Жизнь — интересная!
Подписывайтесь на нашу группу в Telegram и Facebook, чтобы быть в сообществе единомышленников, находить вдохновение и не пропускать свежие и удивительные статьи с bashny.net.
1370
0.3
2014-05-15
Насколько можно доверять социологическим исследованиям?

Поводом написания этой статьи послужило это исследование, которое обсуждалось ранее.
С моим высшим техническим образованием и любовью к точным наукам и особенно к математике, я ценю и уважаю те теории, которые применимы в жизни и дают практическую пользу (вопреки распространенному мнению, что теория относительности отношения к повседневной жизни не имеет, стоит изучить теорию GPS-систем и стрельбу ракетами в масштабах целой планеты). Давайте с этой точки зрения посмотрим на такую часть статистики как социологические опросы. Сейчас они очень модны.
Постараемся посмотреть на это глазами далекого от формул человека.
Интуитивное понимание
У нас есть деревушка, где живут 100 человек. Мы хотим выяснить как относятся жители этой деревушки к постройки у них хим. завода. Для этого надо опросить всех 100 человек — правильно? Из них 20% против, 40% все равно, 40% за: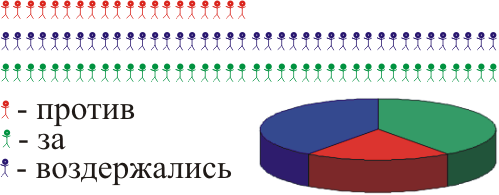
Но вот — всех жителей не опросишь, не узнаешь. Давайте тогда опросим какую-то часть — хотя бы половинку.
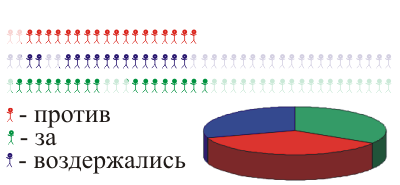
Можно поступить так: разделим всех жителей деревни на какие-то группы: скажем, фрилансеры, работающие по найму и не-работающие. Из каждой группы возьмем по нескольку человек и получим репрезентативную выборку:
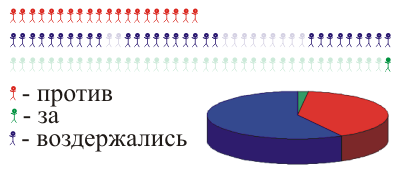
Или же поступим иначе: разошлись наугад, кого поймали, того и поймали. Насчитали половину деревни — и порядок, получили вероятностную выборку:
Можно поступить элегантнее: генератором случайных чисел отбираем какие-то улицы и идем туда. Можно еще по квотам разделить жителей. В общем, действуем методами невероятностной выборки:
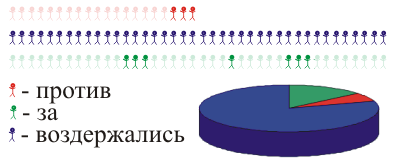
Так все-таки — жители «за», «воздержались» или «против»???
В данном случае оно более-менее очевидно. Но это потому что мы знаем полный результат. Если мы опросим более половины жителей, то мы тоже можем претендовать на относительно реальное знание. Или же мы можем опрашивать небольшое количество случайно выбранных жителей много раз — так, что в сумме мы опросим в несколько раз больше жителей, чем их есть в деревне.
Общая проблема социологических опросов
В любом опросе надо быть уверенным, что опросили тех, кого нужно. Скажем, в случае опроса наиболее сексуальной женщины мира не так уж и страшно ошибиться. Но в любом важном вопросе — например, выборы президента страны — очень важно отсеивать тех, кто там живет, психически здоров и как минимум жив, от всех тех, кто не попал в эту категорию. Также нужно быть уверенным, что каждый проголосовал за себя один раз.Вторая проблема — количество людей, которое надо опросить. Если взять среднюю европейскую страну в 10 млн человек, то 1% — это 100 000 человек. Такой опрос провести бумажным способом практически нереально.
Сразу оговорки: бумажным тяжко, а вот электронным проще. Но сразу же возникает большая проблема отсеивания тех, кто нужен в опросе, и кто не нужен.
С другой стороны, достоверный бумажный опрос такой (и значительно большей) численности населения провести можно, но это требует колоссальных усилий. Классический пример — социологические опросы под названием «референдум», «президентские выборы».
Опрос от Левада-центра
А теперь вернемся к реальному опросу, который прокомментирован тут:Опрос проведен 25-28 апреля 2014 года по репрезентативной всероссийской выборке городского и сельского населения среди 1602 человека в возрасте 18 лет и старше в 130 населенных пунктах 45 регионов страны. Распределение ответов приводится в процентах от общего числа опрошенных вместе с данными предыдущих опросов. Статистическая погрешность данных этих исследований не превышает 3,4%
Что я отсюда навскидку понял?
- Опросили 1602 человека. Ее население по результатам всероссийской переписи населения 2010 года составляет 142 856 536 человека. Делим 1602 на 142856536 и получаем — 1.1*10-5. Это 0.001%. Значит, по результатам опроса 0.001% россиян делается вывод по всем россиянам.
- Учитываем, что опрашивали людей старше 18 лет. По тем же результатам жителей до 19 лет составляет 28 026 172 человек, или 19.6%. Хорошо, вычтем детей: делим 1620 на 114 830 364. Результат изменился: 1.4*10-5. Это 0.0014%. Разница существенная?
