2229
Розумні зупинки.
Сьогодні ми маємо незвичайну причину, щоб поділитися нашим досвідом з громадою. Не секрет, що більшість проектів і продуктів, які ми створюємо життя в світі «віртуальний» і ми не завжди бачимо, щоб закінчити, як все, що ми працюємо в реальному житті.
Проект, який ми хочемо поговорити про отримав ім’я коду та трохи смішний титул «Smart Stops».

Таким чином, що точка – у місті «N» є міський транспорт, на якому встановлюються системи відстеження на основі датчиків ГЛОНАС, дані про рух, що попливають до центральної диспетчерської служби у вигляді постійного потоку повідомлень з цих датчиків. Хочу розмістити рідку кришталеву панель на зупинці, яка покаже, і які транспортні засоби, що збираються по маршрутах.
Ідея звучить просто і все там для його реалізації – розклад маршруту, самі маршрути, датчики та інформація з них, координати зупинок, транспортні засоби, які пішли на рейсі. Все про те, щоб зробити все разом і зробити його роботою.
Це те, що ми хочемо розповісти про сьогодні, як з протоколу зв'язку з датчиками ми допустили збірку заліза для смарт-запуску і показали робочий прототип на виставці TECHNOPROM 2014.
Почнемо з базовою архітектурою системи, а потім перейдемо деталі.
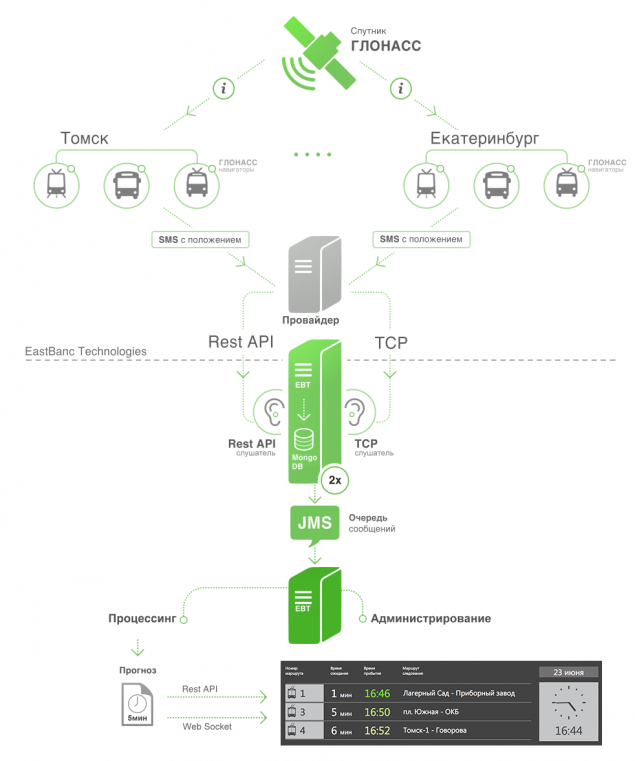
На даний момент немає єдиної системи або стандарту для забезпечення оперативних даних. Різні міста мають різні провайдери, які використовують різні способи розподілу даних та різних форматів та контенту. На даний момент ми зіткнулися з двома: передача даних над TCP та REST API на стороні провайдера.
Приклад пакету, який ми отримуємо через TCP
Проект, який ми хочемо поговорити про отримав ім’я коду та трохи смішний титул «Smart Stops».

Таким чином, що точка – у місті «N» є міський транспорт, на якому встановлюються системи відстеження на основі датчиків ГЛОНАС, дані про рух, що попливають до центральної диспетчерської служби у вигляді постійного потоку повідомлень з цих датчиків. Хочу розмістити рідку кришталеву панель на зупинці, яка покаже, і які транспортні засоби, що збираються по маршрутах.
Ідея звучить просто і все там для його реалізації – розклад маршруту, самі маршрути, датчики та інформація з них, координати зупинок, транспортні засоби, які пішли на рейсі. Все про те, щоб зробити все разом і зробити його роботою.
Це те, що ми хочемо розповісти про сьогодні, як з протоколу зв'язку з датчиками ми допустили збірку заліза для смарт-запуску і показали робочий прототип на виставці TECHNOPROM 2014.
Почнемо з базовою архітектурою системи, а потім перейдемо деталі.

На даний момент немає єдиної системи або стандарту для забезпечення оперативних даних. Різні міста мають різні провайдери, які використовують різні способи розподілу даних та різних форматів та контенту. На даний момент ми зіткнулися з двома: передача даних над TCP та REST API на стороні провайдера.
