Жизнь — интересная!
Подписывайтесь на нашу группу в Telegram и Facebook, чтобы быть в сообществе единомышленников, находить вдохновение и не пропускать свежие и удивительные статьи с bashny.net.
1239
0.3
2014-06-01
Увидел – Победил. Как устроен захват предметов у робота Tod Bot

Привет Хабр! А вот и снова мы! На перекор множествам скептиков, которые нередко встречались на нашем пути, мы продолжаем развивать проект «Робот Tod Bot». Данный пост является продолжением знакомства с модулем MoveIt как инструментом управления манипулятором.
Прежде всего хочется сказать, что нам удалось достигнуть значительных результатов в задаче захвата и перемещения предметов посредством манипулятора, а также в распознавании объектов, но обо всем по порядку.
Немного теории о захвате в MoveIt
Захват предмета можно представить в виде конвейера, состоящего из нескольких этапов, в котором рассчитывается готовая к исполнению полная траектория: начиная от первоначального положения манипулятора и до непосредственного поднятия объекта. Эти расчеты производятся на основе следующих данных:- Планирования сцены, которое обеспечивает инструмент Planning Scene Monitor
- Идентификатор объекта для захвата
- Поза захвата кисти для данного объекта
- Положение и ориентация «кисти» манипулятора
- Ожидаемая вероятность успешного захвата для этой позы
- Предварительный подход манипулятора, который определяется как направление вектора — минимальное/желаемое расстояние подхода
- Отступ манипулятора после захвата, который определяется как направление вектора — минимальное расстояние отступа
- Максимальное усилие захвата
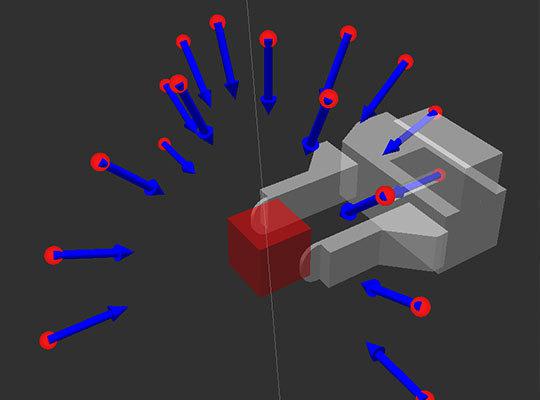
Среди полученного множества возможных поз мы должны отсеять те позы, которые не удовлетворяют форме нашего захвата/кисти, после чего передать оставшиеся в конвейер для дальнейшего планирования траектории достижения этих поз.
В конвейере поднятия предмета, можно выделить три основных момента:
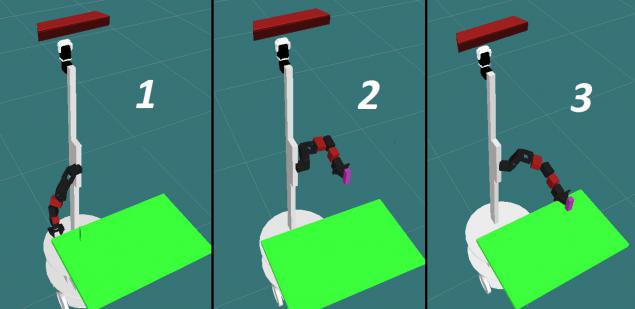
1- Начальное положение; 2- Позиция предзахвата; 3 – Позиция захвата;
Во время выполнения конвейера отдельные траектории будут добавлены в окончательный план поднятия предмета. Если захват успешно прошел все этапы, то только тогда план может быть выполнен. Алгоритм конвейера в общем виде выглядит так:
- Планируется траектория от начального положения в точку предзахвата. Если провести аналогию с посадкой самолета на взлетную полосу, то это будет заход на посадку.
- Все объекты окружающей среды изначально включены в матрицу столкновений, об этом мы писали тут. Что бы наш захват увенчался успехом, проверка столкновений отключается. Затем открывается захват.
- Рассчитывается траектория подхода манипулятора к объекту от точки предзахвата к точке захвата.
- Закрывается захват.
- Захваченный объект по-прежнему представляется объектом столкновения столь лишь разницей, что теперь он является частью захвата и учитывается при планировании траектории.
- Затем генерируется траектория отступа из позиции захвата в точку предзахвата для отрыва предмета от поверхности и фиксации результата поднятия предмета.
О том, что еще не сказали
Входе наших экспериментов мы решили добавить нашей руке к первоначальным четырем степеням свободы еще две. На видео и фото они изображены красным цветом. Связано это с тем, что в случае использования захвата в виде вилки или антропоморфной кисти необходима хорошая гибкость манипулятора. Кстати, если использовать в качестве захвата вакуумную присоску, то все несколько упрощается и может быть достаточно 4 степеней свободы, т.к. для захвата используется только одна плоскость.На самом деле, возможность выполнения захвата во многом упирается в генерирование позиций захвата: чем больше и разнообразней будут генерироваться позиции, тем проще будет подобрать оптимальную. Хотя у всего этого есть и обратная сторона медали: чем больше позиций, тем больше времени потребуется на их обработку. В нашем случае мы генерировали сперва 10, 34 позиции, потом 68, а потом 136. Лучшим вариантом, который устроил нас — 34 позиции. При минимальном количестве позиций манипулятору достаточно сложно стать в сгенерированную позу, как правило манипулятор просто физически не может ее достигнуть: не в состоянии именно так вывернуться, слишком короткий, слишком длинный и т.д. При 34 присутствуют от 2 до 5 позиций удовлетворяющих всем условиям.
Распознавание объектов
Для этих целей мы решили использовать узел ROS tabletop_object_detector. Он был реализован учеными Университета Британской Колумбии и уже успел себя зарекомендовать. Хотя, на мой взгляд, выбор системы должен зависеть непосредственно от тех условий, в которых вы собираетесь применять распознавание и тех объектов, которые нужно идентифицировать. В нашем случае распознавание осуществляется по форме объектов, и если вам нужно различить банку огурцов от банки помидоров, то этот метод не подойдет. Для идентификации объектов используются данные камеры глубины, получаемые с Kinect.Прежде чем распознавать, сперва необходимо обучить систему — создать 3D модель искомого объекта.