- Опрос провели в 130 населенных пунктах. Судя по итогам всероссийской переписи населения 2010 года России в ней насчитывается 1100 городов, 1285 ПГТ и 153124 сельских населенных пунктов — итого 155 509 населенных пунктов. Делим 130 на 155 509 и получаем 8.4*10-4. Это 0.083%. Значит, по результатам опроса в 0.083% населенных пунктах делается вывод по всем населенным пунктам России.
- Опрос был проведен в 45 регионах. На сегодняшний день это 85 региона (сюда Россия включила Крым). Делим 45 на 85 и получаем 52%. Значит, по результатам опроса половины регионов России делается вывод по всем регионам.
- «Статистическая погрешность...» — какая именно? Относительно чего?
Какие тут следуют выводы? Думаю, это очевидно…
Это что, Левада-центр такой злой некомпетентный? Нет, это беда любых опросов в таких больших странах, как Россия.
Какие есть еще проблемы?
Не буду сильно повторяться — прочитайте прекрасную статью на эту тему. Для затравки гляньте на график из той статьи, который показывает количество частных и публичных школ в США: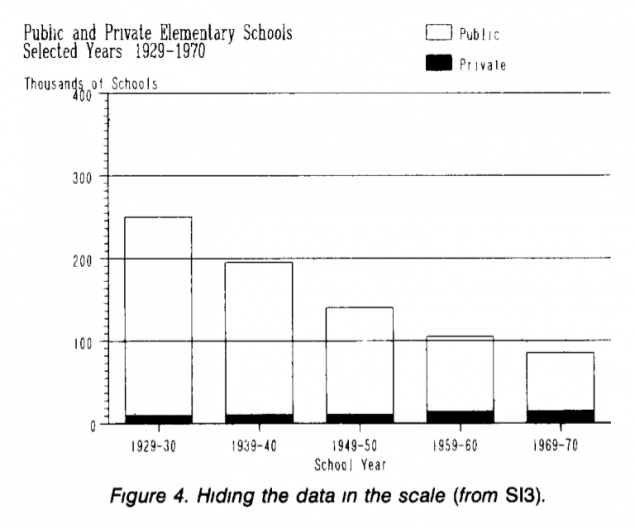
Из графика видно, что публичных школ становится все меньше, да и частных не прибавляется… Стоп! Смотрим внимательно — а частных-то, черных, становится больше! Смотрим на график, где количество частных школ показано отдельно:
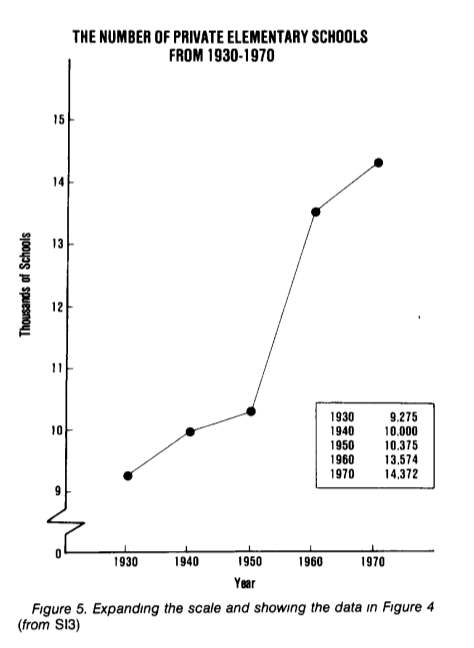
Красиво, да?
Теперь небольшой пример из личной жизни. Допустим, я веду статистику своих расходов. За год у меня получились такие расходы:
| месяц | расходы, у. е. |
|---|---|
| январь | 1047 |
| февраль | 2354 |
| март | 1358 |
| апрель | 2123 |
| май | 1984 |
| июнь | 12346 |
| июль | 1023 |
| август | 2136 |
| сентябрь | 1986 |
| октябрь | 2431 |
| ноябрь | 1856 |
| декабрь | 2113 |
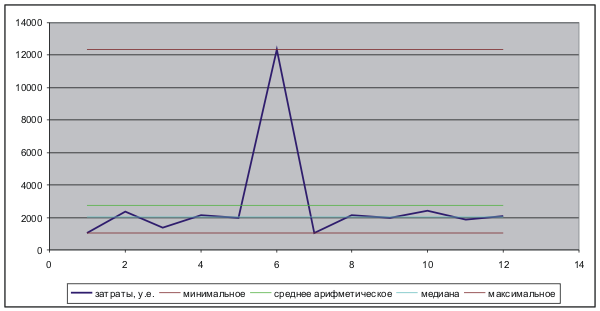
Посмотрим иначе — возьмем среднее арифметическое от всех месяцев — получим 2729. Это что, отражает мои траты? Каждый месяц я тратил меньше денег, вот разве что в июнь потратился значительно больше. Преувеличено.
Вспомним о медиане: грубо говоря, в распределении вероятностей это будет посередке. В данном случае это 2049. В половине случаем я тратил меньше, в половине больше. Ближе всего к реальному положению дел. Вопрос — часто ли вы в социологических опросах встречали как результат медиану?
Отрицательный момент расчета медианы — ее считать сложнее, чем среднее арифметическое. Ага, но в век n-ядерных процессоров в телефоне этот довод звучит странно.
На графике отражены эти рассуждения.
Выводы
Думаю, тут каждый решит для себя сам. Лично я понял, что социологические опросы не отражают реальное общественное мнение. К сожалению…Источник: habrahabr.ru/post/222773/
Портал БАШНЯ. Копирование, Перепечатка возможна при указании активной ссылки на данную страницу.