1064
Ант на пляжі на основі Herbert Simon
Зараз наша команда Candango Games працює на грі жахів. Ми плануємо познайомитись з ним найближчим часом (до речі, щоб створити його, я навчаю складові елементи страху). Тож одна з найбільших речей, які я хотів зробити в цій грі, щоб мати повну систему присутності. І, як ми знаємо, найважливіше для реалізації цього завдання – створення якісного штучного інтелекту.
9462791
Думаючи про те, як це зробити, я зрозумів, що для створення штучного інтелекту підійде вишуканий підхід. Про це
Деякі теорії про знання говорять, що ми не бачимо реальності, як це таке. Замість ми бачимо віртуалізовану копію. Дійсність створюється і обробляється нашим мозку. Ми бачимо той самий суд у знаменитому Плато «Міф печери».
На перший погляд, це, здається, збігається з тим, як ми підходимо до реалізації AI: ми програмуємо агентів для отримання та обробки інформації про світ, щоб потім приймати рішення на основі даних. Таким чином, ми переводимо наше бачення світу на штучний інтелект – охочі агенти, щоб діяти як вони будуть в реальному мозку людини. Такий підхід не зовсім неспроможний.
Проте в рію відеоігри є одна деталь: є еквівалент «реального світу» вже віртуальний, тобто це чиста інформація. Чому переоцінювати її в мозок агентів, а потім змусити мозок обробляти цю інформацію? Чому ми намагаємося перенести світ на мозок агента, коли ми можемо зробити навпаки: перенести мозок агента в світ? І я вирішив це зробити: світ подумати, буде розумним і зрозумілим. Мир, не агенти.
Ми приймаємо рішення, щоб піти в цьому напрямку, оскільки цей підхід був краще підходить для нашої мети побудови AI для хорошої динаміки ігор. Уявіть наступну послідовність гри:
У деяких будівлях. Як ви запускаєте передпокій, ви помітите відкриті двері, що ведеться в спальню. Ви запустіть в там і заблокуйте двері. Стеблони починають перерватися в замок, і ви усвідомите, що незабаром вони вводять в цю кімнату. Шукаєте, ви бачите закрите вікно, ліжко і шафа. Ви відкриєте вікно і приховуєте під ліжком. Відкривається двері, одна з гонщиків надходить в приміщення, йде до відкритого вікна і виходить. Він потім подрібнює до своїх акомпалісів, які ви побігли, стрибає з вікна і зникне в темний. Цього разу ви зуміли втекти.
Це те, що можна зробити з простим кодом, використовуючи базовий евристичний підхід «переклад мозку в світ». Код простий як Pacman-код. Особливість полягає в тому, що агент (сталькер) не має уявлення про те, що йде за закритими дверима, він не знає, що вікно є, що це означає, де він веде, або чи це ведеться в будь-якій точці світу. Агент не помітить всіх цих речей і ідей. Все, що він слідує знакам і інструкціям.
Уявіть наступні події:
Ви сидите на комп'ютері, створюючи гру, і раптом ви знаходитесь на кухні перед відкритим холодильником. Ви шукаєте щось або зайти на комп’ютер з чашкою кави, навіть якщо ви не відчували себе, як кава для пиття.
Як це сталося? Чи знаєте ви, що це? Чому б ви робили це?
Так в цьому випадку: «розумний» не є агентом, але вікно, а мозок належить не до агента, а до світу. Вікно розповідає агента, що робити, де шукати, куди піти, що розповісти інші агенти і як показати «хі» рішення гравця. Коли агент ходить в кімнату, то розповідають йому, що робити. Постільна кімната, в якій гравець приховується, запрошує на нього подивитися. У шафі також можна знайти всередині. Недавній відкритий вікно говорить його, щоб піти поза. Після отримання цих пропозицій агент робить розумне рішення на основі пріоритету цих завдань.
Взаємодія з вікном, гравець збільшує своє значення, в зв'язку з чим підвищується пріоритет цього завдання, а агент обирає його, а не інші варіанти - це регулюється за сценаріями вікна. Але, наприклад, якщо гравець ховався в шафі і сиділи там спокійно, то пріоритет завдання «блок в шафу» автоматично знижується, а отже, агент обирає варіант «погляд під ліжком», а гравець знову матиме можливість втекти. Все залежить від вибору дизайнера ігор: він вирішує, як кожен елемент повинен працювати.