3D модель пачки Pringles
После чего система сравнивает получаемые данные с имеющимися в базе моделями.
Результат распознавания выглядит так:
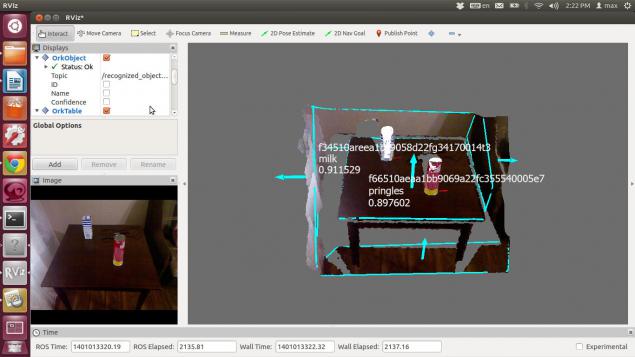
Как и следовало ожидать, скорость поиска объектов на прямую зависит от мощности машины, на которой осуществляется обработка данных. Мы использовали ноутбук с intel core 2 duo 1.8ghz и 3Gb RAM. При этом на идентификацию объектов уходило порядка 1,5 – 2 секунд.
Ну и естественно, умея выделять и идентифицировать объекты из окружающей среды, теперь хочется брать и перемещать их. Следующим шагом будет объединение задач распознавания и управления манипулятором на реальном роботе.
Источник: habrahabr.ru/company/tod/blog/224765/
Портал БАШНЯ. Копирование, Перепечатка возможна при указании активной ссылки на данную страницу.




































Samsung запускает производство первой в отрасли флеш-памяти 3D V-NAND, имеющей 32 слоя ячеек памяти
Бывшее хобби или как я осуществил мечту детства