779
Scientists from the Netherlands have confirmed that the second information layer in the DNA there
The sequence of alternation of bases, certain DNA molecules in every cell of our body makes us you like us there. At the same time, a number of scientists for quite a long time studying the possibility and probability of the existence of "alternative" hidden language, also encodes the vital information of the genome in a different way and at a different level. This coded information should serve as a guide to action, using which our body cells are able to recognize and handle the bulk of the information in strict sequence.
June 7, 2016 in the pages of scientific publications journals.plos.org was published a group of scientists from the Netherlands, who were able to prove the existence in our DNA the second hidden layer of information.
How the DNA encoding the protein structure
As is known, the basis of DNA - are the building blocks of the universe, which cause the very possibility of the existence and reproduction of all life on our planet. As part of a DNA molecule consists of four nucleotide bases nitrogenous species, identified by the letters "A", "T", "C" and «G».
Our each cell contains about 30 thousands of different genes, while some bacteria enough only 500 genes. Genes contain codes, according to which proteins are synthesized and determined the order of the amino acids in them. Wherever there were no human body cells, they always contain the same set of genes. However, depending on the cell type - skin cells, nerve or muscle - in which to synthesize new proteins exploit various genes
. Long chains of DNA in the chromosomes of the cells tightly together. The compact arrangement of chromosomal DNA is carried out by specific proteins, which are wound around the DNA strand. But in cell proteins present that to facilitate the synthesis of new proteins of the code contained in the DNA, the DNA is transferred from the compact shape into the expanded if necessary. Under the influence of these proteins are preparing to divide chromosomes of cells deployed and since then occupied 10 thousand times more space.
Nucleotides type "A", "T", "C" and "the G", are part of the long DNA molecules are arranged in a specific order to ensure that the encoding of proteins during their synthesis, which takes place from 20 different kinds of amino acids. DNA in this case serve as a matrix - each protein corresponds to a gene on the model of which the synthesis of amino acids that form the protein. Thus genetic code embodied in proteins, and the nucleotide sequence in the gene determines the sequence of amino acids in the protein. The simplest analogy - Morse code, where dots, dashes and set of certain correspond to letters of the alphabet. The sequence of nucleotides that can be read by three at one time corresponds to the amino acid sequence of the protein. In this set of three nucleotides are read at a time to encode a single amino acid. For example, the set of nucleotides encodes the amino acid AUG atsidometionin.
There are 64 combinations of nucleotides, but synthesized only 20 different kinds of amino acids. This means that some ternary nucleotide sequence is not used for the synthesis of amino acids, and the synthesis procedure to designate an interrupt. It is a meaningless set of ternary nucleotides do not happen - they each perform a specific function. There are several sets of nucleotides that encode the same amino acid. The largest gene consists of two million nucleotides, placed on each of its strands, and the smallest -. One thousand
The process of reading the genetic information ( "transcription"), begins with the discovery and deployment of a small portion of the DNA double helix at the end of chromosomes. The genetic code of the site chromosomes are copied and then the increasing as you move up the process of RNA molecule, and the protein copying mechanism moves along the DNA strand. The process of transferring the genetic code ends when at the end of the RNA is synthesized by the so-called terminal amino group - its presence signals the end of the code of the protein chain.
The sequence of alternation of these bases in the molecules determines the information that allows the cells of our body to produce a fixed number of desired proteins and maintain other vital functions. But, despite the fact that all cells of our body contain the same set of genes, cells develop themselves in different ways and it becomes just a confirmation that there are different types of tissue cells that make up the various organs. And all of this again and again makes scientists look for additional key to the "excessive", ie. E. Is not fully decoded information.