Однак не всі завдання надходять з зовнішніх джерел. Внутрішні або прикріплені елементи до агента також можуть надати завдання. Наприклад, якщо агент має аптечку і травмується, то аптечка (який йому) замовляє агента його використання. Значення цього завдання буде безпосередньо пропорційно вираженості травми. У той же час система травми агента (внутрішня) замовляє його від того, що викликає травму агента. Скоріш за все, в цій ситуації агент, заснований на значенні кожного завдання, зникне і знайдеться безпечне місце, загоює рану і або продовжує боротьбу або відступати. Це нескладно реалізувати: потрібно лише надати першу допомогу набору знань, які в поточній ситуації без лікування, не можна приймати дії, що припинення лікування призведе до вразливості агента. Таким чином, наведено пріоритети завдань.
Це дуже основа вишуканого підходу, і я дійсно люблю його. Ми змогли зробити повноцінну систему присутності, ми зробили її надійним, складним, але в той же час дуже простими в плані коду. Крім того, ця система досить універсальна, що дозволяє легко змінювати, змінювати і додавати завдання. Наприклад, ми можемо створити нове джерело завдань у вигляді автомобіля, блокування або сходів без зміни програми агента. Або ми можемо змінити або покращувати системи, які контролюють лише конкретне завдання або частину середовища мозку, не впливаючи на інші елементи. Уміння налаштувати поведінку, здається, дуже цікавим для створення хорошої гри – особливо для гри жахів, адже гравець іноді потрапляє до жертви дій навколишнього середовища.
Тоді я хотів додати системи розпізнавання тексту, щоб побачити, як він може використовуватися в вишуканому підході. Текстова інструкція, як «введення блакитного кульки в зеленій коробці», надана відповідним непрогравачним символам, буде ідентифікована зеленою коробкою і блакитним кулькою, відповідно, і вони будуть інструктувати агента, щоб підібрати м'яч, з'ясувати де його. Це дає враження, що агент розуміє, що він говорить його, щоб зробити.
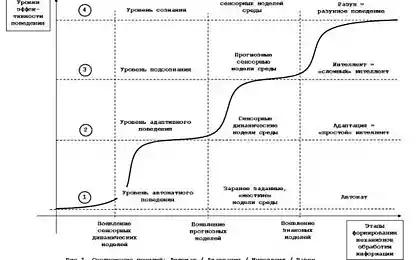
До тих пір все виглядало дуже красиво. Після закінчення початкового етапу створення ігор я знайшов, що ці завдання повинні бути реалізовані в коді. Ми в фазі виконання. На даний момент система виглядає так:
 р.
р.
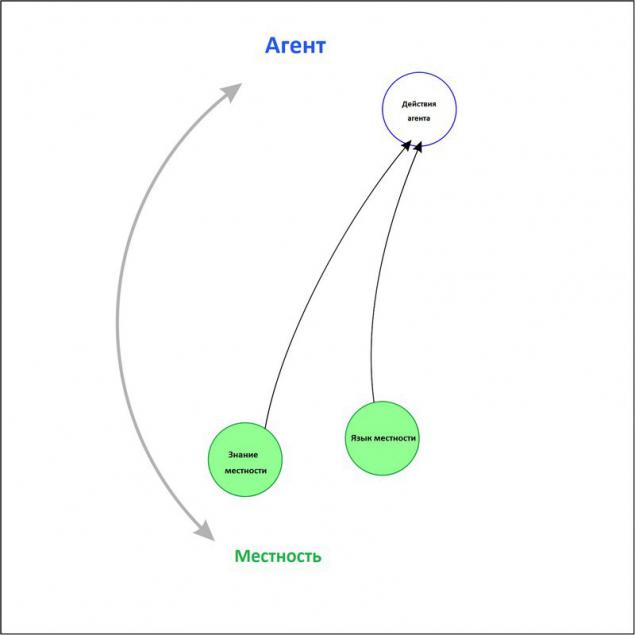
Поведінка - взаємодія агента з навколишнім середовищем.
