783
Los científicos de los Países Bajos han confirmado que la segunda capa de información en el ADN existe
La secuencia de la alternancia de las bases, ciertas moléculas de ADN en cada célula de nuestro cuerpo nos hace como nosotros allí. Al mismo tiempo, varios científicos desde hace mucho tiempo estudiando la posibilidad y la probabilidad de la existencia de lenguaje oculto "alternativo", también codifica la información vital del genoma de una manera diferente y en un nivel diferente. Esta información codificada debe servir como una guía para la acción, con el que las células del cuerpo son capaces de reconocer y manejar la mayor parte de la información en estricta secuencia.
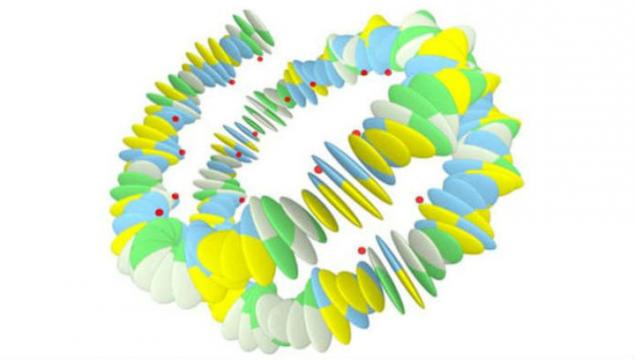
7 de junio de, 2016, las páginas de las publicaciones científicas journals.plos.org fue publicado un grupo de científicos de los Países Bajos, que fueron capaces de demostrar la existencia en nuestro ADN la segunda capa oculta de la información.
Como el ADN que codifica la estructura de la proteína
Como se sabe, la base de ADN - son los bloques de construcción del universo, que causan la posibilidad misma de la existencia y reproducción de la vida en nuestro planeta. Como parte de una molécula de ADN consiste en cuatro bases de nucleótidos especies nitrogenadas, identificado por las letras "A", "T", "C" y "G".
Nuestra cada célula contiene alrededor de 30 miles de genes diferentes, mientras que algunas bacterias suficientes sólo 500 genes. Los genes contienen códigos, según el cual se sintetizan las proteínas y se determinó el orden de los aminoácidos en ellos. Dondequiera que no había células del cuerpo humano, siempre contienen el mismo conjunto de genes. Sin embargo, dependiendo del tipo de célula - células de la piel, nervio o músculo - en el que para sintetizar nuevas proteínas explotan diferentes genes
. cadenas largas de ADN en los cromosomas de las células estrechamente juntos. La disposición compacta de ADN cromosómico se lleva a cabo por proteínas específicas, que se enrollan alrededor de la cadena de ADN. Pero en las proteínas celulares presentes que, para facilitar la síntesis de nuevas proteínas de la código contenida en el ADN, el ADN se transfiere de la forma compacta en la expandido si es necesario. Bajo la influencia de estas proteínas están preparando para dividir cromosomas de las células desplegados y desde entonces ocupada por 10 mil veces más espacio.
Tipo de nucleótidos "A", "T", "C" y "G", son parte de las largas moléculas de ADN están dispuestas en un orden específico para asegurarse de que la codificación de las proteínas durante su síntesis, que se lleva a cabo a partir de 20 diferentes tipos de aminoácidos. DNA en este caso sirven como una matriz - cada proteína corresponde a un gen en el modelo de que la síntesis de los aminoácidos que forman la proteína. Así código genético incorporado en las proteínas, y la secuencia de nucleótidos en el gen determina la secuencia de aminoácidos en la proteína. La analogía más simple - el código Morse, donde los puntos, guiones y conjunto de cierta corresponden a las letras del alfabeto. La secuencia de nucleótidos que puede ser leído por tres a la vez corresponde a la secuencia de aminoácidos de la proteína. En este conjunto de tres nucleótidos se leen a la vez para codificar un único aminoácido. Por ejemplo, el conjunto de nucleótidos codifica la atsidometionin agosto de aminoácidos.