Приклад пакету, який ми отримуємо через TCP
#D#00287;190614;034452;5628.0000;N;8457.8226;E;0;272;123;12;gosnum:3:379,num:3:3 руль Приклад пакету з API REST{"online": [{"deviceHash" : 0558132541, "ім'я" : "автобус X564BE96", "timestamp" : 1384710565, "широтість" : 50.65, "довга" : 60.56, "швидкість" : 43.5, "курс" : 120.1, "sats" : 8, "роботий" : "021-автобус" }
Формат та зміст пакета:
Ідентифікатор пристрою. Назва або ідентифікатор транспортного засобу є числом транспортного засобу і типом транспортного засобу. Час захоплення даних. Широта і довгота. Швидкість. Курс. Кількість супутників. Виявлення маршруту, на якому переміщається транспортний засіб. Всі дані використовуються в алгоритмі прогнозування.
Розглянемо обидва варіанти отримання даних.
Функції та обов’язки Списокника:
Отримання сировини від постачальника. Обробка даних у форматі, що відповідає системі. Від лінії або від JSON до POJO. Відправлення отриманого POJO з даними до JMS на задану тему. толерантність до в’їзду. Щоб визначити проблеми з отриманням даних від провайдера або фізичної доступності Список, списокець повинен надсилати пакети до СМС. Заощаджуйте POJO після зарахування в окрему базу даних. Триває сирі дані на тиждень. Даний механізм призначений для накопичення мінімальної статистики алгоритму. Під час життя системи слід було відрефінувати і відхилити алгоритм, і для того, щоб мати можливість перевірити зміни алгоритму, ми зберігаємо дані. І ми знаємо, як грати їх, щоб накопичувати статистику і оцінити роботу алгоритму після змін.
У разі TCP ми вказуємо хост і порт, і постачальник даних направляє пакети до цього хосту. Далі ми отримуємо список каналів TCP.
Ми використовували Netty як основу для TCP. Дуже простий у використанні і стабільний в експлуатації. У випадку API REST ми використовували клієнт Jsoup, який обпилює апі таймером.
Самий список є додатком консолі з можливістю вказати хост, порт і налаштування для JMS і бази даних.
Процес Список:
Отримання даних за фактом у випадку ТCP або таймером у випадку API REST. Аналізуйте лінію або JSON і створюйте об'єкт навігаційного пакету. Навігація Пакет до JMS. Зберегти навігацію Пакет до бази даних. Надсилання пінг-пакету на об'єкт JMS (PingPackage). 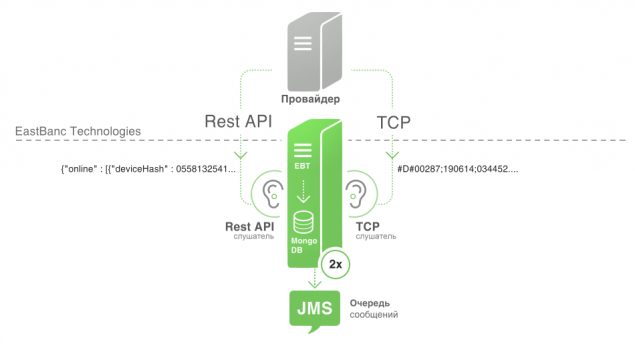 Р
Р
В результаті кожні 30 секунд ми заповнюємо нашу базу даних з інформацією про реальні рухи транспортних засобів.
Що потрібно розібратися?
1,1 км Маршрутні маршрути.
2,2 км Стоп координати.
Ми взяли дані маршрутів і зупинок з ГІС-систем, обробляємо їх таким чином, щоб отримати відрізані маршрути.
Ну, тепер ми знаємо, хто йде, тому час, щоб почати прогнозування. Але перед тим нехай дивиться на номери.
Щоб отримати кращий сенс, як це все працює, давайте показати цифри:
 Р
Р60 навігаційних пакетів З 8 маршрутів тролейбуса на хвилину. 10мс. Займає прогноз на одну зупинку. 600 мс. Займає одну навігацію в середньому. 500 сегментів в середньому за один маршрут. 5 до 20 транспортних засобів в середньому за маршрутом Томськ. 168 зупинки в Томськ для 8 маршрутів 159 годин для двох осіб Ось як довго і скільки людей ми реалізували весь алгоритм.