Коли я почав програмування цієї системи в Уніформа Концепції, кожен день я повинен присвятити деякий час основи AI. Не просто AI для відеоігри, але AI в цілому. Я просто хотів, щоб переконатися, що я не був, що мій час, винахідивши колесо я був придуманий.
Я почав вчитися деякі дуже цікаві концепції, а також старі дослідження і експерименти, деякі з яких половина століття. Серед них я можу назвати «Систему переглядів» в експерименті Хайдера і Сіммелья з анімацією (1944 р.), «Науки штучного» (1969) з анемекдотом «Анти на пляжі», а також Kuleshov Experiment (оригінальні дати з 1919 р.), що, думаю, в той час не відповідає часу. Згодом ця інформація почала захопити мене більше і повністю позбавив мене від сну.
Поки я зрозумів, що починаючи з іншого кінця, полюючись, я прийшов до цього знання. Я пішов з дещо різною перспективою: Я хотів створити розумний світ, тому що я думав, що це було дуже ефективно, тому що ми віртуалізації світу ми живемо, і агент живе в віртуальному світі. Але це просто підстава, щоб зробити щось більш потужним і серйозним. Але тоді я не бачив цих можливостей.
Всі ці дослідження погоджуються на одне: простий комбінований комплекс дає комплексний результат, який наш мозок інтерпретує як ще більш складний і розумний, ніж це дійсно.
Звичайно, наша мета на Game Design була для AI, щоб зробити агенти з'являються складними та інтелектуальними за допомогою різних хитрощів. Але що я зацікавив, що не був цей базовий підхід, але формула Проста проти комплексу, яка була повторена в кожному з цих експериментів, і це відповідало всім дослідженням, незалежно від їх специфіки.
Після того, як я помітив, що цей аспект може бути присутнім в багатьох ситуаціях, але я не знаю про це. Дуже важливо, я шукав аналогії в проміжках в нашій системі AI. І тоді я почав запитати багато питань про проблеми дизайну і намагатися відповісти на них за допомогою тієї ж системи і формули.
• Якщо завдання створюються в модульній системі і мають доступ до інформації агента для визначення інструкцій і завдань, чому не збільшити кількість такої інформації і зробити її більш детальним? Подаруйте свою особистість, фон, настрій, почуття, соціальну динаміку, а потім створити завдання для аналізу цієї інформації замість фокусування тільки на здоров'я і інвентаризації.
Поведінка для створення персонажа, який народився в джунглі і знає, де знайти воду і харчування, і персонажі з міста без таких знань можуть бути просто фонові перевірки, проведені джерелом завдань, які надсилають наступні завдання після пошуку води і їжі. Якщо характер звідти, то завдання слід надати, якщо не звідти, завдання не надається.
• Чому я можу розглянути конкретну сторону світу і не розглянути абстрактні речі, які здаються там, але ми не можемо бачити їх? Що таке драма, невідомого, комедії? Чому ми повинні створювати поведінки, які приходять з речей, а не людей та ідей? Чому не створювати завдання з групи речей, науки та сюжетної сцени?
Ми можемо зробити динамічні сюжетні сцени, щоб оживити шаблони поведінки. Сцени, які доступні для конкретних персонажів і з'являються в залежності від того, як кожен символ відповідає ролі.
Ситуації можна планувати, прив'язувати до місця або запускати в залежності від ситуації і конкретної точки розвитку ділянки. Наприклад, для створення спільної сцени фільму для зомбі, де один з персонажів був укус або поранений, а інші персонажі стверджують, що чи допомогти йому, залишити його або просто вбити його і боротися з кінцям: ситуація не залежить від того, хто був укус або поранений. Джерело завдання (повідомлення) просто оцінює, як кожен характер вписується в свою роль і пропонує їм різні завдання для кожної ролі, що призводить до розвитку ділянки природно, на основі їх рішень. В іншому випадку ми можемо мати клімакс для будь-якого з персонажів, переглядаючи з боковини, як гравець поводиться в ключові ситуації, щоб змінити ділянку трилера.
• Чому не використовувати ці динамічні сюжетні лінії і продовжити їх вплив на подальші події з можливістю значної зміни сюжету?
