1233
La lógica de pensamiento. Parte 2 Factores

El sección anterior, hemos descrito las propiedades más básicas de las neuronas formales. Pronunciadas que unidad sumadora umbral reproduce con precisión la naturaleza de la espiga, y combinador lineal puede simular una respuesta de la neurona que consiste en una serie de pulsos. Se demostró que el valor de la salida del combinador lineal puede ser comparado con la frecuencia de picos causados por el verdadero neurona. Ahora nos fijamos en las propiedades básicas, que tienen este tipo de neuronas formales.
Filtra Hebb
A continuación, vamos a menudo se refieren a modelos de redes neuronales. En principio, la casi totalidad de los conceptos básicos de la teoría de redes neuronales están directamente relacionados con la estructura real del cerebro. El hombre frente a ciertos desafíos, red neuronal inventó muchos diseños interesantes. La evolución, a través de todos los posibles mecanismos neuronales que se llevaron todo lo que era muy útil para ella. No es de extrañar que tantos modelos, ideados por el hombre, es posible encontrar una clara prototipos biológicos. A medida que nuestra historia no pretende incluso como una exposición detallada de la teoría de redes neuronales, tocamos sólo las características más comunes que se necesitan para describir las ideas básicas. Para una mejor comprensión, le recomiendo que recurrir a la literatura. Para mí el mejor libro de texto sobre redes neuronales - es Las redes neuronales Simon Haykin ". Curso completo "(Haykin, 2006).
En el corazón de muchos modelos de redes neuronales es una regla de aprendizaje Hebb bien conocido. Se sugirió fisiólogo Donald Hebb en 1949 (Hebb, 1949). En un poco de interpretación de estilo libre, tiene un significado muy simple: la conexión de las neuronas se activan conjuntamente, debe fortalecerse, las neuronas debido desencadenados independientemente, debe desaparecer
. El estado de la salida del combinador lineal puede ser escrito:
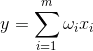
Si iniciamos los valores iniciales de los pesos de pequeñas cantidades, y vamos a solicitar una variedad de imágenes de entrada, entonces nada nos impide tratar de entrenar esta neurona por la regla de Hebb:
donde n em> - un paso discreto a la vez -. ajuste de la velocidad del aprendizaje
Tal procedimiento, que aumentar el peso de la entrada, que se señala, pero lo hace más fuerte es la actividad de reacción de la neurona aprendiz. Si no hay reacción se produce a continuación y la formación.
Sin embargo, estos pesos crecerá indefinidamente, por lo que se pueden aplicar para la estabilización de la normalización. Por ejemplo, para dividir la longitud del vector derivado de los "nuevos" pesos sinápticos.
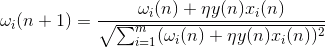
Con esta formación es una redistribución del equilibrio entre las sinapsis. Entender la redistribución más fácil si la pantalla cambian en el saldo en dos cuotas. En primer lugar, cuando la neurona está activo, esos sinapsis, que recibe un aditivo señal obtenida. Los pesos de las sinapsis sin señal se mantienen sin cambios. Entonces, la normalización global reduce el peso de todas las sinapsis. Pero al mismo sinapsis sin perder la señal en comparación con su valor anterior, y las sinapsis para redistribuir señales entre estas pérdidas.
Regla de Hebb es otra cosa que la aplicación del método del descenso más agudo en un error de superficie. De hecho, hacemos una melodía neurona a cabo "señales, cada vez cambiando su peso en el error opuesto, es decir, en la dirección antigradient. Para descenso de gradiente nos trajo a un extremo local, que no se resbale, la velocidad de descenso debe ser lo suficientemente pequeña. ¿Qué aprendizaje de Hebb se tiene en cuenta la pequeñez del parámetro.
