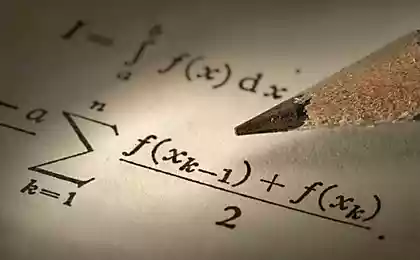1223
思维的逻辑。第2部分因素

该 一节中,我们描述了正式的神经元的最基本的属性。发出该阈加法部精确地再现尖钉的性质,和线性组合器可以模拟神经元响应,包括一系列脉冲。它表明,该线性组合器的输出的值可以与所造成的实际神经尖峰的频率进行比较。现在我们来看看的基本属性,这有这样正规的神经元。
过滤赫布
接下来,我们将经常提及神经网络模型。原则上,几乎所有的神经网络的理论的基本概念是直接相关的脑的实际结构。面临着一定的挑战的人,神经网络发明了很多有趣的设计。进化,通过带走了一切这是对她有帮助的所有可能的神经机制。这并不奇怪,这么多车型,设计由人,就可以找到明确的生物原型。随着我们的故事的目的并不在于即使神经网络理论的一个详细的阐述,我们接触就只来形容的基本思路所需要的最常见的功能。为了更好地理解,我强烈建议转向文学。对我来说,神经网络的最好的教科书 - 是西蒙赫金“神经网络。全部课程“(赫金,2006年)。
在许多神经网络模型的心脏是一个众所周知的海布学习规则。有人建议生理学家唐纳德·赫布于1949年(赫布,1949年)。在一个小自由泳的解释,它有一个非常简单的意思:神经元的连接被激活起来,应该得到加强,无论触发由于神经元,应消退
。 线性组合的输出状态可以写成:
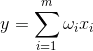
如果我们开始小批量权重的初始值,我们将申请各种输入图像,再没有什么可以阻止我们尽力培养这种神经元由赫布规则:
其中的 N em>的 - 在一个时间的离散步骤 - 设定学习速度
这样的过程中,我们增加输入,该信号通知的重量,但这样做越强学习者神经元的反应活性。如果没有反应,然后和培训。
然而,这些权重将无限增长,这样你就可以申请正常化的稳定。例如,分割从“新”突触权重导出的向量的长度。
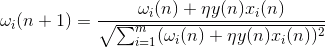
与此训练是突触之间的平衡的一个再分配。了解再分配更容易,如果分两期余额中进行改变。首先,当神经元是活性的那些突触,其接收信号获得的添加剂。突触的无信号的权重保持不变。然后,整体归一化降低了所有突触的权重。但在没有比它以前的值,而突触重新分配这些损失之间的信号丢失信号相同的突触。
海布的规则不是别的最陡下降的表面上的错误的方法的实现。事实上,我们做一个神经元调出“信号,每次在相反的错误改变其重量,也就是,在方向antigradient。要梯度下降给我们带来了一个局部极值,它不滑,的下降速度必须足够小。是采取什么样的赫布学习考虑参数的渺小。
学习率参数的渺小,您可以重写前面公式中的一系列形式:
如果我们拒绝了第二个命令的条款及以上,得到正确的训练伊亚(欧雅,1982):
阳性负责代理赫布学习,和负的整体稳定性。写作这种方式可以让你觉得像这样的培训可以在模拟环境中实现不使用计算,仅在正面和负面的连接方面。
因此,一个很简单的训练有一个美好的财产。如果我们逐渐降低学习速度,学习者神经元突触加权收敛到它的输出开始,以对应于第一主成分,如果我们使用提供到主成分分析的有关程序的数据时所获得这样的值。这种设计称为过滤器赫布。
例如,将提供输入神经像素图像相当于每个神经元突触一点的形象。我们将适用于所述输入神经元只有两个图像 - 的通过中心的垂直线和水平线的图像。训练的一个步骤 - 一个单一的形象,单行线,水平或垂直。如果这些图像被平均化时,它将越过。但培训效果不会像平均。这是线之一。那是最经常在提交图像所遇到的之一。神经元提供无平均或交叉,并且经常一起出现的这些条款。如果图像是比较复杂的,其结果可能不是那么直观。但它永远是它的一个重要组成部分。
教育神经元导致了其资产分配(过滤器)某种方式的事实。当一个新的信号时,更精确的匹配信号和调整平衡,神经元的较高的响应。受过训练的神经元可被称为神经元检测器。图像,这是由它的砝码,所谓的特征刺激。
的主要部件