Якщо гравець схвалює всюди і помітить шини на машині неплеєрного персонажа, він не відображатиме стандартну сюжетну сцену «Party». Замість цього непрогравачного персонажа буде танцювати з деякими романтичними намірами (відповіді в танцювальній сцені він буде замінений на інший непрогравачний характер зі списку), а любовний трикутник змінить ситуацію між двома героями з роз’ясненням ідентичностей, що призведе до деяких інших незвичайних результатів.
Або якщо символ, який бере на себе роль лідера групи, що втратив у степу, починає втратити свої розуми або потрапляє в розпад, абстрактна ідея/соціальна динаміка Лідерства Групи бере над непрогравачним характером і несе відповідальність за їх рішення. Аналогічно, якщо група незадоволена рішеннями лідера, соціальна динаміка даної ситуації може призвести до нового динамічного сюжету, де вони вперше борються з системою, а потім порушують в два табори.
• А ось чому зупинитися? Чому не дайте сюжетні лінії визначити, які ролі гравець вибирає, а потім пошиття ситуації для кожного гравця?
У сюжеті вибирається характер ролі другого лідера (або вона відкрита для того, щоб визначити, чи підходить гравець для цієї ролі або ні), після чого інші висловлюють свою підтримку на одну сторону, а хтось висловлює намір зупинити боротьбу і об'єднатися.
• Але персонажі можуть боротися навіть під час розкопки зомбі, або під час аргументу над тим, хто є лідером, або громада може навіть прийняти рішення відмовитися від пораненого лідера. Тому не вдосконалювати систему прийняття рішень і додати багатозадачність характеру?
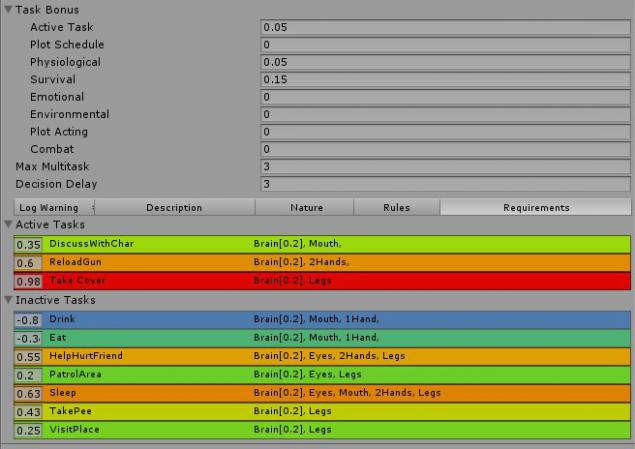
Агенти мають «психо-ресурси», які дозволяють їм вибрати декілька завдань одночасно (і допитати ті рішення на основі групування задач, а не просто виконувати завдання одним шляхом): обмеження концентрацій, руки, ноги, рот, очі ...
Якщо поведінка завжди є взаємодією агента і навколишнього середовища, чому не поширюється значення терміну до особистості і настрою? Ми побачимо те ж саме в домашніх умовах, на роботі, на різних заходах, в компанії друзів і з незнайомцями? Якщо ми побачимо щасливих людей десь, ми не отримуємо трохи щасливих? І якщо це все серйозне, ми серйозно, не ми? Чи не вірно на інші події та ситуації?
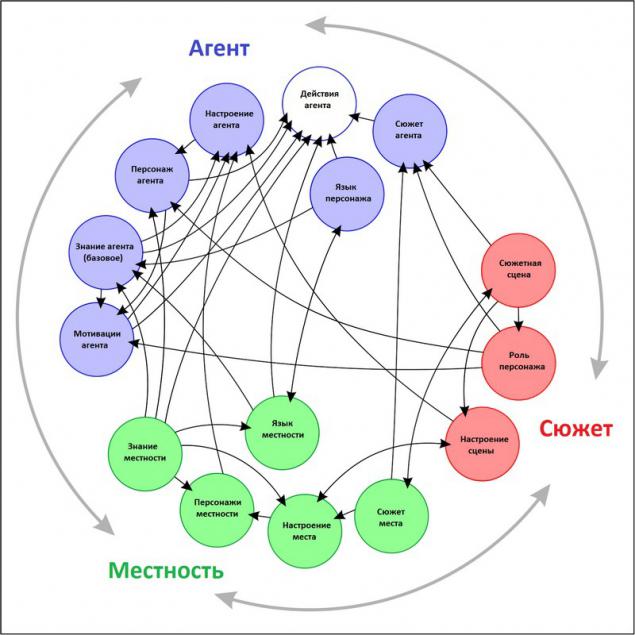
Поточна модель
Після подальшого вивчення багатьох питань і аспектів, без ускладнення коду, але тільки краще вивчити те, що штучний інтелект створюється з вишуканим підходом, зберігаючи всі базові системи, які не впливають, ми нарешті прийшли до висновку:
Будь-яке, що відбувається, коли-небудь може статися знову. Але все, що буває двічі, обов'язково з'явиться третій раз. Схеми завжди можуть бути розширені для створення нових завдань.
