Жизнь — интересная!
Подписывайтесь на нашу группу в Telegram и Facebook, чтобы быть в сообществе единомышленников, находить вдохновение и не пропускать свежие и удивительные статьи с bashny.net.
2217
0.5
2014-06-24
Смышлёные остановки
Сегодня у нас необычный повод поделится нашим опытом с хабросообществом. Не секрет, что в большинстве случаев проекты и продукты, которые мы создаем, живут «виртуальном» мире, и мы не всегда можем проследить от самого начала и до конца как все то, что мы делаем работает в реальной жизни.
Проект, о котором мы хотим рассказать получил у нас кодовое и немного смешное название «Смышлёные Остановки».

Итак, в чем суть – в городе «Н» есть городской транспорт на котором установлены системы слежения основанные на датчиках ГЛОНАСС, данные о перемещении стекаются в центральную диспетчерскую службу в виде постоянного потока сообщений от этих самых датчиков. Хочется разместить на остановке жидкокристаллическую панель, которая покажет, когда и какие транспортные средства, идущие по маршрутам прибудут.
Идея звучит просто и для ее реализации все есть – расписание маршрутов, сами маршруты, датчики и информация от них, координаты остановок, транспортные средства, вышедшие в рейс. Дело за малым – собрать это все в одну кучу и заставить работать.
Именно об этом мы и хотим сегодня рассказать, как от протокола общения с датчиками мы дошли до сборки железа для умной остановки и показали работающий прототип на выставке ТЕХНОПРОМ 2014.
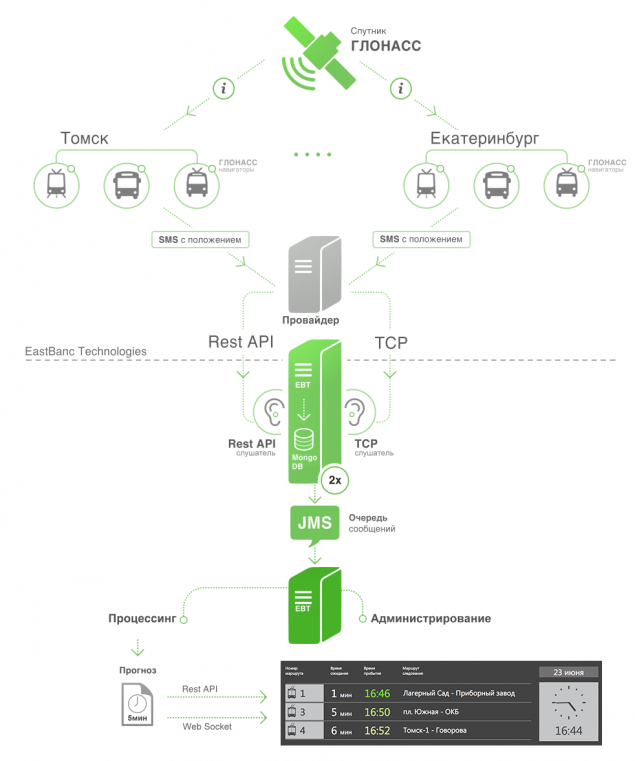
Начнем с принципиальной архитектуры системы, а потом пробежимся по деталям.
Пример пакета, который мы получаем по TCP
Пример пакета из REST API
Формат и содержание пакетов:
Рассмотрим оба варианта получения данных.
Функции и ответственность листнера:
В случае с TCP мы указываем хост и порт, и провайдер данных отсылает пакеты на этот хост. Далее в дело вступает наш листенер TCP канала.
Мы использовали в качестве основы для TCP листнера Netty. Он очень прост в использовании и стабилен в работе. В случае с REST API мы использовали клиента Jsoup, который опрашивает api по таймеру.
Сам листнер, это консольное приложение с возможностью указать хост, порт и настройки для JMS и базы данных.
Процесс работы листнера:
Как результат каждый 30 секунд мы наполняем нашу базу данных информацией о реальных перемещениях транспортных средств (далее ТС).