І звичайно, швидкість роботи залежить від апаратного забезпечення - всі вищені дані видаляються з тестової віртуальної машини.
Далі потрібно вибрати алгоритм, реалізувати його і показати результати.
Як обраний алгоритм. Як і будь-який інший час, ми не перейменуємо колесо, ми намагаємося розібратися, що з алгоритмів, які ми маємо найкращі для нас. Багато робіт проводили неросійські та російські вчені. Насправді, існує безліч підходів до прогнозування, а всі алгоритми модифікації двох або трьох основних.
Першим кроком було вибрати декілька алгоритмів, які здавалося «прості». По суті, кожен з основних алгоритмів має однакову складність у розумінні та реалізації. У всіх випадках, які можуть бути розглянуті і можуть бути використані.
Наш стартовий пункт був науково-дослідним папером Ran Hee Jeong [1]. Ми надаємо повний перелік літератури та творів у нижній частині статті.
Отже, перший крок, який ми взяли на себе кілька статей та наукових праць по алгоритмах в рамках команди. На дошці звернулися всі підводні камені і намагалися вгадати, як деталі не описані в статтях будуть працювати. Я, не дуже знайти. У нашому випадку обрані алгоритми розглядали прогноз, але не розглядали шляхи збору статистики проходу маршрутів, на основі яких необхідно будувати прогноз.
Другий крок – це майстер-клас, де ми спробували розповісти і пояснити алгоритм наших колег. У цьому заході взяли участь сім людей. В кінці, після відповіді на всі питання, ми зрозуміли, що ми можемо реалізувати алгоритм у скінченному режимі.
Все про технології. Аналіз, поділ на завдання, оцінку та план роботи. По дорозі, після такої попередньої роботи, ми змогли зробити хорошу оцінку, і більш важливо, ми потрапили в неї.
При виборі алгоритму ми спробували знайти баланс між складністю реалізації та результатами алгоритмів. В результаті алгоритм, що базується на історичних даних, трохи втрачається до алгоритму, на основі нейромережі при прогнозній точності, але простіше реалізувати. У нас була потреба в досягненні прогнозу з помилкою 30 - 60 секунд, що цілком прийнятно для звичайних пасажирів.
Невелике відхилення від технічної частини проекту в напрямку проведення таких проектів.
Серед умов на старті ми мали одне дуже важливе обмеження, ми повинні отримати робочий прототип до певного числа. Асоціюється з експозицією TECHNOPROM 2014. А коли ми пишемо план роботи, нам довелося поставити весь алгоритм і додаток клієнта в першу частину проекту. Без системи управління та інших необхідних речей.
Ми можемо самі зателефонувати одержувачу і узгодити зручний час. А в нашому випадку ми повинні витрачати більшу частину часу, що реалізує алгоритм і працює його.
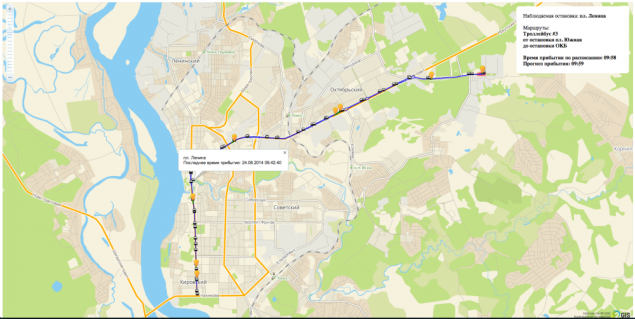
В результаті ми вирішили зробити тестовий стенд на одному маршруті і одну зупинку.
Тестовий стенд html + js + webSocket.
У процесі розробки ми спочатку мали карту і маршрут на ньому. Після цього з'явилися транспортні засоби (ТС) і оновлення їх положення. Далі положення транспортного засобу на маршруті є відрізком і відсотком проходження. Потім визначає час прибуття при зупинці. Тоді сам прогноз і останній крок у розвитку алгоритму був графіком, на якому було показано помилки прогнозування.
Цей підхід дозволив клієнту «живо» спостерігати процес нашої роботи. Все було дуже прозорим.
Детальніше про технічну частину обробки та роботу алгоритму.
Спочатку дизайн повинен мати окремий сервер для кожного міста.
Процес і функція сервера обробки:

Отримання даних з JMS. Визначення положення транспортного засобу на маршруті та стану транспортного засобу на основі навігаційної інформації. Розрахунок статистики проходження сегментів. Прогноз прибуття стартував для підключених зупинок за таймером. РЕСТ API. WebSocket API. Spring-JMS використовується для роботи з JMS.