Ось чому наша система виглядає зараз, і це те, що ми будемо будувати нашу гру жахів, яка я говорив про початок цієї статті. Ця гра не означає обмеження цієї системи, оскільки система є досить універсальною для її подальшого розвитку. Іншим є те, що перед тим, як ми повинні навчитися досягати більш просунутих завдань з оптимальною працею і часом.
Про цей проект розповість я. Я не можу зробити це, тому що я не маю достатньо інформації.
Найцікавіше, ми завжди сказали в кінці: як тільки наша гра вийшла, ми, швидше за все, випустить свою безкоштовну модель на магазині Asset Unity, а також розкриваємо свої схеми, щоб люди могли зробити її для інших систем. Ми також будемо записувати все, що ми дізнаємося про умови використання системи, обов'язково запишіть поради та рекомендації для роботи з ним, перевірте те, що працює і що не робить, і додайте цікаві варіанти, які можна зробити за допомогою цієї системи.
Ми також хочемо, щоб грати в ігри за допомогою цієї системи. Ми хочемо відеоігри, щоб взяти свій курс, і в кінцевому рахунку вони прийдуть до того, що ігри повинні бути. Ми хочемо, щоб прискорити еволюцію мистецьких форм і вірити AI буде наступним пунктом повороту в цьому плані.
Дякую за читання! Підписуйтесь на наш блог і ми чекаємо на вас на сайті Віруси!
Джерело: habrahabr.ru/company/ilkfinkom/blog/256237/
9462791
Думаючи про те, як це зробити, я зрозумів, що для створення штучного інтелекту підійде вишуканий підхід. Про це
Деякі теорії про знання говорять, що ми не бачимо реальності, як це таке. Замість ми бачимо віртуалізовану копію. Дійсність створюється і обробляється нашим мозку. Ми бачимо той самий суд у знаменитому Плато «Міф печери».
На перший погляд, це, здається, збігається з тим, як ми підходимо до реалізації AI: ми програмуємо агентів для отримання та обробки інформації про світ, щоб потім приймати рішення на основі даних. Таким чином, ми переводимо наше бачення світу на штучний інтелект – охочі агенти, щоб діяти як вони будуть в реальному мозку людини. Такий підхід не зовсім неспроможний.
Проте в рію відеоігри є одна деталь: є еквівалент «реального світу» вже віртуальний, тобто це чиста інформація. Чому переоцінювати її в мозок агентів, а потім змусити мозок обробляти цю інформацію? Чому ми намагаємося перенести світ на мозок агента, коли ми можемо зробити навпаки: перенести мозок агента в світ? І я вирішив це зробити: світ подумати, буде розумним і зрозумілим. Мир, не агенти.
Ми приймаємо рішення, щоб піти в цьому напрямку, оскільки цей підхід був краще підходить для нашої мети побудови AI для хорошої динаміки ігор. Уявіть наступну послідовність гри:
У деяких будівлях. Як ви запускаєте передпокій, ви помітите відкриті двері, що ведеться в спальню. Ви запустіть в там і заблокуйте двері. Стеблони починають перерватися в замок, і ви усвідомите, що незабаром вони вводять в цю кімнату. Шукаєте, ви бачите закрите вікно, ліжко і шафа. Ви відкриєте вікно і приховуєте під ліжком. Відкривається двері, одна з гонщиків надходить в приміщення, йде до відкритого вікна і виходить. Він потім подрібнює до своїх акомпалісів, які ви побігли, стрибає з вікна і зникне в темний. Цього разу ви зуміли втекти.
