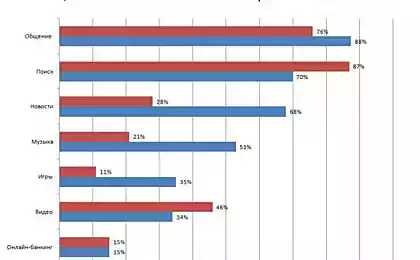
984
WEB 3.0. From Saitocentrism k yuserocentrism, from anarchy k spitalism

The text summarizes the ideas expressed by the author in the report “Philosophy of evolution and evolution of the Internet”.
The main disadvantages and problems of the modern web:
- Catastrophic network congestion with repeatedly duplicated content, in the absence of a reliable mechanism for finding the original source.
- Dispersal and incoherence of content – the inability to make an exhaustive sample on the subject and, especially, on the levels of analysis.
- The dependence of the form of content presentation on publishers (often random, pursuing their own, usually commercial, goals).
- Weak connection of search results with the ontology (interest structure) of the user.
- Low availability and low classification of archival content of the network (in particular, social networks).
- Small participation of professionals in the organization (systematization) of content, although they are by the nature of their activities daily engaged in the systematization of knowledge, but the result of their work is recorded only on local computers.
The main reason for the debris and irrelevance of the network is a website device inherited from Web 1.0, in which the main person in the network is not the owner of the information, but the owner of the place where it is located. That is, the ideology of material content carriers was transferred to the network, where the main thing was the place (library, kiosk, fence) and the object (book, newspaper, paper), and only then their content. But since, unlike the real world, space in the virtual world is not limited and costs a penny, the number of places offering information by orders of magnitude exceeded the number of units of unique content. Web 2.0 partially corrected the situation: each user received his personal space – an account in the social network and the freedom to configure it to some extent. But the problem with the uniqueness of the content has only worsened: copypaste technology has increased the degree of duplication of information by orders of magnitude.
Efforts to overcome these problems of the modern Internet are concentrated in two, to some extent interrelated, directions.
- Improving search accuracy by microformatting content distributed across sites.
- Creating "storage" of reliable content.
Developments in the second direction (Google, Freebase.Com, CYC, etc.) allow obtaining unambiguously reliable information, but only in areas where this is possible – the problem of knowledge pluralism in areas where there are no uniform standards and common logic of data systematization remains open. The problem of obtaining, systematizing and including new (current) content in the database is difficult to solve, which is the main problem in a modern socially oriented network.
What are the solutions offered by the userocentric active approach outlined in the report “Philosophy of evolution and evolution of the Internet”?
- Rejection of site structure – the main element of the network should be a unit of content, not its location; the network node should be a user, with a set of content units configured relative to it, which can be called the user’s ontology.
- Logical relativism (pluralism), stating the impossibility of the existence of a single logic of information organization, recognizing the need for an infinite number of practically independent ontological clusters even within the same topic. Each cluster is an ontology of a user (individual or generalized).
- An active approach to the construction of ontologies, implying that ontology (cluster structure) is formed and manifested in the activity of a content generator. This approach requires a reorientation of network services from the generation of content to the generation of ontologies, which essentially means creating tools for implementing any activity on the network. The latter will attract many professionals to the network, who will ensure its functioning.
- Ontology is created by a professional in the course of his professional activity. The system provides the professional with all the tools to enter, organize and process any type of data.
- Ontology is revealed in the activities of a professional. This is now possible because a large percentage of any activity is performed or recorded on a computer. A professional should not build ontology, he should act in a software environment, which is both the main tool of his activity and the generator of ontology.
- Ontology becomes the main result of activity (both for the system and for the professional) - the product of professional work (text, presentation, table) is only an excuse for building an ontology of this activity. It is not an ontology that is tied to a product (text), but a text that is understood as an object generated in a particular ontology.
- Ontology should be understood as an ontology of concrete activity; how many activities – so many ontology.
So, the main conclusion: Web 3.0 is the transition from a site-centric web to a semantic user-centric network – from a network of web pages with arbitrarily configured content to a network of unique objects combined into an infinite number of cluster ontologies. From the technical side, Web 3.0 is a set of online services that provide a full range of tools for entering, editing, searching and displaying any type of content, which simultaneously provide ontology of user activity, and through it, ontology of content.
Alexander Boldachev, 2012-2015
Source: habrahabr.ru/post/256083/