Existen 64 combinaciones de nucleótidos, pero sintetizados sólo 20 diferentes tipos de aminoácidos. Esto significa que algunos secuencia de nucleótidos ternario no se utiliza para la síntesis de aminoácidos, y el procedimiento de síntesis para designar una interrupción. Es un conjunto de nucleótidos de sentido ternarios no ocurren - cada uno realiza una función específica. Hay varios conjuntos de nucleótidos que codifican el mismo aminoácido. El gen más grande se compone de dos millones de nucleótidos, colocados en cada uno de sus hilos, y el más pequeño -. Un millar de
El proceso de lectura de la información genética ( "transcripción"), comienza con el descubrimiento y el despliegue de una pequeña porción de la doble hélice de ADN en el extremo de los cromosomas. El código genético de los cromosomas se copian sitio y luego la creciente a medida que ascienda el proceso de molécula de ARN, y el mecanismo de copia de proteína mueve a lo largo de la cadena de ADN. El proceso de transferir el código genético termina cuando al final del ARN se sintetiza por el llamado grupo amino terminal de - su presencia señala el final del código de la cadena de proteína.
La secuencia de la alternancia de estas bases en las moléculas determina la información que permite que las células de nuestro cuerpo para producir una cantidad fija de proteínas deseadas y mantener otras funciones vitales. Pero, a pesar del hecho de que todas las células de nuestro cuerpo contienen el mismo conjunto de genes, las células se desarrollan de diferentes maneras y se hace sólo una confirmación de que existen diferentes tipos de células de los tejidos que conforman los diversos órganos. Y todo esto una y otra vez hace que los científicos buscan clave adicional a la "excesiva", es decir. E. No es completamente la información decodificada.

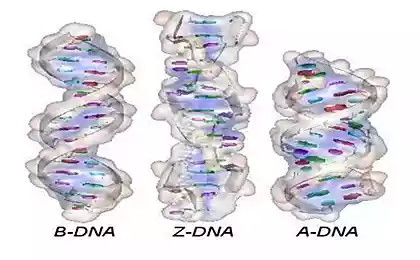
Las moléculas de ADN son extremadamente compactos "empaquetados". Por otra parte se sabe que en su cadena un desenredo de las moléculas contenidas en la misma célula en el promedio es de 2 metros. De acuerdo con la hipótesis, no cambia desde los años 80 del siglo pasado, las propiedades mecánicas de la molécula de ADN determina la forma en que será "eliminado" dentro de la célula. El último estudio realizado por científicos holandeses han confirmado que las moléculas forman cambio resulta en un "plegado" de la hélice de ADN para cambiar. Este hecho permitió hablar de la presencia de una parte del segundo mecanismo de codificación de ADN, que juega en la reproducción de las proteínas de soporte a los procesos no son menos importantes que el código genético subyacente.
El equipo de investigación del Instituto de Física, Leiden (Leiden Institute of Physics) dirigido por Helmut Shisselya (Helmut Schiessel), ha desarrollado un modelo informático, cuyo objetivo era comprobar las hipótesis anteriores y buscar maneras de probar su autenticidad. La base lógica para el modelo fueron las células similares de la levadura de panadero y la levadura de género Schizosaccharomycetes, que comprende una molécula de ADN con la misma secuencia de bases, pero con diferentes propiedades mecánicas.
Como se ha demostrado por el análisis de modelos matemáticos de molécula de ADN de levadura realmente torcido (configurable) y adquirir pequeño tamaño bajo la influencia de diferentes influencias mecánicas en diferentes algoritmos.
Otra evidencia de la existencia del código secundario
El código genético principal contenida en el ADN fue descifrado parcialmente en el 60-s del siglo pasado. Desde entonces, la comunidad científica fue absolutamente seguro de que sólo la información registrada en proteínas de ADN que se producen por las células en el cuerpo como respuesta a eventos externos y estímulos. A pesar del hecho de que con el tiempo, este concepto se ha extendido tanto, los principios básicos de la "sola lengua" en el ADN que codifica permanecen sin cambios.
Sin embargo, la investigación en esta dirección continuó. En 2013, un grupo de científicos de la Universidad de Washington (Universidad de Washington, la Universidad de Washington) fue anunciado por primera vez la existencia del código secundario oculto que determina más directamente el orden de lectura de la secuencia genética de instrucciones básicas contenidas en el ADN. Los resultados de los estudios que han confirmado la validez de la hipótesis se han publicado en las páginas de la Ciencia.
Los investigadores llegaron a la conclusión de que la información contenida en el código genético está escrito en dos idiomas diferentes. El primero describe y regula la estructura y la cantidad de proteína producida por las células, y la segunda determina la secuencia de instrucciones que controlan la lectura de genes. Construcción de una segunda lengua, como se señala a continuación, por los científicos en sus publicaciones escritas en los diseños de la primera, que fue la razón principal es que "el lugar más prominente" que tanto tiempo había sido ocultado a la atención de la comunidad científica.