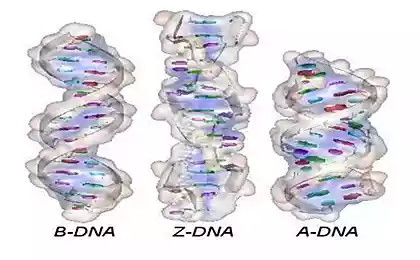
DNA molecules are extremely compact "packaged". On the other hand it is known that in its chain a disentangling of the molecules contained in the same cell on the average is 2 meters. According to the hypothesis, does not change since the 80s of the last century, the mechanical properties of the DNA molecule determines the manner in which it will be "phased out" inside the cell. The latest research by Dutch scientists have confirmed that the molecules form change results in a "folding" of the DNA helix to change. This fact allowed to talk about the presence of a part of the second DNA encoding mechanism, which plays in the reproduction of proteins support processes are not less important than the underlying genetic code.
The research team from the Institute of Physics, Leiden (Leiden Institute of Physics) led by Helmut Shisselya (Helmut Schiessel), has developed a computer model, the purpose of which was to check the above hypotheses and search for ways to prove its authenticity. The logical basis for the model were the similar cells of baker's yeast and the yeast of genus Schizosaccharomycetes, comprising a DNA molecule with the same base sequence but with different mechanical properties.
As demonstrated by the analysis of mathematical models of yeast DNA molecule really twisted (configurable) and acquire small size under the influence of different mechanical influences in different algorithms.
Other evidence of the existence of the secondary code
The main genetic code contained in DNA was partially deciphered in the 60-ies of the last century. Since then, the scientific community was absolutely sure that only the information recorded in DNA proteins that are produced by cells in the body as a response to external events and stimuli. Despite the fact that over time, this concept has been extended somewhat, the basic principles of the "single-language" in the DNA encoding remain unchanged.
However, research in this direction continued. In 2013, a group of scientists from the University of Washington (University of Washington, UW) was first announced the existence of the hidden secondary code that most directly determines the order of reading the genetic sequence of basic instructions contained in DNA. The results of studies that have confirmed the validity of the hypothesis have been published on the pages of Science.
Researchers concluded that the information in the genetic code is written in two different languages. The first describes and regulates the structure and the amount of protein produced by the cells, and the second determines the sequence of instructions that control the readout of genes. Construction of a second language, as noted by then scientists in their publications written over the designs of the first, which was the main reason being that "the most prominent place" he had so long been hidden from the attention of the scientific community.
Investigating the genetic sequences when scientists concluded that some kinds of codons (15% of the total), called Dwan can have two meanings, one of which is associated with the description of the structure of proteins, the other - with the principles of the control genes. Moreover, these two values are closely related to each other as the gene control instructions allow in some cases to stabilize certain areas of complex proteins at the time of manufacture. And that Dwan are the basis structures of the second language by which DNA is recorded in the second information layer.
"For more than 40 years, we believed that the changes only affect the production function of proteins in the genetic code of DNA molecules in the cells," - says Dr. John Stamatoyannopulos (Dr. John Stamatoyannopoulos), professor of medicine and genomics at Washington University, - "Now we know that reading the genetic information, we passed almost half of it, which, in turn, distort the overall picture of our knowledge. Armed with new knowledge about the presence of additional information we will soon be able to fully read all that is written in the DNA, in the most powerful to date, the information storage device,
created by nature itself. »
The value of the work
Knowledge of the fact that DNA molecules contain two types of information at the same time, will enable researchers to more fully recognize the changes in proteins which occur as a result of mutagenic processes affecting DNA structure. Accurate and complete picture of changes in the structure of proteins allow scientists to accurately and clearly define what are the causes of the disease, and what the result of such changes, and to develop new methods of treatment of diseases, based on changes in the part of the DNA information, which only controls the function of genes.
< br> On the other hand, researchers first able to confirm that the genetic mutations that, as previously assumed, could only affect the structure of the basic code of the genetic sequence may also affect the mechanical structure of DNA, which in turn will lead to changes in the reading sequence instructions for the production of proteins, changing the type and amount of the latter.
publication on the website of Leiden Institute of Physics
detailed presentation of the work in the journal PLOS One
That's all, you had a simple service to select Dronk.Ru sophisticated technology. Do not forget to subscribe to our blog, will be much more interesting ...




