1228
Логіка мислення. Зареєструватися 2. Фактори
 доб.
доб.У попередній частині ми описали найпростіші властивості формальних нейронів. Ми говорили про те, що поріговий дозатор більш точно відтворює природа однієї спилки, а лінійний дозатор дозволяє імітувати відповідь нейрона, що складається з серії імпульсів. Показано, що значення при виході лінійного додатка можна порівняти з частотою викликаних походів реального нейрона. Тепер ми розглянемо основні властивості, які ці формальні нейрони мають.
Фільтр Hebb
Далі ми часто звертаємось до моделей нейромереж. В принципі практично всі основні поняття теорії нейромереж безпосередньо пов'язані з структурою реального мозку. Людина, яка зіткнулася з певними завданнями, придумала багато цікавих нейромережних конструкцій. Еволюція, розсіявши всі можливі нейронні механізми, вибрав все, що доведено в неї корисну. Для багатьох моделей людини можна знайти чіткі біологічні прототипи. З моменту свого наратив не спрямований на будь-яку детальну експозицію теорії нейромереж, ми доторкнемося лише на найбільш поширених точках, необхідні для опису основних ідей. Для більш глибокого розуміння я дуже рекомендую звернутись до спеціальної літератури. Для мене найкращий підручник з нейронних мереж Саймон Гайкін. Повний курс" (Хайкін, 2006).
Багато моделей нейромереж базуються на добре відомому правилоі навчання Hebb. Пропонував фізіолог Дональд Хеббб в 1949 році (Хеб, 1949). У злегка розпушувачі вона має дуже простий зміст: з'єднання нейронів, які активуються разом, повинні бути посилені, з'єднання нейронів, які запускаються самостійно, повинні бути ослаблені.
Вихідний стан лінійного додатка може бути написаний:
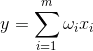
Якщо ми ініціювали початкові значення ваг у невеликих кількостях і подаємо різні зображення в вхід, то нічого не заважає нам намагатися навчати цей нейрон за правилом Хебб:
де n є дискретним кроком в часі, є параметром швидкості навчання.
З цією процедурою ми збільшимо вагу вводів, до яких відправляється сигнал, але робимо це більш сильно активніше реакція самого тренованого нейрона. Якщо немає відповіді, немає ніякого навчання.
Однак, такі ваги виростуть невизначено, тому можна застосувати нормалізацію для стабілізатора. Наприклад, розділіть по довжині вектора, отриманого від «нових» сиптичних ваг.
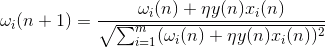
З цим навчанням ваги перерозподілені між снапами. Полегше розуміти сутність перерозподілу, якщо слідувати зміні ваги в двох кроках. В першу чергу, коли нейрон активно працює, доповнюється синопси, які отримують сигнал. Вага знімків без сигналу залишається незмінною. Загальний раціон, потім зменшує вагу всіх знімків. Але без сигналів втратить попереднє значення, і спринци з сигналами перерозподіляють ці втрати серед себе.
Правило Hebb нічого більше, ніж виконання методу градієнтного спуску на поверхні помилки. По суті, ми робимо нейронну корекцію до сигналів, які надсилаються, змінюючи її вагу кожного разу в напрямку навпроти помилки, тобто в напрямку антиградієнту. Для того, щоб градієнтний спуск, щоб привести нас до місцевого екстремального без проходження його, швидкість спуску повинна бути досить невеликою. Що в Hebbian навчання враховується невеликістю параметра.
Невеликість параметра швидкості навчання дозволяє переписати попередню формулу у вигляді серії:
Якщо ви відмовляєтеся від другого порядку та вище умов, ви отримуєте правило навчання Оя (Оя, 1982):
Позитивна добавка відповідає за навчання Hebb та негативне доповнення відповідає за загальну стійкість. Запис в даній формі дозволяє відчути, як таке тренування може бути реалізована в аналоговому середовищі без використання розрахунків, що працюють тільки з позитивними і негативними з'єднаннями.
Тепер, таке надзвичайно просте тренування має дивовижну властивість. Якщо ми поступово знизимо курс навчання, то вага знімків навчального нейрона буде конвержуватися до таких значень, що його вихід починає відповідати першому основного компоненту, який буде отримано, якщо ми застосовували відповідні процедури для аналізу основних компонентів до даних, що поставляються. Цей дизайн називається фільтром Hebb.
