Жизнь — интересная!
Подписывайтесь на нашу группу в Telegram и Facebook, чтобы быть в сообществе единомышленников, находить вдохновение и не пропускать свежие и удивительные статьи с bashny.net.
782
0.2
2016-06-16
Ученые из Нидерландов подтвердили: второй информационный слой в ДНК существует
Последовательность чередования оснований, определенная в молекуле ДНК, находящихся в каждой клетке нашего тела делает нас с вами такими, как мы есть. Вместе с тем, ряд ученых уже достаточно продолжительное время изучают возможность и вероятность существования «альтернативного» скрытого языка, также кодирующего жизненно важную информацию генома но другим способом и на другом уровне. Эта закодированная информация должна служить своего рода руководством к действию, используя которое клетки нашего организма получают возможность распознать и обработать основной массив информации в строго определенной последовательности.
7 июня 2016 года на страницах научного издания journals.plos.org была опубликована работа группы ученых из Нидерландов, сумевших доказать существование в наших ДНК второго скрытого информационного слоя.
Как ДНК кодируют структуру белков
Как известно, основания ДНК — те строительные кирпичики мироздания, которые обуславливают саму возможность существования и воспроизведения всего живого на нашей планете. В составе молекулы ДНК входит четыре вида азотсодержащих нуклеотидных оснований, обозначаемые буквами «А», «Т», «С» и «G».
Каждая наша клетка содержит около 30 тысяч различных генов, в то время как некоторым бактериям достаточно всего 500 генов. В генах содержатся коды, согласно которым синтезируются белки и определяется порядок расположения в них аминокислот. В каком бы месте человеческого тела ни находились клетки, они всегда содержат один и тот же набор генов. Однако в зависимости от типа клеток — клеток кожи, нервных или мышечных — в них для синтеза новых белков задействуются различные гены.
Длинные цепочки ДНК в хромосомах клетки плотно сжаты. Компактное расположение ДНК в хромосомах осуществляется за счет особых белков, вокруг которых наматываются нити ДНК. Но в клетке присутствуют белки, которые, чтобы облегчить синтез новых белков согласно содержащемуся в ДНК коду, при необходимости переводят ДНК из компактной формы в развернутую. Под воздействием этих белков готовящиеся к делению клетки хромосомы развертываются и с этого момента занимают в 10 тысяч раз больше места.
Нуклеотиды типа «А», «Т», «С» и «G», входящие в состав длинных молекул ДНК, располагаются в определенном порядке, чтобы обеспечивать кодирование белков при их синтезе, который происходит из 20 различных видов аминокислот. ДНК при этом выполняют роль матрицы — каждому белку соответствует свой ген, по образцу которого осуществляется синтез аминокислот, образующих нужный белок. Таким образом генетический код воплощается в белках, и последовательность нуклеотидов в гене определяет последовательность аминокислот в белке. Простейшая аналогия — азбука Морзе, где точки, тире и их совокупность соответствуют определенным буквами алфавита. Последовательность нуклеотидов, которые считываются по три за один раз, соответствует последовательности аминокислот в белке. При этом набор из трех нуклеотидов, которые считываются за один раз, кодирует одну аминокислоту. Так, например, набор нуклеотидов AUG кодирует аминокислоту ацидометионин.
Существуют 64 комбинации нуклеотидов, однако синтезируются всего 20 различных видов аминокислот. Это означает, что некоторые троичные последовательности нуклеотидов используются не для синтеза аминокислот, а для обозначения прерывания процедуры синтеза. Совершенно бессмысленных наборов троичных нуклеотидов не бывает — каждый из них выполняет какую-то определенную функцию. Существует и несколько наборов нуклеотидов, которые кодируют одни и те же аминокислоты. Самый крупный ген состоит из двух миллионов нуклеотидов, размещенных на каждой из его нитей, а самый маленький — из одной тысячи.