WebSocket - Весна-Веб-камера
Для REST API - Spring-WEB
Визначення положення транспортного засобу на маршруті.
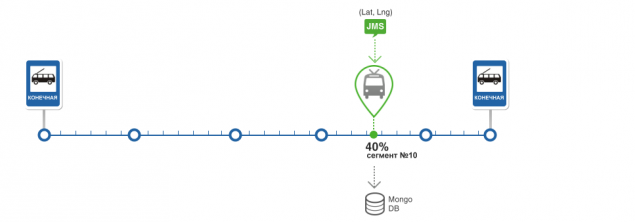
Збір статистики проходження сегментів ТС.
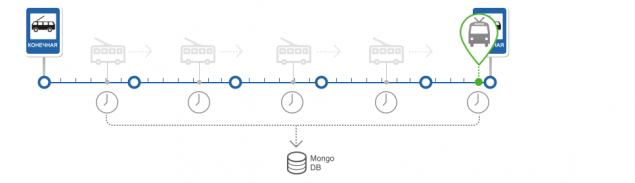
Вирокувати прибуття в зупинку.
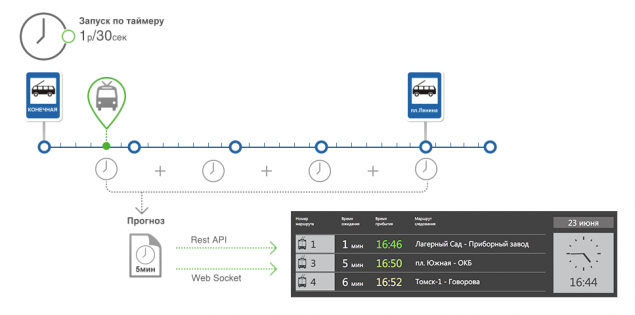
Робота алгоритму можна розділити на наступні частини:



Визначення положення транспортного засобу на маршруті та визначення стану транспортного засобу Розрахунок статистики проходження сегментів маршруту та розрахунку фактичного часу проходження сегментів маршруту Визначення заїзду при зупинці та розрахунку прогнозної помилки Прогнозування
Визначення положення транспортного засобу на маршруті та визначення стану транспортного засобу при отриманні навігаційної інформації алгоритм пошуку положення транспортного засобу на маршруті. Позиція транспортного засобу складається з сегмента маршруту і відсотка його проходження і зберігається в базі даних разом з транспортним засобом.
Алгоритм працює наступним чином:
Отримати дані маршруту та транспортного засобу від DB. Якщо транспортний засіб не існує, створіть його. Пошук сегментів маршруту на даній відстані від поточного положення транспортного засобу. Пошук здійснюється оператором MongoDB Для кожного сегмента розраховується кут між вектором руху автомобіля і вектором руху сегмента. Якщо різниця між цими кутами мінімальна і якщо вона не перевищує певну помилку, то система вважає, що знайдений потрібний сегмент. Для знайденого сегмента розраховується відсоток проходу. Для цього проводиться проекція позиції транспортного засобу на сегменті і процент від початку сегмента до проекції. Після визначення сегмента, на якому знаходиться транспортний засіб, ми визначаємо стан ts. Тільки чотири штати Початковий, кінець, прогноз, Невідомий. Початкові та кінцеві сегменти відповідають першому сегменту маршруту та останнього. Прогноз - означає, що положення транспортного засобу визначається. Не відомо, якщо не знайдено сегмента. Всі держави використовуються при прогнозуванні та статистичному розрахунку.
Розрахунок статистики проходження сегментів маршруту та розрахунку фактичного часу проходження сегментів маршруту Основою алгоритму є статистика.
Маршрут розділений на сегменти і в процесі роботи система накопичує статистику часу проходження для кожного сегмента. Кожен сегмент має 90 статистичних значень.
Розбиття:
Зима, літо, позасезоння Днів і вихідних Час від 6:00 до 21:00
Система є самодостатньою і як прогрес роботи, статистичне зростання і точність прогнозу зростає.
Завдання накопичувальної статистики – отримати час проходження відрізку маршруту. Цей час додається до відповідного статистичного інтервалу для ваги. Нормативно пропорційна кількості вимірювань. Це, з одного боку, дозволить мінімізувати тимчасові відхилення в проходженні сегментів, з іншого боку, враховувати зміни дорожньої ситуації в довгостроковій перспективі.