La pequeñez del parámetro de tasa de aprendizaje le permite reescribir la fórmula anterior en forma de una serie:
Si rechazamos los términos de segundo orden y, sobre, conseguir la formación adecuada Oia (Oja, 1982):
Agente positivo responsable del aprendizaje de Hebb, y negativo para la estabilidad general. Escritura de esta manera permite que usted se sienta como esta formación se puede implementar en un entorno analógico sin el uso de los cálculos, sólo en términos de conexiones positivas y negativas.
Por lo tanto, un entrenamiento muy sencilla tiene una maravillosa propiedad. Si gradualmente reducimos la velocidad de aprendizaje, los pesos sinapsis neuronales alumno convergen a valores tales que su producción empieza a corresponder al primer componente principal, que se obtendría si se utilizaron los datos suministrados a los procedimientos de análisis de componentes principales. Este diseño se llama un filtro de Hebb.
Por ejemplo, proporcionará la imagen de píxeles neurona de entrada que es comparable a cada neurona sinapsis un punto de la imagen. Vamos a aplicar a la neurona de entrada sólo dos de la imagen - la imagen de líneas verticales y horizontales que pasan por el centro. Un paso de la formación - una sola imagen, una sola línea, ya sea horizontal o verticalmente. Si se promedian estas imágenes, atravesará. Pero el resultado de la formación no será como promedio. Esta es una de las líneas. El que se encuentran más a menudo en las imágenes presentadas. Neurona proporcionar sin promedio o de cruce, y esos términos que a menudo se presentan juntas. Si las imágenes son más complejos, el resultado puede no ser tan visual. Pero siempre será un componente importante de la misma.
Neurona Educación lleva al hecho de que su saldo se asigna (filtro) forma segura. Cuando se aplica una nueva señal, más precisa será la señal de coincidencia y ajustar el balance, mayor es la respuesta de la neurona. Formado neurona puede ser llamado neurona-detector. La imagen, que es descrito por sus pesos, llamado estímulo característica.
Los principales componentes
La idea del método de componentes principales es sencillo e ingenioso. Supongamos que tenemos una secuencia de eventos. Cada uno de ellos nos describen a través de su influencia en el sensor, que percibimos el mundo. Supongamos que tenemos sensores, describiendo características. Todos los eventos para nosotros para describir la dimensión de los vectores. Cada componente de este vector indica el valor del atributo i-ésimo correspondiente. Juntos, forman una variable aleatoria X em>
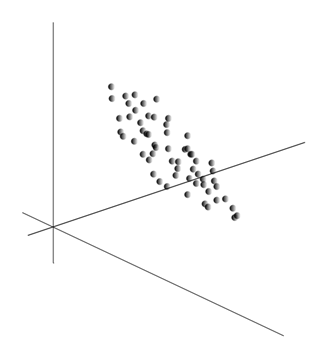
Promediando los valores da la expectativa de una variable aleatoria X , denominado E ( X ). Si nos centramos los datos para que E ( X ) = 0, la nube de puntos se concentrarán alrededor del origen.
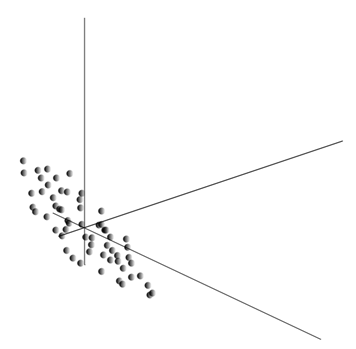
Esta nube se puede estirar en cualquier dirección. Después de haber probado todas las direcciones posibles, podemos encontrar a lo largo de la cual la varianza de los datos será máxima.
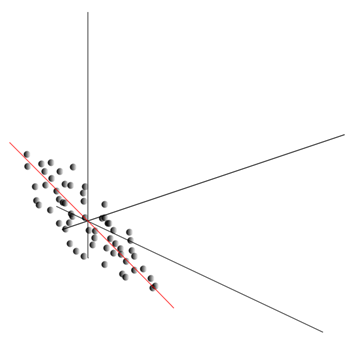
Por lo tanto, esta dirección corresponde a la primera componente principal. El componente muy principal se determina por el vector unitario que emana desde el origen y coincide con esta dirección.