Наприклад, ми додаємо піксельну картину до введення нейрона, тобто ми порівняємо одну точку зображення до кожного синапсу нейрона. Ми подаємо лише два зображення в нейронний вхід – зображення вертикальних і горизонтальних ліній, що проходять через центр. Один крок навчання - один образ, один рядок, або горизонтальний або вертикальний. Якщо ви середні ці зображення, ви отримаєте хрест. Але результат навчання не буде схожим. Це одна з ліній. Те, що буде більш поширеним у представлених образах. Невронь виділить не пересуватися або перетинати, але точки, які найчастіше зустрічаються разом. Якщо зображення більш складні, результат не може бути таким очевидним. Але це завжди буде основним компонентом.
Навчання нейрона призводить до того, що виділено певну картину (фільтровано) на її масштабах. Коли надіслав новий сигнал, то більш точно відповідає сигналу та налаштування масштабу, чим вище відповідь нейрона. Учбовий нейрон можна назвати детектором нейрона. При цьому образ, який описується його масштабами, називається характерним стимулом.
Основні компоненти
Дуже ідея методу компонента принципу проста і винахідлива. Ми маємо послідовність подій. Ми описуємо кожен з них через його вплив на датчики, з якими ми сприймаємо світ. Повідомляємо, що у нас є сенсори, які описують ознаки. Всі події для нас описані векторами виміру. Кожен компонент такого вектора вказує значення відповідної функції. Разом вони утворюють випадкову кількість. Рй Ми можемо зображувати ці події як точки в об'ємному просторі, де будуть розглянуті ознаки.
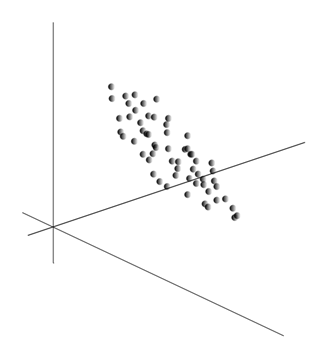
Цінності вилучення дають математичне очікування випадкового значення Р, знежирений як E()Р). Якщо ми зберігаємо дані так, що E()Р) = 0, точна хмара буде зосереджена навколо походження координат.
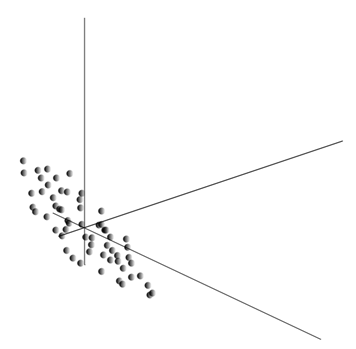
Ця хмара може бути розтягнута в будь-якому напрямку. Після того, як намагатися всіх можливих напрямків, ми можемо знайти одну, разом з якою буде максимальна варіантність даних.
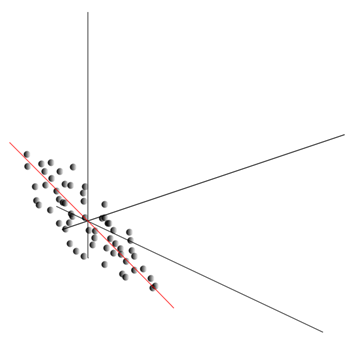
Отже, цей напрямок відповідає першому основного компоненту. Головний компонент визначається одним вектором, який виходить з походження координат і збігається з цим напрямком.
Далі ми можемо знайти ще один напрямок перпендикулярно першому компоненту, наприклад, вздовж нього варіант також максимальний серед всіх перпендикулярних напрямків. Коли ми знайдемо його, ми отримуємо другий компонент. Ми можемо продовжити пошук, запитуючи себе, що шукати серед напрямків перпендикулярно компонентам вже знайдено. Якщо початкові координати були лінійно незалежними, то ми можемо зробити це один раз до об'ємності космічних кінців. Таким чином, ми отримуємо міжконтинентальні компоненти, що замовляється від відліку даних, які вони пояснюють.
Природно, основні компоненти, отримані від відображають внутрішні візерунки наших даних. Але існують прості характеристики, які також описують сутність існуючих шаблонів.