Поточний час проходу сегмента є останнім вимірюванням часу проходу сегмента сьогодні. З приходом нового дня дані нагородження.
Колекція статистики є частиною, яка погано описана в документах, і це частина, яку ми зробили на нашому розсуд.
Наше завдання – отримати час проходження транспортного засобу в сегменті. Під час кожного положення транспортного засобу на маршруті та часу отримання даних про позицію транспортного засобу зберігаються.
Маршрут проходить в цілому, а саме — на одному з кінцевих сегментів маршруту. Коли ми записуємо цей факт, ми починаємо процес обчислення часу проходження сегментів по маршруту.
Враховуючи наявні сегменти та частоту збору даних, ми визначимо чотири ситуації:
Ситуація 1.

Ситуація 2.
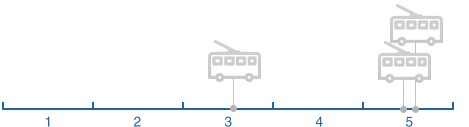
Ситуація 3.
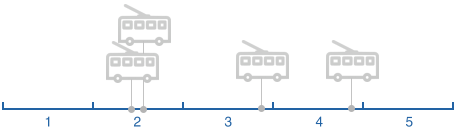
Ситуація 4.
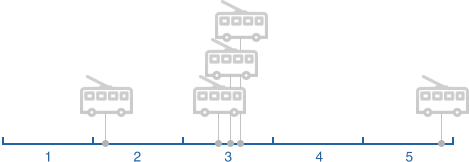
З декількох точок розташування транспортного засобу і часу кожного пункту ми можемо розрахувати, як довго він взяв сегмент для завершення або частини його. Залежно від ситуації ми ігноруємо деякі точки положення транспортного засобу, наприклад, якщо є кілька від одного сегмента.
Після визначення поточного положення транспортного засобу на маршруті прораховується наступна зупинка транспортного засобу і факт прибуття при зупинці.
Реалізовано два варіанти алгоритму прибуття.
Перший варіант в гайка – транспортний засіб прибув на зупинці, якщо він на сегменті відразу перед зупинкою або відразу після. І цей варіант не працює = Справа в тому, що різні зупинки мають різне призначення сегментів в довжину, і якщо сегмент занадто короткий, то навігаційні дані просто не потрапили в них.
Другий варіант в гайка – транспортний засіб прибув на зупинці, якщо він знаходиться на певній відстані від неї. З MongoDB і гео індексами ми не мали труднощів писати правильні запити. Розмір полігону, в якому здійснюється пошук на основі частоти отримання навігаційних даних, тобто ми обрали розмір полігону, щоб мінімізувати його розмір і при цьому збільшити ймовірність того, що транспортний засіб буде в ньому.
В обох випадках ми розглянемо тільки транспортні засоби, які знаходяться на маршруті, для яких визначається сегмент.
Прибуття транспортного засобу на зупинці відображається на блоці.
Визначивши, що автомобіль прибув на зупинці, ми розраховуємо відхилення прогнозу з реального часу за допомогою індикатора MAPE. Про це читайте тут.
І прийшов день, коли ми зробили всі частини, крім останнього. Власне, що робить прогноз.
Резюме алгоритму




На в'їзді ми маємо маршрут, що складається з сегментів. Для кожного сегмента ми знаємо час статистичного транзиту і останній фактичний час транзиту. Статистика вибирається виходячи з часу доби, дня тижня і часу року. Останній поточний час кожного сегмента використовується для мінімізації помилки статистики. Так, у нас є набір сегментів з транзитним часом, ми маємо зупинку на маршруті і набір транспортних засобів на маршруті.
Першим кроком є визначення найближчого транспортного засобу на шляху до зупинки, для якого ми побудуємо прогноз.
Для цього ми вибираємо ТС з бази даних, які слідують зупинці, за яким ми робимо прогноз. При цьому ми враховуємо стан транспортного засобу, визначеного раніше.
Кожен автомобіль має позицію на маршруті, а саме відрізок маршруту, на якому він знаходиться.
Кожен сегмент має серійний номер під час руху транспортного засобу на маршруті. Виберіть з переліку транспортних засобів, який має номер постійного сегмента, він буде близьким до зупинки.
