1240
Saw - to win. How does the seizure of objects in the robot Tod Bot

Hi Habr! And here we are again! On perekor number of skeptics, who often comes our way, we continue to develop the project "Robot Tod Bot». This post is a continuation of exploring the module MoveIt as a management tool manipulator.
First of all I want to say that we managed to achieve considerable results in the problem of capturing and moving objects through the manipulator, as well as in the recognition of objects, but first things first.
A little theory about the capture in MoveIt h4> Capture object can be represented as pipeline consisting of several stages, which are calculated ready for execution complete path, starting from the initial position of the manipulator and to the immediate lifting of the object. These calculations are based on the following data:
- Planning stage, which provides a tool Planning Scene Monitor
- The object identifier for the capture
- The pose of the hand gripping for this object
- The position and orientation of the "brush" manipulator
- The expected probability of successful capture for this position
- A preliminary approach of the manipulator, which is defined as the direction of the vector - the minimum / desired distance approach < /
- The indentation after the capture of the manipulator, which is defined as the direction of the vector - the minimum distance indent
- The maximum gripping force
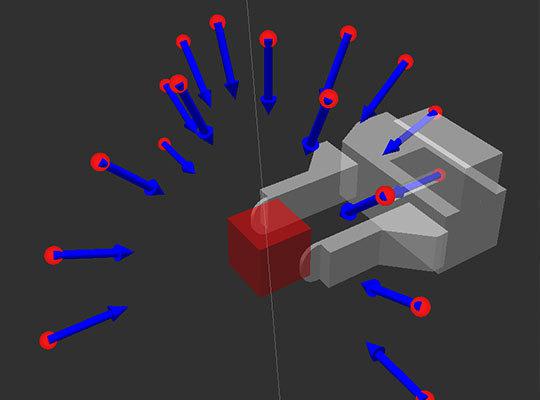
Among the obtained set of possible keys, we must weed out those poses that do not meet our form capture / brush, then transfer the remaining conveyor for further planning of the trajectory to achieve these postures.
In the conveyor lifting the object, there are three main points:
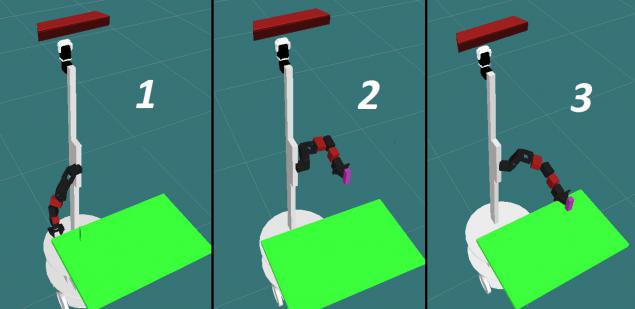
1- The initial position; 2- Position predzahvata; 3 - Position of capture;
During the execution of the individual conveyor path will be added to the final plan of raising the subject. If capture has successfully passed all stages, only then the plan can be executed. Algorithm conveyor generally looks:
- planned trajectory from the initial position to the point predzahvata. To draw an analogy with the landing of the aircraft on the runway, it will approach.
- All the objects of the environment was originally included in the collision matrix, we wrote about it here . What would our capture was a success, collision detection is disabled. Then open the capture.
- Calculate the trajectory approaches the manipulator to the object from point to point predzahvata capture.
- Closes grip.
- The captured object still seems collision object so only difference is that now he is part of the trap and is taken into account when planning the trajectory.
- Then the generated trajectory departing from the position at the point of capture predzahvata to detach from the surface of the object and lock by lifting the object. Built plan containing all the necessary trajectory can now be configured. < br />
That still does not say h4> Entrance of our experiments, we decided to add our hand to the original four degrees of freedom are two more. The video and photos are shown in red. This is due to the fact that in the case of capture in the form of a fork or anthropomorphic brush needs a good flexibility of the manipulator. Incidentally, if used as a vacuum suction cup gripping, all somewhat simplified and may be sufficiently four degrees of freedom, since is used to capture only one plane.
In fact, the ability to perform the capture largely rests on the generation position of capture: the larger and more diverse positions will be generated, the easier it will be to choose the optimum. Although the whole thing has a downside: the more items, the longer it takes to process them. In our case, we first generate 10, 34 position, then 68, then 136. The best option, which gave us - 34 positions. With a minimum number of positions the manipulator is quite difficult to be generated by the pose usually manipulator just physically can not achieve it, unable to wriggle out that way, too short, too long, etc. At present 34 from 2 to 5 products satisfy all the conditions.
Object recognition h4> To this end, we decided to use a node ROS tabletop_object_detector. It was implemented by scientists at the University of British Columbia and has already proved themselves. Although, in my opinion, the choice of the system should depend directly on the conditions in which you are going to apply the recognition and the objects that need to be identified. In our case, the detection is carried out in the form of objects, and if you need to distinguish the bank from banks cucumbers tomatoes, then this method will not work. To identify objects used camera data depth obtained with Kinect.
Before you recognize, you must first train the system - to create a 3D model of the desired object.

3D model packs Pringles
The system then compares the received data with the existing models in the database.
The recognition result looks like:
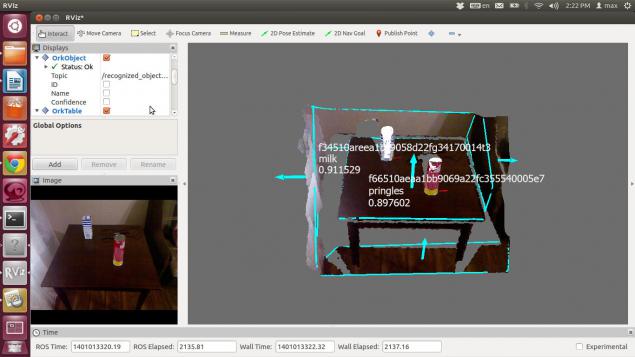
As expected, the speed of the search facilities on the line depends on the power of the machine on which the data processing. We used a laptop with intel core 2 duo 1.8ghz and 3Gb RAM. Thus the identification of objects takes about 1, 5 - 2 seconds.
And of course, being able to isolate and identify objects in the environment, and now I want to take and move them. The next step will be the integration problems of recognition and control arm on a real robot.
Source: habrahabr.ru/company/tod/blog/224765/



























Samsung launches the industry's first flash memory 3D V-NAND, which has 32 layers of memory cells
The former hobby or as I realized a childhood dream