< br> Why online retailers give the money for the purchase? Review Xiaomi Mi Air Purifier 2 or how to clean the air of a megacity? Return the money - Choosing a cashback service to Aliexpress
Source: geektimes.ru/company/dronk/blog/277306/

June 7, 2016 in the pages of scientific publications journals.plos.org was published a group of scientists from the Netherlands, who were able to prove the existence in our DNA the second hidden layer of information.
How the DNA encoding the protein structure
As is known, the basis of DNA - are the building blocks of the universe, which cause the very possibility of the existence and reproduction of all life on our planet. As part of a DNA molecule consists of four nucleotide bases nitrogenous species, identified by the letters "A", "T", "C" and «G».
Our each cell contains about 30 thousands of different genes, while some bacteria enough only 500 genes. Genes contain codes, according to which proteins are synthesized and determined the order of the amino acids in them. Wherever there were no human body cells, they always contain the same set of genes. However, depending on the cell type - skin cells, nerve or muscle - in which to synthesize new proteins exploit various genes
. Long chains of DNA in the chromosomes of the cells tightly together. The compact arrangement of chromosomal DNA is carried out by specific proteins, which are wound around the DNA strand. But in cell proteins present that to facilitate the synthesis of new proteins of the code contained in the DNA, the DNA is transferred from the compact shape into the expanded if necessary. Under the influence of these proteins are preparing to divide chromosomes of cells deployed and since then occupied 10 thousand times more space.
Nucleotides type "A", "T", "C" and "the G", are part of the long DNA molecules are arranged in a specific order to ensure that the encoding of proteins during their synthesis, which takes place from 20 different kinds of amino acids. DNA in this case serve as a matrix - each protein corresponds to a gene on the model of which the synthesis of amino acids that form the protein. Thus genetic code embodied in proteins, and the nucleotide sequence in the gene determines the sequence of amino acids in the protein. The simplest analogy - Morse code, where dots, dashes and set of certain correspond to letters of the alphabet. The sequence of nucleotides that can be read by three at one time corresponds to the amino acid sequence of the protein. In this set of three nucleotides are read at a time to encode a single amino acid. For example, the set of nucleotides encodes the amino acid AUG atsidometionin.
There are 64 combinations of nucleotides, but synthesized only 20 different kinds of amino acids. This means that some ternary nucleotide sequence is not used for the synthesis of amino acids, and the synthesis procedure to designate an interrupt. It is a meaningless set of ternary nucleotides do not happen - they each perform a specific function. There are several sets of nucleotides that encode the same amino acid. The largest gene consists of two million nucleotides, placed on each of its strands, and the smallest -. One thousand
The process of reading the genetic information ( "transcription"), begins with the discovery and deployment of a small portion of the DNA double helix at the end of chromosomes. The genetic code of the site chromosomes are copied and then the increasing as you move up the process of RNA molecule, and the protein copying mechanism moves along the DNA strand. The process of transferring the genetic code ends when at the end of the RNA is synthesized by the so-called terminal amino group - its presence signals the end of the code of the protein chain.
The sequence of alternation of these bases in the molecules determines the information that allows the cells of our body to produce a fixed number of desired proteins and maintain other vital functions. But, despite the fact that all cells of our body contain the same set of genes, cells develop themselves in different ways and it becomes just a confirmation that there are different types of tissue cells that make up the various organs. And all of this again and again makes scientists look for additional key to the "excessive", ie. E. Is not fully decoded information.

DNA molecules are extremely compact "packaged". On the other hand it is known that in its chain a disentangling of the molecules contained in the same cell on the average is 2 meters. According to the hypothesis, does not change since the 80s of the last century, the mechanical properties of the DNA molecule determines the manner in which it will be "phased out" inside the cell. The latest research by Dutch scientists have confirmed that the molecules form change results in a "folding" of the DNA helix to change. This fact allowed to talk about the presence of a part of the second DNA encoding mechanism, which plays in the reproduction of proteins support processes are not less important than the underlying genetic code.