主分量的方法的思想是简单和巧妙。假设我们有事件的序列。他们每个人,我们通过对传感器,这是我们感知世界的影响力形容。让我们假设我们有传感器,描述的特点。所有的事件为我们描述矢量的维数。这个矢量的每个分量表示对应第i个属性的值。它们共同构成一个随机变量的的 X em>的 STRONG>。这些发展,我们可以得出在n维空间中的点,其中轴将执行我们观察到的迹象。
平均值给出了一个随机变量的 X STRONG>的期望,记为E( X STRONG>)。如果我们中心的数据,使E( X STRONG>)= 0,点云将集中围绕原点。
这种云可拉伸在任意方向。尝试过所有可能的方向,我们可以发现,沿着该数据的方差将最大。
所以,这个方向对应于第一主成分。极主要成分是由从原点的单位矢量发出并与该方向一致来决定。
此外,我们可以找到另一个方向垂直的第一部件,使得沿着它的分散体也属于所有垂直的方向上最高。发现它后,我们得到第二组分。然后我们就可以继续搜索,指定必须跻身方向寻求垂直于已发现的组件的条件。如果原始坐标是线性无关的,所以我们可以再次充当直到空间的维数的末端。因此,我们得到一个组件相互安排的数据差异,他们解释的比例。
当然,获得的主要组成部分反映了固有的模式我们的数据。但还有更简单的特点也说明了现行法律的本质。
假设我们有所有的n事件。每个事件由矢量描述。此向量的组件:
每个属性可写为它体现在每个事件:
对于任何两个功能在其上的描述,可以计算出值指示的关节表现的程度。这个值就是所谓的协方差:
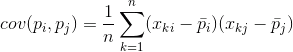
它显示了由相同的表现的标志之一的平均值多少偏差,与另一个符号相同的排斥反应。如果平均特征值都为零,则协方差变为:
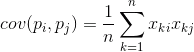
如果标准偏差固有特性的正确的协方差,我们得到一个线性相关系数,也被称为Pearson相关系数如下:
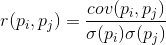
相关系数有一个显着的特性。这需要从-1值设置为1和0的两个值的直接比例,和-1表示它们的反线性关系。
所有成对协方差标志可以使协方差矩阵,是很容易看到的,是产品的期望:
我们还相信,我们的数据是标准化的,也就是有单位方差。在这种情况下,相关矩阵正好与协方差矩阵。
所以,事实证明,其主要成分是正确的:
即主成分,或者,因为他们是所谓的因素是相关矩阵的特征向量。它们对应于特征值。同时,更大自己的号码,更大方差的百分比说明这个因素。
知道所有的每个事件的主要成分是 X em>的 STRONG>,你可以燃烧它的主要成分投影的实现:
因此,你能想象的所有原始事件中的新坐标,坐标主成分:
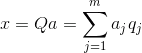
通常区分搜索过程的主要成分,并找到的因素和随后的旋转的基础上,促进下述因子的解释的方法,但由于这些程序思想上接近和得到类似的结果将被称为两因素分析。
因子分析的一个相当简单的程序就在于非常深刻的意义。的事实是,如果空间的初步迹象 - 是所观察到的空间中,因子 - 这些是描述甚至世界的性能和迹象,但在一般情况下(如果不与观察到的迹象同意)被隐藏的实体。这是观察到的现象因子分析的正式程序,让去的现象发现,虽然直接的和不可见,但仍然存在着外面的世界。
我们可以假设,我们的大脑正在积极使用选择因素作为世界的知识的过程之一。我们的因素能够建立正在发生的事情与我们的新说明。这些新定义的基础 - 发生的事情在那些符合所选择的因素,事件的严重性
。