Además, podemos encontrar otra dirección perpendicular a la primera componente, tal que la dispersión a lo largo también era el más alto entre todas las direcciones perpendiculares. Después de encontrarlo, se obtiene el segundo componente. Entonces podremos continuar la búsqueda, especifique las condiciones que deben buscarse entre las direcciones perpendiculares a los componentes ya encontrados. Si las coordenadas originales eran linealmente independientes, por lo que podemos actuar de nuevo hasta el final de la dimensión del espacio. De este modo, se obtiene un componente A mutuamente organizado por el porcentaje de variación de datos, explican.
Naturalmente, los componentes principales obtenidos reflejan patrones intrínsecos nuestros datos. Pero hay características más simples también describen la esencia de las leyes existentes.
Supongamos que tenemos todos los eventos n. Cada evento es descrita por el vector. Los componentes de este vector:
Para cada atributo se puede escribir como se manifiesta en cada uno de los eventos:
Para cualquier par de características en el que la descripción, es posible calcular el valor que indica el grado de manifestaciones articulares. Este valor se denomina la covarianza:
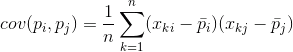
Se muestra la cantidad de desviación del valor medio de uno de los signos de la manifestación de la misma, con el mismo rechazo de otra señal. Si los valores característicos promedio son cero, entonces la covarianza se convierte en:
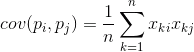
Si la covarianza correcta en desviaciones estándar características inherentes, se obtiene un coeficiente de correlación lineal, también llamado el coeficiente de correlación de Pearson:
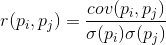
El coeficiente de correlación tiene una notable propiedad. Toma los valores de -1 a 1. Y 1 es una proporcionalidad directa de los dos valores, y -1 indica su relación lineal inversa.
De todos los signos de covarianza parejas pueden hacer que la matriz de covarianza, que es fácil de ver, es la expectativa del producto:
Además, creemos que nuestros datos se normaliza, es decir, tiene varianza unitaria. En este caso la matriz de correlación coincide con la matriz de covarianza.
Así que resulta que el ingrediente principal es cierto:
Ese es el componente principal, o, como se les llama, los factores son vectores propios de la matriz de correlación. Corresponden a los valores propios. Al mismo tiempo, mayor es el número de cuenta, mayor será el porcentaje de varianza explicada este factor.
Sabiendo todos los componentes principales para cada evento es la implementación de X em> , puede grabarlo en la proyección de los componentes principales:
Por lo tanto, se puede imaginar todos los eventos originales en las nuevas coordenadas, las coordenadas de los componentes principales:
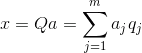
Generalmente distinguir el procedimiento de búsqueda del componente principal y el procedimiento de búsqueda de la base de los factores y la rotación posterior, lo que facilita la interpretación de los factores, pero dado que estos procedimientos son ideológicamente cerca y dan un resultado similar se llamará tanto el análisis factorial.
Para un procedimiento bastante simple de análisis factorial se encuentra significado muy profundo. El hecho es que si los signos iniciales de espacio - es el espacio observado, factores - estos son signos que describen las propiedades e incluso del mundo, pero en el caso general (si no está de acuerdo con los signos observados) son entidades oculto. Ese es el procedimiento formal de análisis factorial de los fenómenos observados deja ir al descubrimiento de fenómenos, aunque directa e invisible, pero sin embargo existen en el mundo exterior.
Podemos suponer que nuestro cerebro está utilizando activamente los factores de selección como uno de los procedimientos de conocimiento del mundo. Los factores que son capaces de construir una nueva descripción de lo que sucede con nosotros. La base de estas nuevas definiciones - la gravedad de lo que está sucediendo en aquellos eventos que coinciden con los factores seleccionados
.