La investigación de las secuencias genéticas cuando los científicos la conclusión de que algunos tipos de codones (15% del total), llamados Dwan pueden tener dos significados, uno de los cuales está asociado con la descripción de la estructura de las proteínas, el otro - con los principios de los genes de control. Por otra parte, estos dos valores están estrechamente relacionados entre sí como el gen de instrucciones de control permiten en algunos casos para estabilizar ciertas áreas de proteínas complejas en el momento de la fabricación. Dwan y que son las estructuras de base de la segunda lengua en la que se registra ADN en la segunda capa de información.
"Durante más de 40 años, creíamos que los cambios sólo afectan a la función de producción de proteínas en el código genético de las moléculas de ADN en las células", - dice el Dr. John Stamatoyannopulos (Dr. John Stamatoyannopoulos), profesor de medicina y la genómica en la Universidad de Washington, - "Ahora sabemos que la lectura de la información genética, pasamos casi la mitad de ella, lo que, a su vez, distorsionar el panorama general de nuestro conocimiento. Armado con nuevos conocimientos acerca de la presencia de información adicional que pronto será capaz de leer plenamente todo lo que está escrito en el ADN, en el más potente hasta la fecha, el dispositivo de almacenamiento de información de búsqueda creado por la propia naturaleza. »
El valor de la obra
El conocimiento del hecho de que las moléculas de ADN contienen dos tipos de información al mismo tiempo, permitirá a los investigadores a reconocer más completamente los cambios en las proteínas que se producen como resultado de procesos mutagénicos que afectan a la estructura del ADN. imagen precisa y completa de los cambios en la estructura de las proteínas permiten a los científicos a definir con precisión y claridad cuáles son las causas de la enfermedad, y lo que el resultado de tales cambios, y para desarrollar nuevos métodos de tratamiento de enfermedades, en base a los cambios en la parte de la información del ADN, que sólo controla la función de los genes.
< br> Por otro lado, los investigadores primero capaz de confirmar que las mutaciones genéticas que, como se suponía anteriormente, sólo podía afectar a la estructura del código de base de la secuencia genética también pueden afectar a la estructura mecánica de ADN, que a su vez dará lugar a cambios en la secuencia de lectura instrucciones para la producción de proteínas, cambiando el tipo y la cantidad de este último.
publicación en la página web de Leiden Instituto de Física
presentación detallada de los trabajos en la revista PLoS One
Eso es todo, que tenía un servicio simple para seleccionar la tecnología sofisticada Dronk.Ru. No se olvide de suscribirse a nuestro blog, será mucho más interesante ...




< br> ¿por qué los minoristas en línea dar el dinero para la compra? Revisar Xiaomi Mi purificador de aire 2 o la forma de limpiar el aire de una megaciudad? Devolver el dinero - La elección de un servicio de devolución de dinero de los toAliexpress
Fuente: geektimes.ru/company/dronk/blog/277306/

7 de junio de, 2016, las páginas de las publicaciones científicas journals.plos.org fue publicado un grupo de científicos de los Países Bajos, que fueron capaces de demostrar la existencia en nuestro ADN la segunda capa oculta de la información.
Como el ADN que codifica la estructura de la proteína
Como se sabe, la base de ADN - son los bloques de construcción del universo, que causan la posibilidad misma de la existencia y reproducción de la vida en nuestro planeta. Como parte de una molécula de ADN consiste en cuatro bases de nucleótidos especies nitrogenadas, identificado por las letras "A", "T", "C" y "G".
Nuestra cada célula contiene alrededor de 30 miles de genes diferentes, mientras que algunas bacterias suficientes sólo 500 genes. Los genes contienen códigos, según el cual se sintetizan las proteínas y se determinó el orden de los aminoácidos en ellos. Dondequiera que no había células del cuerpo humano, siempre contienen el mismo conjunto de genes. Sin embargo, dependiendo del tipo de célula - células de la piel, nervio o músculo - en el que para sintetizar nuevas proteínas explotan diferentes genes
. cadenas largas de ADN en los cromosomas de las células estrechamente juntos. La disposición compacta de ADN cromosómico se lleva a cabo por proteínas específicas, que se enrollan alrededor de la cadena de ADN. Pero en las proteínas celulares presentes que, para facilitar la síntesis de nuevas proteínas de la código contenida en el ADN, el ADN se transfiere de la forma compacta en la expandido si es necesario. Bajo la influencia de estas proteínas están preparando para dividir cromosomas de las células desplegados y desde entonces ocupada por 10 mil veces más espacio.