Припустимо, що у нас немає заходів. Кожен захід описаний вектором. Складові цього вектора:
Для кожної функції можна записувати, як проявляється вона в кожній з подій:
Для будь-яких двох особливостей, на яких ґрунтується опис, можна розрахувати значення, що показує ступінь їх прояву суглоба. Це значення називається covariance:
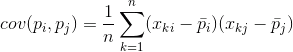
Наведено, як відхилення від середньої величини одного з ознак збігаються при виявленні аналогічних відхилень іншої риси. Якщо середні значення особливостей нульові, то коваріант приймає форму:
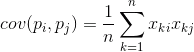
Якщо виправити коваріантність стандартних відхилень, характерних для рис, ми отримуємо лінійний коефіцієнт кореляції, також називається коефіцієнтом кореляції Пірсона:
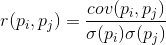
Коефіцієнт кореляції має чудове майно. До 1. Крім того, 1 вказує на пряму пропорційність двох значень, а -1 вказує на їх зворотну лінійну залежність.
З усіх парних співваріацій рис можна зробити матрицю зварювальним, що, як можна легко побачити, є математичним очікуванням продукту:
Далі ми припустимо, що наші дані нормалізуються, тобто мають єдиний варіант. У цьому випадку матриця кореляції збігається з матрицею коваріантності.
Так виходить, що для основних компонентів це правда:
Це, основні компоненти, або як вони називають, фактори є одержувачами матриці кореляції. Вони відповідають своїм числам. У той же час, чим більше належного числа, тим більший відсоток варіанту пояснює цей фактор.
Знаючи всі основні компоненти для кожної події, яка є реалізацією РВи можете написати проекції на основних складових:
Таким чином, можна представити всі початкові події в нових координатах, координати основних компонентів:
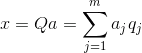
В цілому ми розрізняємо процедуру пошуку основних компонентів і процедури пошуку основи чинників і її подальшого обертання, що полегшує інтерпретацію факторів, але так як ці процедури є ідеологічно закритими і дають аналогічний результат, ми будемо називати як факторний аналіз.
За досить простою процедурою факторного аналізу є дуже глибоке значення. Справа в тому, що якщо простір початкових ознак є спостережним простором, то чинники є ознаками, які, хоча вони описують властивості навколишнього світу, але в цілому (якщо вони не збігаються з зазначеними ознаками) приховані особи. Це, формальна процедура факторного аналізу дозволяє нам рухатися від явищ, що спостерігаються до виявлення явищ, хоча безпосередньо невидимі, але не менш існуючі в навколишньому світі.
Ми можемо самі зателефонувати одержувачу і узгодити зручний час і місце вручення квітів, а якщо необхідно, то збережемо сюрприз. Ми можемо самі зателефонувати одержувачу і узгодити зручний час і місце вручення квітів. Основою цих нових описів є вираз у подіях тих явищ, які відповідають вибраним факторам.
Розкажіть трохи про фактори на рівні домогосподарств. Покажіть, що ви є менеджером з управління персоналом. Багато людей приходять до вас, і ви заповнюєте певну форму для кожної людини, де ви пишете різні спостережні дані про відвідувача. Після перегляду ваших записів ви можете знайти, що деякі графіки мають певні стосунки. Наприклад, стрижки у чоловіків будуть коротшими в середньому, ніж у жінок. Важко зустрітися тільки серед чоловіків, і тільки жінки пофарбують губи. Якщо ви застосовуєте факторний аналіз на особисті дані, то ґендер буде одним із чинників, що пояснюють кілька шаблонів одночасно. Але факторний аналіз дозволяє знайти всі фактори, які роз’ясовують кореляційні залежності в даних. Це означає, що крім секс-фактора, який ми можемо спостерігати, інші, включаючи імпліцит, незбережені фактори, виділяється. І якщо ґендер явно з'явиться в анкеті, то ще один важливий фактор залишиться між лініями. Оцінювання здатності людей висловлювати свої думки, оцінити їх кар’єрний успіх, аналізувати свої оцінки у дипломі та аналогічні знаки, ви прийдете до висновку, що є загальна оцінка людського інтелекту, яка явно не записана в анкеті, але що пояснює багато його точок. Оцінка інтелекту є прихованим чинником, основним компонентом з високою пояснювальним ефектом. Очевидно, що ми не дотримуємося цього компонента, але ми записуємо знаки, які пов'язані з ним. З досвідом життя ми можемо підсвідомо сформувати ідею інтелекту співрозмовника. Процедура, яка використовує мозок, фактично, аналіз факторів. Спостерігаючи, як з'являються певні явища, мозок, використовуючи формальну процедуру, визначає чинники як відображення стабільних статистичних закономірностей, характерних для світу.