Процесс считывания генетической информации («транскрипция»), начинается с открытия и развертывания небольшой части двойной спирали ДНК в конце хромосомы. Генетические коды этого участка хромосомы копируются затем на растущую по мере продвижения процесса копирования молекулу РНК, при этом белковый копирующий механизм продвигается вдоль нити ДНК. Процесс переноса генетического кода заканчивается, когда на конце РНК синтезируется так называемая терминальная группа аминокислот — ее присутствие сигнализирует об окончании белковой цепочки данного кода.
Последовательность чередования этих оснований в молекулах определяет ту информацию, которая позволяет клеткам нашего организма вырабатывать строго определенное количество нужных белков и поддерживать прочие жизненно важные функции. Но, несмотря на тот факт, что все клетки нашего тела содержат один и тот же набор генов, сами клетки развиваются по-разному и простейшим подтверждением этому становится существование клеток тканей различных типов, из которых состоят различные органы. И все это еще и еще раз заставляет ученых искать дополнительный ключ к «избыточной», т. е. пока не до конца расшифрованной информации.

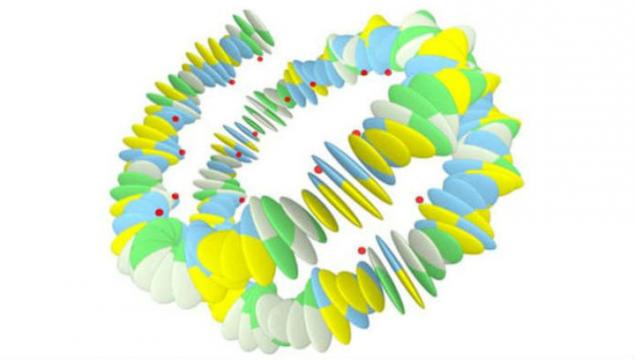
Молекулы ДНК предельно компактно «упакованы». С другой стороны известно, что в своем распутанном виде цепочка из молекул, содержащихся в одной клетке, в среднем, составляет 2 метра. Согласно гипотезе, не менявшейся начиная с 80-х годах прошлого века, механические свойства молекулы ДНК определяют то, каким образом она будет «свернута» внутри клетки. Новейшие исследования голландских ученых подтвердили: изменение формы молекулы приводит к изменению «свертки» спирали ДНК. Именно этот факт позволил говорить о наличии в составе ДНК второго механизма кодирования, играющего в процессах поддержки воспроизводства белков не меньшее значение, чем основной генетический код.
Исследовательская группа из Лейденского института физики (Leiden Institute of Physics) под руководством Хельмута Шисселя (Helmut Schiessel), разработала компьютерную модель, назначением которой стала проверка описанной выше гипотезы и поиск способов доказательства ее достоверности. Логической основой для рассматриваемой модели послужили схожие клетки хлебопекарных дрожжей и дрожжей рода Schizosaccharomycetes, содержащих молекулу ДНК с одинаковой последовательностью оснований, но с различными механическими свойствами.
Как продемонстрировал математической анализ модели, молекулы ДНК дрожжей действительно скручиваются (конфигурируются) и приобретают компактный размер под влиянием разных механических воздействий по-разным алгоритмам.
Другое подтверждение существования вторичного кода
Основной генетический код, содержащийся в ДНК был частично расшифрован еще в 60-х годах прошлого века. С того момента научное сообщество было абсолютно уверено в том, что в ДНК записана лишь информация о белках, которые вырабатываются клетками организма как ответ на внешние события и раздражители. Несмотря на то, что со временем эта концепция была несколько расширена, основные принципы «одноязычного» кодирования в ДНК оставались неизменными.
Вместе с тем, исследования в этом направлении продолжались. В 2013 году группа ученых из Вашингтонского университета (University of Washington, UW) было впервые заявлено о существовании скрытого вторичного кода, самым непосредственным образом определяющего порядок считывания последовательности основных генетических инструкций, содержащихся в ДНК. Результаты исследований, подтвердивших истинность гипотезы были опубликованы на страницах Science.