Tipo de nucleótidos "A", "T", "C" y "G", son parte de las largas moléculas de ADN están dispuestas en un orden específico para asegurarse de que la codificación de las proteínas durante su síntesis, que se lleva a cabo a partir de 20 diferentes tipos de aminoácidos. DNA en este caso sirven como una matriz - cada proteína corresponde a un gen en el modelo de que la síntesis de los aminoácidos que forman la proteína. Así código genético incorporado en las proteínas, y la secuencia de nucleótidos en el gen determina la secuencia de aminoácidos en la proteína. La analogía más simple - el código Morse, donde los puntos, guiones y conjunto de cierta corresponden a las letras del alfabeto. La secuencia de nucleótidos que puede ser leído por tres a la vez corresponde a la secuencia de aminoácidos de la proteína. En este conjunto de tres nucleótidos se leen a la vez para codificar un único aminoácido. Por ejemplo, el conjunto de nucleótidos codifica la atsidometionin agosto de aminoácidos.
Existen 64 combinaciones de nucleótidos, pero sintetizados sólo 20 diferentes tipos de aminoácidos. Esto significa que algunos secuencia de nucleótidos ternario no se utiliza para la síntesis de aminoácidos, y el procedimiento de síntesis para designar una interrupción. Es un conjunto de nucleótidos de sentido ternarios no ocurren - cada uno realiza una función específica. Hay varios conjuntos de nucleótidos que codifican el mismo aminoácido. El gen más grande se compone de dos millones de nucleótidos, colocados en cada uno de sus hilos, y el más pequeño -. Un millar de
El proceso de lectura de la información genética ( "transcripción"), comienza con el descubrimiento y el despliegue de una pequeña porción de la doble hélice de ADN en el extremo de los cromosomas. El código genético de los cromosomas se copian sitio y luego la creciente a medida que ascienda el proceso de molécula de ARN, y el mecanismo de copia de proteína mueve a lo largo de la cadena de ADN. El proceso de transferir el código genético termina cuando al final del ARN se sintetiza por el llamado grupo amino terminal de - su presencia señala el final del código de la cadena de proteína.
La secuencia de la alternancia de estas bases en las moléculas determina la información que permite que las células de nuestro cuerpo para producir una cantidad fija de proteínas deseadas y mantener otras funciones vitales. Pero, a pesar del hecho de que todas las células de nuestro cuerpo contienen el mismo conjunto de genes, las células se desarrollan de diferentes maneras y se hace sólo una confirmación de que existen diferentes tipos de células de los tejidos que conforman los diversos órganos. Y todo esto una y otra vez hace que los científicos buscan clave adicional a la "excesiva", es decir. E. No es completamente la información decodificada.

Las moléculas de ADN son extremadamente compactos "empaquetados". Por otra parte se sabe que en su cadena un desenredo de las moléculas contenidas en la misma célula en el promedio es de 2 metros. De acuerdo con la hipótesis, no cambia desde los años 80 del siglo pasado, las propiedades mecánicas de la molécula de ADN determina la forma en que será "eliminado" dentro de la célula. El último estudio realizado por científicos holandeses han confirmado que las moléculas forman cambio resulta en un "plegado" de la hélice de ADN para cambiar. Este hecho permitió hablar de la presencia de una parte del segundo mecanismo de codificación de ADN, que juega en la reproducción de las proteínas de soporte a los procesos no son menos importantes que el código genético subyacente.
El equipo de investigación del Instituto de Física, Leiden (Leiden Institute of Physics) dirigido por Helmut Shisselya (Helmut Schiessel), ha desarrollado un modelo informático, cuyo objetivo era comprobar las hipótesis anteriores y buscar maneras de probar su autenticidad. La base lógica para el modelo fueron las células similares de la levadura de panadero y la levadura de género Schizosaccharomycetes, que comprende una molécula de ADN con la misma secuencia de bases, pero con diferentes propiedades mecánicas.
Como se ha demostrado por el análisis de modelos matemáticos de molécula de ADN de levadura realmente torcido (configurable) y adquirir pequeño tamaño bajo la influencia de diferentes influencias mecánicas en diferentes algoritmos.