Це те, що можна зробити з простим кодом, використовуючи базовий евристичний підхід «переклад мозку в світ». Код простий як Pacman-код. Особливість полягає в тому, що агент (сталькер) не має уявлення про те, що йде за закритими дверима, він не знає, що вікно є, що це означає, де він веде, або чи це ведеться в будь-якій точці світу. Агент не помітить всіх цих речей і ідей. Все, що він слідує знакам і інструкціям.
Уявіть наступні події:
Ви сидите на комп'ютері, створюючи гру, і раптом ви знаходитесь на кухні перед відкритим холодильником. Ви шукаєте щось або зайти на комп’ютер з чашкою кави, навіть якщо ви не відчували себе, як кава для пиття.
Як це сталося? Чи знаєте ви, що це? Чому б ви робили це?
Так в цьому випадку: «розумний» не є агентом, але вікно, а мозок належить не до агента, а до світу. Вікно розповідає агента, що робити, де шукати, куди піти, що розповісти інші агенти і як показати «хі» рішення гравця. Коли агент ходить в кімнату, то розповідають йому, що робити. Постільна кімната, в якій гравець приховується, запрошує на нього подивитися. У шафі також можна знайти всередині. Недавній відкритий вікно говорить його, щоб піти поза. Після отримання цих пропозицій агент робить розумне рішення на основі пріоритету цих завдань.
Взаємодія з вікном, гравець збільшує своє значення, в зв'язку з чим підвищується пріоритет цього завдання, а агент обирає його, а не інші варіанти - це регулюється за сценаріями вікна. Але, наприклад, якщо гравець ховався в шафі і сиділи там спокійно, то пріоритет завдання «блок в шафу» автоматично знижується, а отже, агент обирає варіант «погляд під ліжком», а гравець знову матиме можливість втекти. Все залежить від вибору дизайнера ігор: він вирішує, як кожен елемент повинен працювати.

Однак не всі завдання надходять з зовнішніх джерел. Внутрішні або прикріплені елементи до агента також можуть надати завдання. Наприклад, якщо агент має аптечку і травмується, то аптечка (який йому) замовляє агента його використання. Значення цього завдання буде безпосередньо пропорційно вираженості травми. У той же час система травми агента (внутрішня) замовляє його від того, що викликає травму агента. Скоріш за все, в цій ситуації агент, заснований на значенні кожного завдання, зникне і знайдеться безпечне місце, загоює рану і або продовжує боротьбу або відступати. Це нескладно реалізувати: потрібно лише надати першу допомогу набору знань, які в поточній ситуації без лікування, не можна приймати дії, що припинення лікування призведе до вразливості агента. Таким чином, наведено пріоритети завдань.
Це дуже основа вишуканого підходу, і я дійсно люблю його. Ми змогли зробити повноцінну систему присутності, ми зробили її надійним, складним, але в той же час дуже простими в плані коду. Крім того, ця система досить універсальна, що дозволяє легко змінювати, змінювати і додавати завдання. Наприклад, ми можемо створити нове джерело завдань у вигляді автомобіля, блокування або сходів без зміни програми агента. Або ми можемо змінити або покращувати системи, які контролюють лише конкретне завдання або частину середовища мозку, не впливаючи на інші елементи. Уміння налаштувати поведінку, здається, дуже цікавим для створення хорошої гри – особливо для гри жахів, адже гравець іноді потрапляє до жертви дій навколишнього середовища.
Тоді я хотів додати системи розпізнавання тексту, щоб побачити, як він може використовуватися в вишуканому підході. Текстова інструкція, як «введення блакитного кульки в зеленій коробці», надана відповідним непрогравачним символам, буде ідентифікована зеленою коробкою і блакитним кулькою, відповідно, і вони будуть інструктувати агента, щоб підібрати м'яч, з'ясувати де його. Це дає враження, що агент розуміє, що він говорить його, щоб зробити.
До тих пір все виглядало дуже красиво. Після закінчення початкового етапу створення ігор я знайшов, що ці завдання повинні бути реалізовані в коді. Ми в фазі виконання. На даний момент система виглядає так:
 р.