Ученые пришли к выводу, что информация в генетическом коде записана на двух различных языках. Первый описывает и регламентирует структуру и количество вырабатываемых клетками белков, второй определяет последовательность выполнения инструкций, управляющих считыванием генов. Конструкции второго языка, как отмечали тогда ученые в своей публикации записаны поверх конструкций первого, что и явилось главной причиной того, что находясь «на самом видном месте» он столь длительное время был скрыт от внимания научного сообщества.
Исследуя генетические последовательности, ученые тогда пришли к выводу, что некоторые виды кодонов (до 15% от их общего количества), названные дуонами, могут иметь два значения, одно из которых связано с описанием структуры белков, другое — с принципами управления генами. Более того, эти два значения очень тесно связаны друг с другом, поскольку инструкции генного контроля в некоторых случаях позволяют стабилизировать определенные участки сложнейших белков в момент их производства. И именно дуоны составляют основу конструкций второго языка, с помощью которого в ДНК записан второй слой информации.
«Более 40 лет мы считали, что все изменения в генетическом коде молекул ДНК воздействуют лишь на функции производства белков в клетках» — рассказывает доктор Джон Стаматояннопулос (Dr. John Stamatoyannopoulos), профессор медицины и геномики в Вашингтонском университете, — «Теперь же мы знаем, что, читая генетическую информацию, мы пропускали почти ее половину, что, в свою очередь, искажало общую картину наших знаний. Вооружившись новыми знаниями о наличии дополнительной информации, скоро мы сможем полностью читать все, что записано в ДНК, в самом мощном на сегодняшний день устройстве хранения информации, созданном самой природой».
Значение работы
Знание того факта, что молекулы ДНК содержат одновременно два вида информации, даст возможность ученым более полно узнавать те изменения в белках, которые произойдут в результате мутагенных процессов, затрагивающих структуру ДНК. Точная и полная картина изменений в структуре белков позволит ученым точно и однозначно определить, какие болезни оказываются причинами, а какие следствием таких изменений и выработать новые методы лечения заболеваний, основанные на изменениях той части информации ДНК, которая управляет только функциями генов.
С другой стороны, ученым впервые удалось подтвердить, что генетические мутации, которые, как предполагали ранее, могли влиять только на структуру основного кода генетической последовательности, могут отразиться и на механической структуре ДНК, что, в свою очередь, повлечет за собой изменения в последовательности считывания инструкций по производству белков, изменению типа и количества последних.
Публикация на сайте Лейденского Института Физики
Подробное изложение работы в журнале PLOS One
На этом всё, с вами был простой сервис для выбора сложной техники Dronk.Ru. Не забывайте подписываться на наш блог, будет ещё много интересного…

Источник: geektimes.ru/company/dronk/blog/277306/

7 июня 2016 года на страницах научного издания journals.plos.org была опубликована работа группы ученых из Нидерландов, сумевших доказать существование в наших ДНК второго скрытого информационного слоя.
Как ДНК кодируют структуру белков
Как известно, основания ДНК — те строительные кирпичики мироздания, которые обуславливают саму возможность существования и воспроизведения всего живого на нашей планете. В составе молекулы ДНК входит четыре вида азотсодержащих нуклеотидных оснований, обозначаемые буквами «А», «Т», «С» и «G».
Каждая наша клетка содержит около 30 тысяч различных генов, в то время как некоторым бактериям достаточно всего 500 генов. В генах содержатся коды, согласно которым синтезируются белки и определяется порядок расположения в них аминокислот. В каком бы месте человеческого тела ни находились клетки, они всегда содержат один и тот же набор генов. Однако в зависимости от типа клеток — клеток кожи, нервных или мышечных — в них для синтеза новых белков задействуются различные гены.
Длинные цепочки ДНК в хромосомах клетки плотно сжаты. Компактное расположение ДНК в хромосомах осуществляется за счет особых белков, вокруг которых наматываются нити ДНК. Но в клетке присутствуют белки, которые, чтобы облегчить синтез новых белков согласно содержащемуся в ДНК коду, при необходимости переводят ДНК из компактной формы в развернутую. Под воздействием этих белков готовящиеся к делению клетки хромосомы развертываются и с этого момента занимают в 10 тысяч раз больше места.