Otra evidencia de la existencia del código secundario
El código genético principal contenida en el ADN fue descifrado parcialmente en el 60-s del siglo pasado. Desde entonces, la comunidad científica fue absolutamente seguro de que sólo la información registrada en proteínas de ADN que se producen por las células en el cuerpo como respuesta a eventos externos y estímulos. A pesar del hecho de que con el tiempo, este concepto se ha extendido tanto, los principios básicos de la "sola lengua" en el ADN que codifica permanecen sin cambios.
Sin embargo, la investigación en esta dirección continuó. En 2013, un grupo de científicos de la Universidad de Washington (Universidad de Washington, la Universidad de Washington) fue anunciado por primera vez la existencia del código secundario oculto que determina más directamente el orden de lectura de la secuencia genética de instrucciones básicas contenidas en el ADN. Los resultados de los estudios que han confirmado la validez de la hipótesis se han publicado en las páginas de la Ciencia.
Los investigadores llegaron a la conclusión de que la información contenida en el código genético está escrito en dos idiomas diferentes. El primero describe y regula la estructura y la cantidad de proteína producida por las células, y la segunda determina la secuencia de instrucciones que controlan la lectura de genes. Construcción de una segunda lengua, como se señala a continuación, por los científicos en sus publicaciones escritas en los diseños de la primera, que fue la razón principal es que "el lugar más prominente" que tanto tiempo había sido ocultado a la atención de la comunidad científica.
La investigación de las secuencias genéticas cuando los científicos la conclusión de que algunos tipos de codones (15% del total), llamados Dwan pueden tener dos significados, uno de los cuales está asociado con la descripción de la estructura de las proteínas, el otro - con los principios de los genes de control. Por otra parte, estos dos valores están estrechamente relacionados entre sí como el gen de instrucciones de control permiten en algunos casos para estabilizar ciertas áreas de proteínas complejas en el momento de la fabricación. Dwan y que son las estructuras de base de la segunda lengua en la que se registra ADN en la segunda capa de información.
"Durante más de 40 años, creíamos que los cambios sólo afectan a la función de producción de proteínas en el código genético de las moléculas de ADN en las células", - dice el Dr. John Stamatoyannopulos (Dr. John Stamatoyannopoulos), profesor de medicina y la genómica en la Universidad de Washington, - "Ahora sabemos que la lectura de la información genética, pasamos casi la mitad de ella, lo que, a su vez, distorsionar el panorama general de nuestro conocimiento. Armado con nuevos conocimientos acerca de la presencia de información adicional que pronto será capaz de leer plenamente todo lo que está escrito en el ADN, en el más potente hasta la fecha, el dispositivo de almacenamiento de información de búsqueda creado por la propia naturaleza. »
El valor de la obra
El conocimiento del hecho de que las moléculas de ADN contienen dos tipos de información al mismo tiempo, permitirá a los investigadores a reconocer más completamente los cambios en las proteínas que se producen como resultado de procesos mutagénicos que afectan a la estructura del ADN. imagen precisa y completa de los cambios en la estructura de las proteínas permiten a los científicos a definir con precisión y claridad cuáles son las causas de la enfermedad, y lo que el resultado de tales cambios, y para desarrollar nuevos métodos de tratamiento de enfermedades, en base a los cambios en la parte de la información del ADN, que sólo controla la función de los genes.
< br> Por otro lado, los investigadores primero capaz de confirmar que las mutaciones genéticas que, como se suponía anteriormente, sólo podía afectar a la estructura del código de base de la secuencia genética también pueden afectar a la estructura mecánica de ADN, que a su vez dará lugar a cambios en la secuencia de lectura instrucciones para la producción de proteínas, cambiando el tipo y la cantidad de este último.
publicación en la página web de Leiden Instituto de Física
presentación detallada de los trabajos en la revista PLoS One
Eso es todo, que tenía un servicio simple para seleccionar la tecnología sofisticada Dronk.Ru. No se olvide de suscribirse a nuestro blog, será mucho más interesante ...




< br> ¿por qué los minoristas en línea dar el dinero para la compra? Revisar Xiaomi Mi purificador de aire 2 o la forma de limpiar el aire de una megaciudad? Devolver el dinero - La elección de un servicio de devolución de dinero de los toAliexpress
Fuente: geektimes.ru/company/dronk/blog/277306/