346. Отже, слід взяти арифметичне значення від мінімального і максимального? Я отримую (1023 +12346) / 2 = 6684. Чи відображає мої витрати? Переміщення.
Якщо ми беремо арифметичне значення всіх місяців, ми отримуємо 2729. Чи відображає мої витрати? Я витрачав менше грошей щомісяця, крім того, я витратив багато більше в червні. Переміщення.
Пам'ятайте, що медіан: грубо кажучи, в розподілі ймовірностей буде посередині. У цьому випадку 2049 р. Половина часу я витратив менше, половина більше. Закрити до фактичного стану справ. Питання: Ви часто бачите медіан в результаті соціологічних досліджень?
Негативний момент обчислення медіану складніше розрахувати, ніж арифметичне значення. Так, але у віці N-core процесорів у телефоні, що аргумент звучить непарно.
Графік відображає ці міркування.

Я думаю, що кожен знайде для себе. Я дізнався, що опитування не відображають реальну громадську думку. На жаль...
Джерело: habrahabr.ru/post/222773/