Нуклеотиды типа «А», «Т», «С» и «G», входящие в состав длинных молекул ДНК, располагаются в определенном порядке, чтобы обеспечивать кодирование белков при их синтезе, который происходит из 20 различных видов аминокислот. ДНК при этом выполняют роль матрицы — каждому белку соответствует свой ген, по образцу которого осуществляется синтез аминокислот, образующих нужный белок. Таким образом генетический код воплощается в белках, и последовательность нуклеотидов в гене определяет последовательность аминокислот в белке. Простейшая аналогия — азбука Морзе, где точки, тире и их совокупность соответствуют определенным буквами алфавита. Последовательность нуклеотидов, которые считываются по три за один раз, соответствует последовательности аминокислот в белке. При этом набор из трех нуклеотидов, которые считываются за один раз, кодирует одну аминокислоту. Так, например, набор нуклеотидов AUG кодирует аминокислоту ацидометионин.
Существуют 64 комбинации нуклеотидов, однако синтезируются всего 20 различных видов аминокислот. Это означает, что некоторые троичные последовательности нуклеотидов используются не для синтеза аминокислот, а для обозначения прерывания процедуры синтеза. Совершенно бессмысленных наборов троичных нуклеотидов не бывает — каждый из них выполняет какую-то определенную функцию. Существует и несколько наборов нуклеотидов, которые кодируют одни и те же аминокислоты. Самый крупный ген состоит из двух миллионов нуклеотидов, размещенных на каждой из его нитей, а самый маленький — из одной тысячи.
Процесс считывания генетической информации («транскрипция»), начинается с открытия и развертывания небольшой части двойной спирали ДНК в конце хромосомы. Генетические коды этого участка хромосомы копируются затем на растущую по мере продвижения процесса копирования молекулу РНК, при этом белковый копирующий механизм продвигается вдоль нити ДНК. Процесс переноса генетического кода заканчивается, когда на конце РНК синтезируется так называемая терминальная группа аминокислот — ее присутствие сигнализирует об окончании белковой цепочки данного кода.
Последовательность чередования этих оснований в молекулах определяет ту информацию, которая позволяет клеткам нашего организма вырабатывать строго определенное количество нужных белков и поддерживать прочие жизненно важные функции. Но, несмотря на тот факт, что все клетки нашего тела содержат один и тот же набор генов, сами клетки развиваются по-разному и простейшим подтверждением этому становится существование клеток тканей различных типов, из которых состоят различные органы. И все это еще и еще раз заставляет ученых искать дополнительный ключ к «избыточной», т. е. пока не до конца расшифрованной информации.

Молекулы ДНК предельно компактно «упакованы». С другой стороны известно, что в своем распутанном виде цепочка из молекул, содержащихся в одной клетке, в среднем, составляет 2 метра. Согласно гипотезе, не менявшейся начиная с 80-х годах прошлого века, механические свойства молекулы ДНК определяют то, каким образом она будет «свернута» внутри клетки. Новейшие исследования голландских ученых подтвердили: изменение формы молекулы приводит к изменению «свертки» спирали ДНК. Именно этот факт позволил говорить о наличии в составе ДНК второго механизма кодирования, играющего в процессах поддержки воспроизводства белков не меньшее значение, чем основной генетический код.
Исследовательская группа из Лейденского института физики (Leiden Institute of Physics) под руководством Хельмута Шисселя (Helmut Schiessel), разработала компьютерную модель, назначением которой стала проверка описанной выше гипотезы и поиск способов доказательства ее достоверности. Логической основой для рассматриваемой модели послужили схожие клетки хлебопекарных дрожжей и дрожжей рода Schizosaccharomycetes, содержащих молекулу ДНК с одинаковой последовательностью оснований, но с различными механическими свойствами.
Как продемонстрировал математической анализ модели, молекулы ДНК дрожжей действительно скручиваются (конфигурируются) и приобретают компактный размер под влиянием разных механических воздействий по-разным алгоритмам.