Другий крок – отримати набір сегментів між транспортним засобом і зупинкою. Як ми вже знаємо, транспортний засіб знаходиться на сегменті, і кожна зупинка «значки», яка прилягає до нього сегменти. Так ми маємо два сегменти і вибираємо список між ними.
Третій крок зараховує час.
Summarize статичного та фактичного часу проходження сегментів між транспортним засобом та Зупинкою. Більша вага статистичного часу і навпаки, для сегментів близько до зупинки, більша вага фактичного часу проходження сегмента.
Сума часу - прогноз, коли автомобіль прийде до зупинки.
В результаті ми взяли алгоритм на основі історичних і реальних даних світу [2] і змінили його трохи в процесі підвищення точності прогнозу, а ось:
3250Р. 3700Р.
Тепер у нас є власний маленький контрольний номер! З голими жінками і будівництвом =.
Ми запрошуємо систему як великий і комплексний рішення для мережевих зупинок в різних містах. Така система не може працювати без управління та контролю.
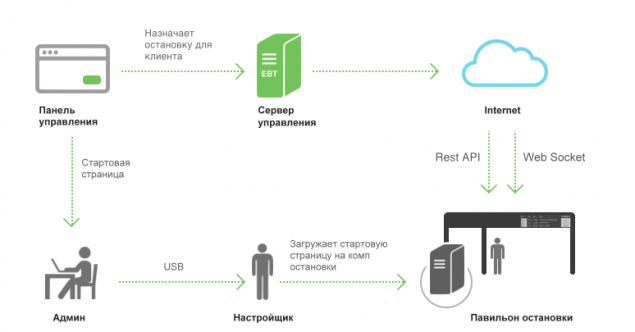
Вся система може бути розбита на наступні компоненти:

Панель управління. Почати сторінку. Клієнт. Більше про кожну частину і їх взаємодію.
Панель управління - це веб-додаток для створення, управління та моніторингу клієнтської мережі. Другу частину проекту було розробити цей Додаток.
Ми розробили велику кількість веб-додатків, використовуючи AngularJS і Bootstrap, і цей час наш вибір впав на цих рамках. Ми не мали високих вимог до дизайну і ми використовували стандартні стилі.
В основному, все, що вам потрібно, це управління і алгоритм моніторингу. Обидві частини системи живі і змінюють час.
Адміністратор може створити і завантажити сторінку запуску клієнта, переглянути статус клієнтів і час останнього оновлення інформації про клієнта. Вимкніть, або відреагуйте клієнта на іншу зупинку та ряд інших функцій сервісу.
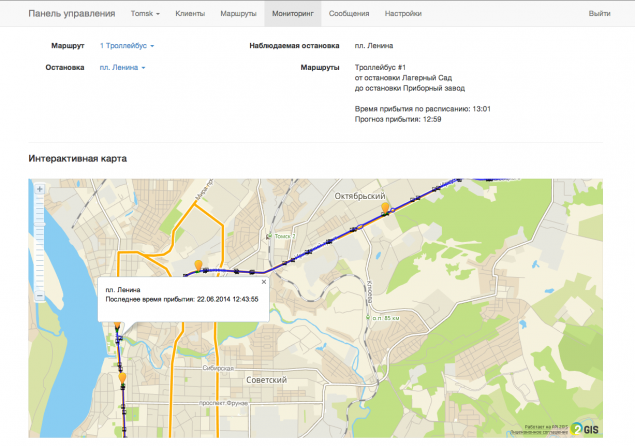
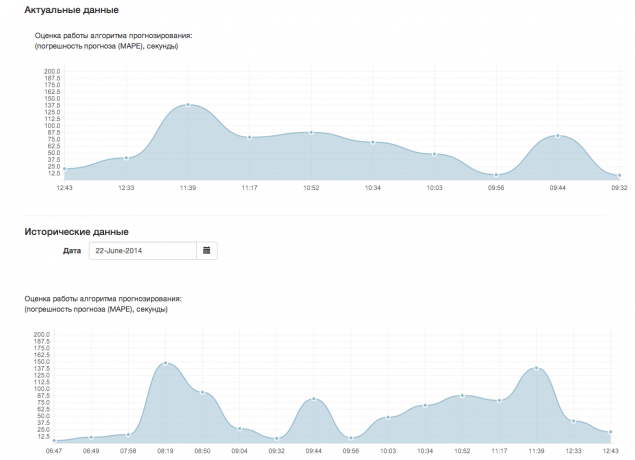
Щоб відстежувати операцію алгоритму, ми розробили розділ моніторингу, де адміністратор може відстежувати рух транспортних засобів на карті в режимі реального часу і може оцінити роботу алгоритму на основі індикатора MAPE, що відображається на діаграмі.