The research team from the Institute of Physics, Leiden (Leiden Institute of Physics) led by Helmut Shisselya (Helmut Schiessel), has developed a computer model, the purpose of which was to check the above hypotheses and search for ways to prove its authenticity. The logical basis for the model were the similar cells of baker's yeast and the yeast of genus Schizosaccharomycetes, comprising a DNA molecule with the same base sequence but with different mechanical properties.
As demonstrated by the analysis of mathematical models of yeast DNA molecule really twisted (configurable) and acquire small size under the influence of different mechanical influences in different algorithms.
Other evidence of the existence of the secondary code
The main genetic code contained in DNA was partially deciphered in the 60-ies of the last century. Since then, the scientific community was absolutely sure that only the information recorded in DNA proteins that are produced by cells in the body as a response to external events and stimuli. Despite the fact that over time, this concept has been extended somewhat, the basic principles of the "single-language" in the DNA encoding remain unchanged.
However, research in this direction continued. In 2013, a group of scientists from the University of Washington (University of Washington, UW) was first announced the existence of the hidden secondary code that most directly determines the order of reading the genetic sequence of basic instructions contained in DNA. The results of studies that have confirmed the validity of the hypothesis have been published on the pages of Science.
Researchers concluded that the information in the genetic code is written in two different languages. The first describes and regulates the structure and the amount of protein produced by the cells, and the second determines the sequence of instructions that control the readout of genes. Construction of a second language, as noted by then scientists in their publications written over the designs of the first, which was the main reason being that "the most prominent place" he had so long been hidden from the attention of the scientific community.
Investigating the genetic sequences when scientists concluded that some kinds of codons (15% of the total), called Dwan can have two meanings, one of which is associated with the description of the structure of proteins, the other - with the principles of the control genes. Moreover, these two values are closely related to each other as the gene control instructions allow in some cases to stabilize certain areas of complex proteins at the time of manufacture. And that Dwan are the basis structures of the second language by which DNA is recorded in the second information layer.
"For more than 40 years, we believed that the changes only affect the production function of proteins in the genetic code of DNA molecules in the cells," - says Dr. John Stamatoyannopulos (Dr. John Stamatoyannopoulos), professor of medicine and genomics at Washington University, - "Now we know that reading the genetic information, we passed almost half of it, which, in turn, distort the overall picture of our knowledge. Armed with new knowledge about the presence of additional information we will soon be able to fully read all that is written in the DNA, in the most powerful to date, the information storage device,
created by nature itself. »
The value of the work
Knowledge of the fact that DNA molecules contain two types of information at the same time, will enable researchers to more fully recognize the changes in proteins which occur as a result of mutagenic processes affecting DNA structure. Accurate and complete picture of changes in the structure of proteins allow scientists to accurately and clearly define what are the causes of the disease, and what the result of such changes, and to develop new methods of treatment of diseases, based on changes in the part of the DNA information, which only controls the function of genes.
< br> On the other hand, researchers first able to confirm that the genetic mutations that, as previously assumed, could only affect the structure of the basic code of the genetic sequence may also affect the mechanical structure of DNA, which in turn will lead to changes in the reading sequence instructions for the production of proteins, changing the type and amount of the latter.
publication on the website of Leiden Institute of Physics
detailed presentation of the work in the journal PLOS One
That's all, you had a simple service to select Dronk.Ru sophisticated technology. Do not forget to subscribe to our blog, will be much more interesting ...




< br> Why online retailers give the money for the purchase? Review Xiaomi Mi Air Purifier 2 or how to clean the air of a megacity? Return the money - Choosing a cashback service to Aliexpress
Source: geektimes.ru/company/dronk/blog/277306/