р.Поведінка - взаємодія агента з навколишнім середовищем.
Коли я почав програмування цієї системи в Уніформа Концепції, кожен день я повинен присвятити деякий час основи AI. Не просто AI для відеоігри, але AI в цілому. Я просто хотів, щоб переконатися, що я не був, що мій час, винахідивши колесо я був придуманий.
Я почав вчитися деякі дуже цікаві концепції, а також старі дослідження і експерименти, деякі з яких половина століття. Серед них я можу назвати «Систему переглядів» в експерименті Хайдера і Сіммелья з анімацією (1944 р.), «Науки штучного» (1969) з анемекдотом «Анти на пляжі», а також Kuleshov Experiment (оригінальні дати з 1919 р.), що, думаю, в той час не відповідає часу. Згодом ця інформація почала захопити мене більше і повністю позбавив мене від сну.
Поки я зрозумів, що починаючи з іншого кінця, полюючись, я прийшов до цього знання. Я пішов з дещо різною перспективою: Я хотів створити розумний світ, тому що я думав, що це було дуже ефективно, тому що ми віртуалізації світу ми живемо, і агент живе в віртуальному світі. Але це просто підстава, щоб зробити щось більш потужним і серйозним. Але тоді я не бачив цих можливостей.
Всі ці дослідження погоджуються на одне: простий комбінований комплекс дає комплексний результат, який наш мозок інтерпретує як ще більш складний і розумний, ніж це дійсно.
Звичайно, наша мета на Game Design була для AI, щоб зробити агенти з'являються складними та інтелектуальними за допомогою різних хитрощів. Але що я зацікавив, що не був цей базовий підхід, але формула Проста проти комплексу, яка була повторена в кожному з цих експериментів, і це відповідало всім дослідженням, незалежно від їх специфіки.
Після того, як я помітив, що цей аспект може бути присутнім в багатьох ситуаціях, але я не знаю про це. Дуже важливо, я шукав аналогії в проміжках в нашій системі AI. І тоді я почав запитати багато питань про проблеми дизайну і намагатися відповісти на них за допомогою тієї ж системи і формули.
• Якщо завдання створюються в модульній системі і мають доступ до інформації агента для визначення інструкцій і завдань, чому не збільшити кількість такої інформації і зробити її більш детальним? Подаруйте свою особистість, фон, настрій, почуття, соціальну динаміку, а потім створити завдання для аналізу цієї інформації замість фокусування тільки на здоров'я і інвентаризації.
Поведінка для створення персонажа, який народився в джунглі і знає, де знайти воду і харчування, і персонажі з міста без таких знань можуть бути просто фонові перевірки, проведені джерелом завдань, які надсилають наступні завдання після пошуку води і їжі. Якщо характер звідти, то завдання слід надати, якщо не звідти, завдання не надається.
• Чому я можу розглянути конкретну сторону світу і не розглянути абстрактні речі, які здаються там, але ми не можемо бачити їх? Що таке драма, невідомого, комедії? Чому ми повинні створювати поведінки, які приходять з речей, а не людей та ідей? Чому не створювати завдання з групи речей, науки та сюжетної сцени?
Ми можемо зробити динамічні сюжетні сцени, щоб оживити шаблони поведінки. Сцени, які доступні для конкретних персонажів і з'являються в залежності від того, як кожен символ відповідає ролі.
Ситуації можна планувати, прив'язувати до місця або запускати в залежності від ситуації і конкретної точки розвитку ділянки. Наприклад, для створення спільної сцени фільму для зомбі, де один з персонажів був укус або поранений, а інші персонажі стверджують, що чи допомогти йому, залишити його або просто вбити його і боротися з кінцям: ситуація не залежить від того, хто був укус або поранений. Джерело завдання (повідомлення) просто оцінює, як кожен характер вписується в свою роль і пропонує їм різні завдання для кожної ролі, що призводить до розвитку ділянки природно, на основі їх рішень. В іншому випадку ми можемо мати клімакс для будь-якого з персонажів, переглядаючи з боковини, як гравець поводиться в ключові ситуації, щоб змінити ділянку трилера.
• Чому не використовувати ці динамічні сюжетні лінії і продовжити їх вплив на подальші події з можливістю значної зміни сюжету?