Невелика статична програма html+js, яка спілкується з сервером через WebSocket і реагує на дії адміністратора, при цьому відновлюючи підключення в разі скелі.
Це дуже початок нашої команди. Ця сторінка працює без інтернету, і якщо система підключена до Інтернету, сторінка намагається дізнатися з сервера, що вона повинна відображатися. В цілому сервер надсилає переадресацію на даний клієнт.
Початкова сторінка завантажується при установці або приготуванні обладнання з USB-медіа.
Замовник Наш чарівний щит =). Ми намагалися зберегти дуже простий і зрозумілий дизайн.
Як і всі веб-зали, це Angular JS + Bootstrap + WebSocket додаток завантажується з сервера на відміну від сторінки запуску.
У розвитку було приділити велику увагу розгляду надзвичайних ситуацій. Втрата з'єднання, закриття маршрутів через деякі події (травень 9 – парад). Ми спробували зробити букмекер самостійною та інтелектуальною. Ми думаємо, що це робили.
Давайте пояснимо трохи. Ми спробували впровадити і дайвінг в процес створення і монтажу зупинних павільйонів. Розроблено систему управління. Все відчувається як невеликий квест.
Дізнайтеся, як розробляти та будувати павільйони. З`ясуйте, яким силам, в якому порядку і за який час монтується павільйон.
Хочу сказати, що зупинка, яка була представлена на виставці, була встановлена в 5 годин, і фактично знаючи начинку і кількість деталей дивовижна швидкість !!! = Хлопці професіонали!
Вибрано спеціалізоване промислове обладнання, яке здатне витримати агресивні умови праці. Це стосується відображення та комп'ютера. Це обладнання набагато дорожче і не продається, тому говорити, під рукою. Отже, для виставки, що сталося, ми обрали більш бюджетний варіант.
Основою було взято найбільш поширену систему і 4 ультраширокий монітор LG, який буде працювати в парах.


Живлення 450W ATX v.2.2 INWIN (RB-S450T7) Asus GF-GT610, 1Gb DDR3, 64bit, PCI-E, DVI, HDMI, LP, роздрібна торгівля (GT610-SL-1GD3-L) Toshiba 1Tb DT01ACA100 3.5" 7200rpm 32Mb SATA3
Наші партнери були відповідальні за збір і придбання заліза. І тепер прийшов довгоочікуваний момент, коли ми отримали дзвінок і запрошували, щоб забрати залізо. Не часто в роботі програматора ви повинні зробити щось, що ви можете «прибрати» і це класно, що у нас є такий проект!!!
Ми поїхали, привеземо, розпакували і встановили. Здавалося б, «Хуррах!», але це тільки початок. Вона звучить досить просто, але шукаючи на малюнку з чотирма моніторами досвідчена Лінускойд зрозуміти, скільки квацій було зроблено для того, щоб запустити все.
Так що ми вийшли з неї?
Створено зображення операційної системи на базі ОС Ubunta, а також розроблено сценарії для запуску в експлуатацію. Процес дуже простий - перед установкою на комп'ютері, щоб зупинитися, встановлюється зображення операційної системи і заповнюється стартовою сторінкою, в якій зшивається унікальний ідентифікатор комп'ютера. Все налаштовано таким чином, що при завантаженні системи, заголовок буде автоматично відкриватися і працювати автоматично.
Програма XRANDR використовується для регулювання розташування та роздільної здатності дисплея. ХРОМІУМ використовується як браузер. Також не без користувацького віконного менеджера, щоб зробити роботу браузера в повноекранному режимі на двох моніторах.
На час нашого успіху ми відчували місцеве щастя. А весь офіс на кілька днів прийшов до «відки» тролейбусу на власній зупинці «пл». Ленін, місто Томськ.
Перша частина проекту готова, готова та заголовок та програмного забезпечення та праска. Всі готові до виставки TECHNOPROM 2014.
4 липня, зателефонуйте партнерам, які ми залишимо на кріпленні зупинки. До речі, виставковий центр, де відбулася виставка, розташована на протилежному кінці міста і шлях до того, щоб на ньому було майже два години на алкогольні джеми =.