Pocos explicar la esencia de los factores a nivel del hogar. Supongamos que usted es un gerente de personal. Para obtener una gran cantidad de gente, y en cada uno de llenar una forma determinada, que registran diversos datos observables sobre el visitante. Después de revisar mis notas más tarde, es posible que algunas columnas tienen una cierta relación. Por ejemplo, un corte de pelo para los hombres es en promedio más corta que las mujeres. Gente calva que es probable que se encuentran sólo entre los hombres, y el lápiz labial son sólo las mujeres. Si los datos personales se aplican al análisis factorial, es el piso y sería uno de los factores que explican las diversas leyes. Sin embargo, el análisis factorial permite encontrar todos los factores que explican las correlaciones en el conjunto de datos. Esto significa que además del factor de sexo, que podemos observar, y otros se destacan, incluyendo factores implícitos, no observables. Y si el suelo aparecerá de forma explícita en el cuestionario, es otro factor importante será entre líneas. La evaluación de la capacidad de las personas vinculadas a expresar sus pensamientos, la evaluación de su éxito profesional mediante el análisis de su evaluación del diploma y los síntomas como, se llega a la conclusión de que no existe una evaluación general de la inteligencia humana, que es claramente en el cuestionario no se registra, pero que explica muchos de sus puntos. Evaluación de la inteligencia - este es el factor oculto, el principal componente de alto efecto-cultivo. Obviamente no vemos este componente, pero fijamos signos, que se correlacionan con él. Con la experiencia, podemos subconscientemente por motivos independientes para formar una idea sobre el interlocutor inteligencia. Ese procedimiento, que en este caso usa nuestro cerebro es, de hecho, el análisis de factor. Observando cómo ciertos fenómenos ocurren al mismo tiempo, el cerebro, usando un procedimiento formal, pone de relieve los factores que se reflejan regularidades estadísticas estables inherentes al mundo que nos rodea.
Selección de un conjunto de factores
Hemos mostrado cómo un filtro selecciona Hebb componente primera directora. Resulta que con la ayuda de redes neuronales puede obtener fácilmente no sólo la primera, pero todos los demás componentes. Esto se puede hacer, por ejemplo, el siguiente método. Supongamos que tenemos rasgos de entrada. Tome las neuronas lineales donde.
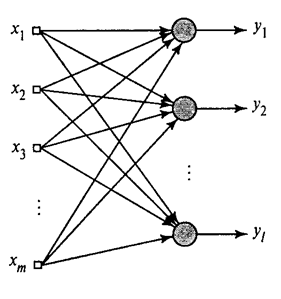
La Hebb algoritmo generalizado em> (Haykin, 2006)
Vamos a enseñar a la primera neurona Hebb como un filtro, por lo que se ha asignado el primer componente principal. Pero cada neurona sucesiva entrenará de barril, que excluye el efecto de todo componente anterior.
La actividad de las neuronas en el paso n em> se define como
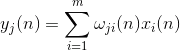
Una corrección a la sinóptica escalas como
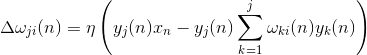
donde entre 1 y 1 a. em>
Para todas las neuronas se ve como la formación, un filtro similar Hebb. La única diferencia es que cada neurona sucesiva no ve la señal completa, sino sólo que "no vio" las neuronas anteriores. Este principio se llama una reevaluación. Estamos realmente en un conjunto limitado de componentes están restaurando la señal original y hace la siguiente neurona sólo ven el resto de la diferencia entre la señal original y la reconstruida. Este algoritmo se llama un algoritmo de Hebb generalizada.
En el algoritmo de Hebb generalizada no es del todo así que es demasiado carácter "computación". Las neuronas deben ser ordenados y estafando a sus actividades deben llevarse a cabo estrictamente en secuencia. No está muy igualada con los principios de la corteza cerebral, cada neurona en e interactúa con los demás, pero es fuera de línea, y donde no hay definido claramente "CPU", que definiría la secuencia general de eventos. Debido a estas consideraciones aparecen algoritmos más atractivas, llamó a los algoritmos de-correlación.