Визначення комплексу факторів
Ми показали, як фільтр Hebb виділяється першим великим компонентом. Виявляється, за допомогою нейромереж ви можете легко отримати не тільки перший, але і всі інші компоненти. Це можна зробити, наприклад, таким чином. Повідомляємо, що у нас є вхідні знаки. Візьміть лінійні нейрони, де.
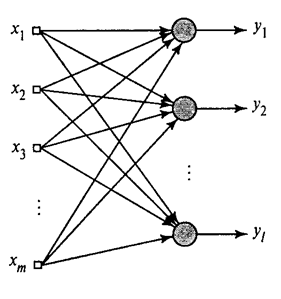
Генеалізовані алгоритми Hebb (Хайкін, 2006)
Ми будемо навчати перший нейрон як фільтр Hebb, так що він може ізолювати перший основний компонент. Але кожен наступний нейрон буде навчатися на сигналі, з якого ми виключаємо вплив всіх попередніх компонентів.
Діяльність нейронів в степу n визначається як
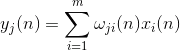
Корекція до синоптичних мас, як
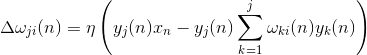
де 1 і 1 до .
Для всіх нейронів це схоже на навчання, схожу на фільтр Hebb. Єдина відмінність полягає в тому, що кожен наступний нейрон не бачить весь сигнал, але тільки те, що попередні нейрони не бачили. Цей принцип називається reassessment. Насправді, використовуючи обмежений набір компонентів, ми відновлюємо оригінальний сигнал і робимо наступний нейрон див. тільки решта, різниця між оригінальним сигналом і відновленим сигналом. Цей алгоритм називається узагальненим алгоритмом Hebb.
Узагальнений алгоритм Hebb не повністю хороший при занадто обчисленні. Нейрони повинні бути замовлені, і їх продуктивність повинні бути вимірювані послідовно. Це не дуже послідовно з принципами кори головного мозку, де кожен нейрон, хоча взаємодіяти з відпочинком, але працює автономно, і де не виражений «центральний процесор», який визначить загальну послідовність подій. З таких міркувань алгоритми, які називають алгоритмами декорації, виглядають дещо більш привабливими.
Уявіть, що у нас є два шари нейронів Z1 і Z2. Діяльність нейронів першого шару формує певну картину, яка проводиться по осях до наступного шару.
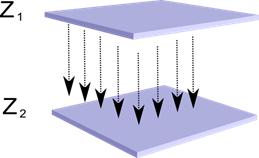
проекція одного шару на інший
Тепер уявіть, що кожен нейрон другого шару має синоптичні з'єднання з усіма осями, що надходять з першого шару, якщо вони потрапляють в межі певного мікрорайону цієї нейрони (рис. нижче). Аксони, які потрапляють в таку область, утворюють рецептивне поле нейрона. Рецепторне поле нейрона полягає в тому, що фрагмент загальної активності, яка доступна для його спостереження. Все інше для цього нейрона просто не існує.
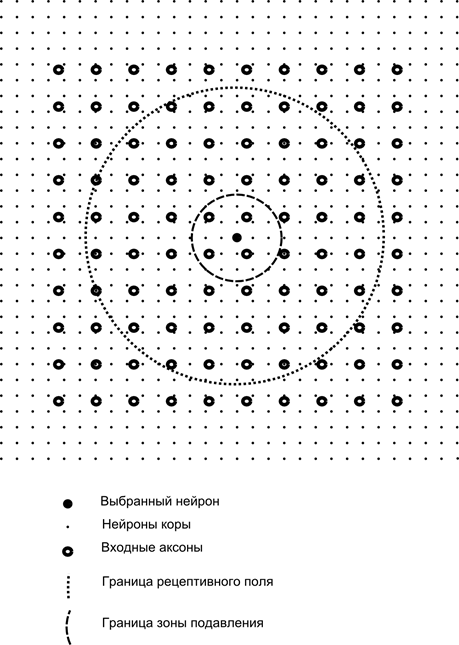 р.