Прибуття з обладнанням в виставкових павільйонах три вдень, а збірка повинна бути завершена восьмий вечір. За ці години у виставковому залі виросла гарна зупинка. Багато людей взяли участь у зборі і кожен зробив свою роботу практично паралельно, тому було практично можливо зустрітися з

Хоча ми є програмістами, але також озброєні викрутками і викрутками, сміливо приймали бізнес =) Підсуміть Інтернет, встановіть наш "ірон", живлення, маршрутизатор, підключення до дисплеїв ... І тут!
 , Україна
, Україна
Варто сказати, що наша експозиція була найпопулярнішою на виставці і багато, багато людей висловили надію, що такі зупинки павільйони з'являться в містах, хоча б на центральних зупинках!

Я хочу сказати, що цей проект є пригодами багато способів, і ми отримали велике задоволення від виконаної роботи.
Як ви можете бачити, ми отримали простий, але при цьому робоча система, але це буде чудово, якщо послуги з джемінгу трафіку дали інформацію у відкритому вигляді, а алгоритм можна регулювати відповідно. І в той же час – засмічений, якщо на дорозі з'явився нещасний випадок, що викликало джем, наша бейкерка покаже, що затримка невизначена.
Щоб бути абсолютно чесною і корисною нижче, ми вирішили додати список творів і літератури, які можуть бути корисніше один раз:


 , Україна
, Україна
Ran Hee Jeong. Прогнозування часу прибуття автобуса за допомогою систем автоматичного розташування транспортних засобів:, що надходить до Офісу Вищих студій Університету Техаса A&M в частковому виконанні вимог до ступеня доктора філософії: Цивільне будівництво / Ran Hee Jeong. — Beon 1-Dong, Kangbuk-Gu, Сеул, Корея, 2004. Погребний В. Ю., Федев А. С. Алгоритмізація прогнозування часу прибуття пасажирського транспорту при зупинці з використанням моделі на основі історичних та реальних даних. Журнал "Science" Випуск 6, листопад – грудень 2013 Johnson C.M. Автоматична транспортна розв'язка Успішні транспортні застосунки: Дослідження крос-Кутінгу, Е.Л. Томас, Федеральна трансмісійна адміністрація, США Департамент транспорту, 2000. Глобальна навігаційна супутникова система ГЛОНАС. Документ керування інтерфейсом: навігаційний радіосигнал в гуртах L1, L2 (ред. 5.1) [Електронний ресурс]. - Москва, 2008. Режим доступу: www.aggf.ru/gns/glon/ikd51ru.pdf, безкоштовно. (Дата звернення: 15.03.2013). Розширений громадський транспорт Системи: Стан оновлення мистецтва 2000. Публікація FTA-MA-26-7007-00-1 / R.F. Casey, L.N. Labell, L. Moniz, JW. Royal, M. Sheehan та ін. — Федеральна транспортна адміністрація, U.S. Департамент транспорту, 2000. Панамрава О.Н. Інтелектуальні транспортні системи - інструмент підвищення ефективності російської економіки в цілому, 2013. Діхуа Сонце, Вирокуючи час прибуття автобуса на базі глобальних систем позиціонування даних / Dihua Sun // Дослідницька запис: журнал Науково-дослідної ради з транспорту, No 2034, Науково-дослідна рада національних академій. — Вашингтон, Д.С., 2007. — С. 62-72. SeemaS.R. Прогнозування часу прибуття динамічних автобусів за допомогою GPS даних / S.R. Seema // 10-а Національна конференція з технологічних тенденцій (NCTT09). — 2009. — С. 193-197. Seyed Mojtaba Tafaghod Sadat Zadeh. Дослідження щодо застосування штучного інтелекту для прогнозування часу прибуття автобусів / Seyed Mojtaba Tafaghod Sadat Zadeh, Toni Anwar, Mina Basirat // Журнал теоретичних і прикладних інформаційних технологій. - 2012 - П. 516-525. Моделювання графіків відновлення процесів у транзитних операціях з прогнозування часу прибуття автобусів / Wei-Hua Lin // Кафедра систем і промислової інженерії Університет Арізона. - 2004. Ми-Хуа Лін. Експериментальне дослідження з поточного часу прибуття автобусів прогноз з даними gps / Wei-Hua Lin. — Центр досліджень транспорту та управління цивільно-екологічної інженерії 200 Паттон Хол Вірджинський політехнічний інститут та Державний університет Чорногосбург.
Джерело: habrahabr.ru/company/eastbanctech/blog/227165/