Другое подтверждение существования вторичного кода
Основной генетический код, содержащийся в ДНК был частично расшифрован еще в 60-х годах прошлого века. С того момента научное сообщество было абсолютно уверено в том, что в ДНК записана лишь информация о белках, которые вырабатываются клетками организма как ответ на внешние события и раздражители. Несмотря на то, что со временем эта концепция была несколько расширена, основные принципы «одноязычного» кодирования в ДНК оставались неизменными.
Вместе с тем, исследования в этом направлении продолжались. В 2013 году группа ученых из Вашингтонского университета (University of Washington, UW) было впервые заявлено о существовании скрытого вторичного кода, самым непосредственным образом определяющего порядок считывания последовательности основных генетических инструкций, содержащихся в ДНК. Результаты исследований, подтвердивших истинность гипотезы были опубликованы на страницах Science.
Ученые пришли к выводу, что информация в генетическом коде записана на двух различных языках. Первый описывает и регламентирует структуру и количество вырабатываемых клетками белков, второй определяет последовательность выполнения инструкций, управляющих считыванием генов. Конструкции второго языка, как отмечали тогда ученые в своей публикации записаны поверх конструкций первого, что и явилось главной причиной того, что находясь «на самом видном месте» он столь длительное время был скрыт от внимания научного сообщества.
Исследуя генетические последовательности, ученые тогда пришли к выводу, что некоторые виды кодонов (до 15% от их общего количества), названные дуонами, могут иметь два значения, одно из которых связано с описанием структуры белков, другое — с принципами управления генами. Более того, эти два значения очень тесно связаны друг с другом, поскольку инструкции генного контроля в некоторых случаях позволяют стабилизировать определенные участки сложнейших белков в момент их производства. И именно дуоны составляют основу конструкций второго языка, с помощью которого в ДНК записан второй слой информации.
«Более 40 лет мы считали, что все изменения в генетическом коде молекул ДНК воздействуют лишь на функции производства белков в клетках» — рассказывает доктор Джон Стаматояннопулос (Dr. John Stamatoyannopoulos), профессор медицины и геномики в Вашингтонском университете, — «Теперь же мы знаем, что, читая генетическую информацию, мы пропускали почти ее половину, что, в свою очередь, искажало общую картину наших знаний. Вооружившись новыми знаниями о наличии дополнительной информации, скоро мы сможем полностью читать все, что записано в ДНК, в самом мощном на сегодняшний день устройстве хранения информации, созданном самой природой».
Значение работы
Знание того факта, что молекулы ДНК содержат одновременно два вида информации, даст возможность ученым более полно узнавать те изменения в белках, которые произойдут в результате мутагенных процессов, затрагивающих структуру ДНК. Точная и полная картина изменений в структуре белков позволит ученым точно и однозначно определить, какие болезни оказываются причинами, а какие следствием таких изменений и выработать новые методы лечения заболеваний, основанные на изменениях той части информации ДНК, которая управляет только функциями генов.
С другой стороны, ученым впервые удалось подтвердить, что генетические мутации, которые, как предполагали ранее, могли влиять только на структуру основного кода генетической последовательности, могут отразиться и на механической структуре ДНК, что, в свою очередь, повлечет за собой изменения в последовательности считывания инструкций по производству белков, изменению типа и количества последних.
Публикация на сайте Лейденского Института Физики
Подробное изложение работы в журнале PLOS One
На этом всё, с вами был простой сервис для выбора сложной техники Dronk.Ru. Не забывайте подписываться на наш блог, будет ещё много интересного…

 |  |  | Почему интернет-магазины отдают деньги за покупки? | Обзор Xiaomi Mi Air Purifier 2 или как очистить воздух мегаполиса? | Верните свои деньги — Выбираем кэшбэк-сервис для Aliexpress |
Источник: geektimes.ru/company/dronk/blog/277306/
Портал БАШНЯ. Копирование, Перепечатка возможна при указании активной ссылки на данную страницу.