Imaginemos que tenemos dos capas de neuronas Z 1 sub> y Z 2 sub>. La actividad de las neuronas en la primera capa forma una especie de imagen que se proyecta a lo largo de los axones a la siguiente capa.
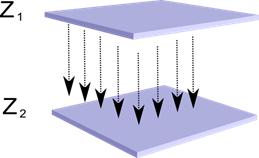
La proyección de una capa a otra em>
Ahora imaginar que cada neurona de la segunda capa tiene conexiones sinápticas con todos los axones que viene de la primera capa, si caen dentro de los límites de una determinada zona de la neurona (figura siguiente). Los axones que entran en una región, constituyen el campo receptivo de la neurona. El campo receptivo de la neurona - un fragmento de la actividad total, que es a su disposición para la observación. Para el resto de la neurona no existe.
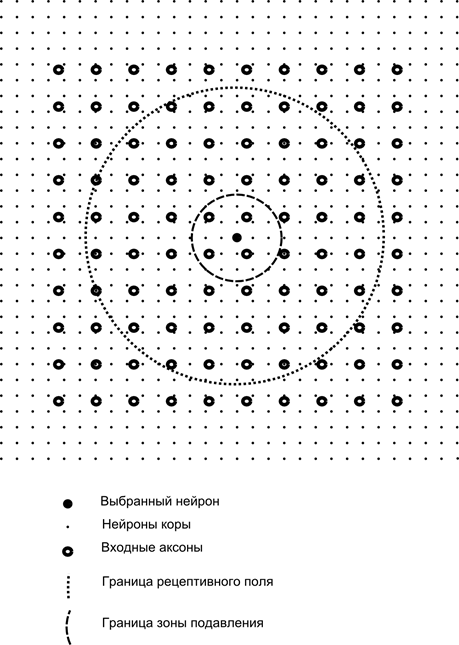
Además del campo receptivo de la neurona introducir un área ligeramente más pequeño, lo que llamamos la zona de la supresión. Conecte cada neurona con sus vecinos, cae en esta área. Tales enlaces son llamados lateral o siguiente aceptadas en la terminología de biología lateral. Realice la conexión inhibitoria lateral, es decir, disminuir la actividad de las neuronas. La lógica de su trabajo - la actividad de las neuronas inhibe la actividad de todas las neuronas, que caen dentro de la zona de inhibición
.
Conexiones excitatorias e inhibitorias pueden ser distribuidos estrictamente con todos los axones o las neuronas dentro de los límites de las regiones respectivas, y se pueden configurar accidentalmente, como cierto centro densamente poblada y la disminución exponencial de la densidad de las conexiones como la distancia de ella. Llenado continuo más fácil para la simulación, una distribución aleatoria de los términos anatómicos de comunicación en la corteza real.
La función de la actividad de las neuronas se puede escribir:
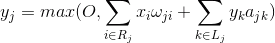
donde - la actividad final - una gran cantidad de axones que entran en la zona receptiva de la neurona seleccionados - el conjunto de neuronas en el área de la supresión de los cuales consigue elegido neurona - el poder de la inhibición lateral correspondiente, toma un valor negativo
.
Tal función es la actividad recursiva, porque la actividad de las neuronas depende de uno al otro. Esto conduce al hecho de que un cálculo práctico se realiza de forma iterativa.
Pesos sinápticos Educación es similar para filtrar Hebb:
Peso lateral entrenados para la regla anti-Hebb, el aumento de la frenada entre las neuronas "similares":
La esencia de este diseño es que el aprendizaje de Hebb debe dar lugar a la evolución de la balanza de los valores de las neuronas correspondientes a los primeros factores principales específicos de los datos presentados. Sin embargo, la neurona es capaz de entrenar en la dirección de un factor sólo cuando está activo.























La lógica de pensamiento. Parte 1. Neurona
El pensamiento lógico. Parte 3: Perceptron, red de convolución