р.Крім рецептивного поля нейрона ми введемо трохи меншу область, що викликаємо зону пригнічення. Ми збираємося підключати кожну нейрон до своїх сусідів в цій області. Такі з'єднання називають бічними або, після закінчення термінології, прийнятої в біологіях, бічні. Знижувати інгібітори бічних з'єднань, тобто зменшити активність нейронів. Логіка їх роботи полягає в тому, що активна нейрона гальмує активність всіх нейронів, які потрапляють в зону гальмування.
З'єднання збудників і інгібіторів можуть бути розподілені строго з усіма аксонами або нейронами в межах відповідних регіонів, і може бути надана випадковим чином, наприклад, з щільною начинкою певного центру і доцільним зниженням щільності з'єднань, як ви відходите від нього. Тверда начинка легше моделювати, випадковий розподіл є більш анатомічними з точки зору організації з'єднань в реальному корі.
Функція нейронної активності може бути записана:
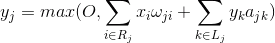
де є остаточна активність, набір аксонів, що потрапляють в рецептивну область вибраного нейрона, набір нейронів в пригнічну зону якої вибирається нейронна пада, сила відповідної заборони, що вживають негативні значення.
Ця функція діяльності є рекурсивною, оскільки активність нейронів залежить від одного. Це призводить до того, що практичний розрахунок проводиться ітеративно.
Навчання сиптичних ваг здійснюється аналогічно до фільтра Hebb:
Збільшуючи гальмування нейронів «сіміляра»:
Суть даної конструкції полягає в тому, що підготовка Hebbian повинна призвести до виділення значень на вагах нейрона, що відповідають першим основним фактором, характерним для даних, що надавалися. Але нейрон може тільки навчитися в напрямку фактора, якщо він активний. Коли нейрон починає випускати фактор і, відповідно, реагувати на нього, починає блокувати активність нейронів, що входять до зони пригнічення. Якщо кілька нейронів вимагають активувати, то взаємний конкурс призводить до того, що найсильніший нейрон перемагає, пригнічує всіх інших. Інші нейрони не мають вибору, але щоб дізнатися, коли немає сусідів з високою активністю. Таким чином, відбувається декорування, тобто кожен нейрон в межах регіону, розмір якого визначається розмірами зони пригнічення, починає виділяти свій фактор, ортогінал для всіх інших. Цей алгоритм називається Адаптивним основним компонентом Вилучення Алгоритм (APEX) (Кунг С., Діамантарас К.І., 1990).
Ідея бічного гальмування близько в дусі до відомого принципу «виграє все» з різних моделей, що також дозволяє декорувати площу, в якій затребуваний переможець. Цей принцип використовується, наприклад, в Фукушіма неогнітітроні, самоорганізаційні карти Коханена, а також застосовується в тренінгу відомого ієрархічного часового пам'яті Джеффа Hawkins.
Переможець може бути визначений простим порівнянням активності нейронів. Але такий пошук, легко реалізований на комп'ютері, дещо не відповідає аналогам з реальною корою. Але якщо ви встановите мету, щоб зробити все на рівні взаємодії нейронів без залучення зовнішніх алгоритмів, то такий же результат можна досягти, якщо крім бічної пригнічення сусідів, нейрон матиме позитивний зворотний зв'язок, що збуджує його. Дана методика пошуку переможця використовується, наприклад, в мережах адаптивного резонансу Grossberg.
Якщо ідеологія нейромережі дозволяє це, то дуже зручно використовувати правило «віннера», так як набагато простіше шукати максимальну активність, ніж ітеративно розрахувати активність з урахуванням взаємного гальмування.
Час, щоб закінчити цю частину. Виявилося досить довго, але я дійсно не хочу розірвати пов'язані оповіді. Не дивиться CDPV, ця картина була пов'язана для мене з штучним інтелектом і основним фактором.
Продовження
Література використана
Частина 1. нейрон
Олексій Редозув (2014)
Джерело: habrahabr.ru/post/214241/























Логіка мислення. Зареєструватися 1. нейрон
Логіка мислення. Зареєструватися 3. Перцептрон, забруднювальні мережі