Якщо гравець схвалює всюди і помітить шини на машині неплеєрного персонажа, він не відображатиме стандартну сюжетну сцену «Party». Замість цього непрогравачного персонажа буде танцювати з деякими романтичними намірами (відповіді в танцювальній сцені він буде замінений на інший непрогравачний характер зі списку), а любовний трикутник змінить ситуацію між двома героями з роз’ясненням ідентичностей, що призведе до деяких інших незвичайних результатів.
Або якщо символ, який бере на себе роль лідера групи, що втратив у степу, починає втратити свої розуми або потрапляє в розпад, абстрактна ідея/соціальна динаміка Лідерства Групи бере над непрогравачним характером і несе відповідальність за їх рішення. Аналогічно, якщо група незадоволена рішеннями лідера, соціальна динаміка даної ситуації може призвести до нового динамічного сюжету, де вони вперше борються з системою, а потім порушують в два табори.
• А ось чому зупинитися? Чому не дайте сюжетні лінії визначити, які ролі гравець вибирає, а потім пошиття ситуації для кожного гравця?
У сюжеті вибирається характер ролі другого лідера (або вона відкрита для того, щоб визначити, чи підходить гравець для цієї ролі або ні), після чого інші висловлюють свою підтримку на одну сторону, а хтось висловлює намір зупинити боротьбу і об'єднатися.
• Але персонажі можуть боротися навіть під час розкопки зомбі, або під час аргументу над тим, хто є лідером, або громада може навіть прийняти рішення відмовитися від пораненого лідера. Тому не вдосконалювати систему прийняття рішень і додати багатозадачність характеру?

Агенти мають «психо-ресурси», які дозволяють їм вибрати декілька завдань одночасно (і допитати ті рішення на основі групування задач, а не просто виконувати завдання одним шляхом): обмеження концентрацій, руки, ноги, рот, очі ...
Якщо поведінка завжди є взаємодією агента і навколишнього середовища, чому не поширюється значення терміну до особистості і настрою? Ми побачимо те ж саме в домашніх умовах, на роботі, на різних заходах, в компанії друзів і з незнайомцями? Якщо ми побачимо щасливих людей десь, ми не отримуємо трохи щасливих? І якщо це все серйозне, ми серйозно, не ми? Чи не вірно на інші події та ситуації?
Поточна модель
Після подальшого вивчення багатьох питань і аспектів, без ускладнення коду, але тільки краще вивчити те, що штучний інтелект створюється з вишуканим підходом, зберігаючи всі базові системи, які не впливають, ми нарешті прийшли до висновку:

Будь-яке, що відбувається, коли-небудь може статися знову. Але все, що буває двічі, обов'язково з'явиться третій раз. Схеми завжди можуть бути розширені для створення нових завдань.
Ось чому наша система виглядає зараз, і це те, що ми будемо будувати нашу гру жахів, яка я говорив про початок цієї статті. Ця гра не означає обмеження цієї системи, оскільки система є досить універсальною для її подальшого розвитку. Іншим є те, що перед тим, як ми повинні навчитися досягати більш просунутих завдань з оптимальною працею і часом.
Про цей проект розповість я. Я не можу зробити це, тому що я не маю достатньо інформації.
Найцікавіше, ми завжди сказали в кінці: як тільки наша гра вийшла, ми, швидше за все, випустить свою безкоштовну модель на магазині Asset Unity, а також розкриваємо свої схеми, щоб люди могли зробити її для інших систем. Ми також будемо записувати все, що ми дізнаємося про умови використання системи, обов'язково запишіть поради та рекомендації для роботи з ним, перевірте те, що працює і що не робить, і додайте цікаві варіанти, які можна зробити за допомогою цієї системи.
Ми також хочемо, щоб грати в ігри за допомогою цієї системи. Ми хочемо відеоігри, щоб взяти свій курс, і в кінцевому рахунку вони прийдуть до того, що ігри повинні бути. Ми хочемо, щоб прискорити еволюцію мистецьких форм і вірити AI буде наступним пунктом повороту в цьому плані.
Дякую за читання! Підписуйтесь на наш блог і ми чекаємо на вас на сайті Віруси!
Джерело: habrahabr.ru/company/ilkfinkom/blog/256237/