很少有人会解释的因素精髓在家庭层面。假设你是员工的经理。为了你得到了很多人,并在每次填写一定的形式,对游客而记录各种观察数据。后来审查我的笔记后,您可能会发现某些列有一定的关系。例如,一剪发为男性的平均比女性短。被发现仅在男性秃头的人,你很可能会和口红都只有妇女。如果个人数据适用于因子分析,这是地板,并且将是解释一些法律的因素之一。然而,因子分析法可以让你找到的所有解释数据集中的相关因素。这意味着,除了性因素,我们可以观察等人站在出来,包括隐式的,观察不到的因素。如果地板会显式出现在问卷,是另一个重要的因素将是该线路之间。评估人联系在一起来表达自己的思想,通过分析文凭之类的症状,他们的评价评估其事业成功的能力,你会得出的结论是有人类的智慧,这显然是在没有被记录的调查问卷进行全面评估,但是这也解释了它的许多点。情报的评价 - 这是隐藏的因子,高栽培效果的主要成分。很显然,我们没有看到这个成分,但我们解决的迹象,这是相关的吧。随着经验的积累,我们就可以在不同的理由,下意识地形成对智能对话者的想法。该程序,在这种情况下使用我们的大脑,其实,因子分析。怎么看某些现象一起发生,大脑,用一个正式的程序,突出因素反映内在我们周围的世界稳定的统计规律。
选择一组因素
我们已经展示了如何过滤器选择海布第一主成分。事实证明,与神经网络的帮助下可以很容易地不仅获得第一,但所有的其他组件。可以做到这一点,例如,下面的方法。假设我们有输入特征。以线性神经元的位置。
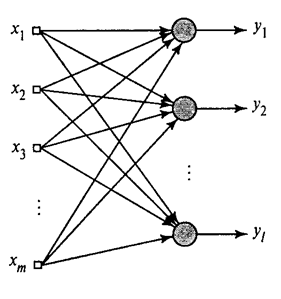
广义赫布算法 em>的(赫金,2006年)
我们将教第一神经元海布作为一个过滤器,以便分配给它的第一主成分。但每次连续神经元将列车上的水龙头,这排除了所有以前的分量的影响。
在步骤神经元的活性的 N em>的定义为
一个修正的天气尺度像
其中1和1之间。 em>的
对于所有的神经元,它看起来像训练,一个类似的过滤器赫布。唯一的区别是,每个连续神经元不会看到整个信号,而是仅表示“没看到”以前的神经元。这一原则被称为重新评估。我们实际上在一组部件还原原始信号的有限和,使下一个神经元只能看到原始信号和重构之间的差异的其余部分。该算法被称为广义海布算法。
在广义赫布算法不是很清楚,实在是太“计算”的性格。神经元要责令以及受骗的活动应在严格的顺序进行。它不是非常与大脑皮层的原理在匹配时,每个神经元和与他人交互,但它是脱线,并且其中有没有明确定义的“CPU”,这将定义事件的整体序列。由于这些考虑出现更具吸引力的算法,称为解相关的算法。
试想一下,我们的神经元ž<子> 1 SUB>两层和Z 2 SUB>。在第一层中的神经元的活性形成一种的画面,沿着轴突到下一层的投影。
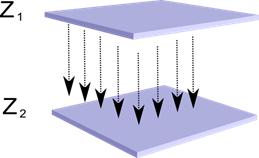
一层到另一个投影 em>的
现在,假设在第二层的每个神经元有与所有的轴突从第一层的到来,如果它们落入神经元(下图)的某一邻域的边界内的突触连接。进入这种区域轴突,形成神经元的感受野。神经元的感受野 - 总活性的片段,这是提供给他的观察。对于神经元的其余部分不存在。
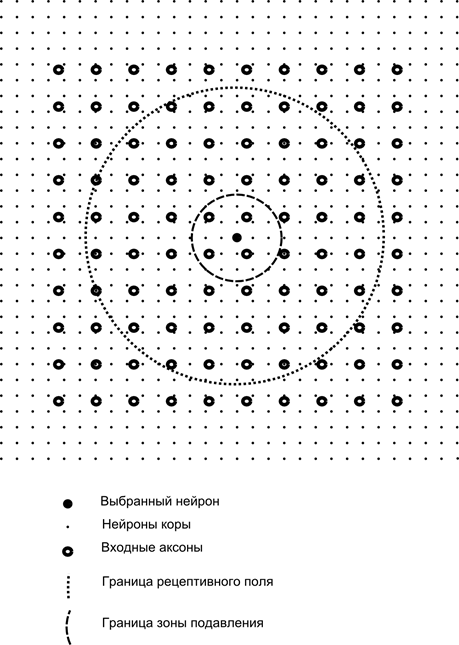
除了神经元的感受野介绍略小面积,我们称之为抑制的区域。连接每个神经元与其邻国,属于这一地区。这些链接被称为横向或在生物学术语以下接受横向。使横向的抑制连接,即,减少的神经元的活性。他们的工作的逻辑 - 神经元的活动禁止了所有的神经元,落在抑制区域内的活性
。
兴奋性和抑制连接可以严格与各区域的边界之内的所有的轴突或神经元被分布,并且可以设置意外,例如某些人口稠密中心和连接从它的距离的密度的指数下降。连续灌装方便了模拟,随机分布的实际地壳传播的解剖方面。
神经元活动的功能,可以写成:
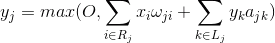
其中 - 最终活动 - 很多进入选定神经元的接收面轴突 - 在抑制其中得到选择神经元的区域中的一组神经元 - 的相应侧抑制的功率,取负值
。
这样的功能是递归的活性,因为神经元的活性取决于对方。这导致了实际的计算迭代地执行的事实。
教育突触权重类似于过滤赫布:
训练反赫布规则横向体重,增加“类似的”神经元之间的制动:
这种设计的实质是,赫布学习应当导致对应于特定于所提交的数据的第一个主要因素的神经元的值的平衡中的演变。但神经元能够在仅当它处于活动状态的一个因素的方向来训练。