Что нам нужно, чтобы разобраться с тем что происходит?
1. Сегментированные Маршруты.
2. Координаты остановок.
Мы взяли данные маршрутов и остановок из ГИС систем, обработали их таким образом, чтобы получить сегментированные маршруты
Отлично, теперь мы знаем кто и где едет, а значит пора начинать строить прогноз. Но перед этим для разрядки отвлечемся на цифры.
Для того чтобы лучше почувствовать, как это все работает покажем числа:
И конечно же скорость работы очень зависит от железа — все приведенные выше данные сняты с тестовой виртуальной машины.
Идем дальше, нужно выбрать алгоритм, реализовать его и показать результаты.
Первым шагом выбрали несколько алгоритмов, которые показались нам “проще”. На самом деле любой из основных алгоритмов имеет одинаковую сложность и в понимании и в реализации. Все отличие — в частных ситуациях, которые можно рассматривать, а можно опустить.
Нашим отправным шагом была исследовательская работа Ran Hee Jeong [1]. Полный список литературы и работ мы привели внизу статьи.
Итак, первым шагом мы выбрали несколько статей и научных работ об алгоритмах внутри команды. На доске прорисовали каждый и осознали все подводные камни и постарались предположить, как будут работать части, не описанные в статьях. Да, далеко не все можно найти. В нашем случае выбранные алгоритмы рассматривали именно прогноз, но не рассматривали способы сбора статистики прохождения маршрутов, на основе которой должен строится прогноз.
Вторым шагом мы устроили мозговой штурм на котором постарались рассказать и объяснить коллегам выбранный алгоритм. Всего в этом мероприятии принимало участие семь человек. По итогу, ответив на все вопросы, мы осознали, что сможем реализовать алгоритм за конечное время.
Дальше дело техники. Анализ, разбиение на задачи, оценка и план работ. К слову сказать, после такой предварительной работы у нас получилось сделать хорошую оценку, и что еще важнее — мы в нее уложились.
Среди условий на старте мы имели одно очень важное ограничение, мы должны были получить рабочий прототип к определенному числу. Это было связанно с проведением выставки ТЕХНОПРОМ 2014. И при написании плана работ нам пришлось вынести в первую часть проекта разработку алгоритма целиком и клиентского приложения. Без системы управления и других необходимых вещей.
Хороший проект для заказчика, когда он видит прогресс работы как можно чаще. А в нашем случае у нас большая часть времени должна была уйти на реализацию алгоритма и его обкатку.
В итоге мы решили сделать тестовый стенд для одного маршрута и одной остановки.
Тестовый стенд это html + js + webSocket.
В процессе разработки у нас сначала появилась карта и маршрут на ней. Потом появились транспортные средства(ТС) и обновление их положения. Потом положение ТС на маршруте – сегмент и процент прохождения. Потом определение времени прибытия на остановку. Потом собственно прогноз и последним шагом разработки алгоритма был график на котором отображалась погрешность прогноза.
Такой подход дал возможность заказчику «в живую» наблюдать за процессом нашей работы. Все было очень прозрачно.
Далее более подробно о технической части процессинга и о работе алгоритма.
Процесс работы и функции процессингового сервера:
Для WebSocket – Spring-WebSocket
Для REST API — Spring-WEB
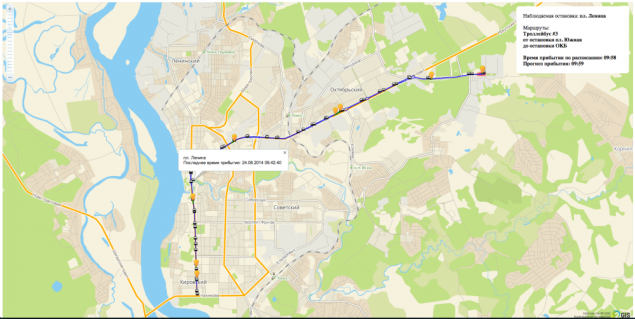
Определение положения ТС на маршруте.
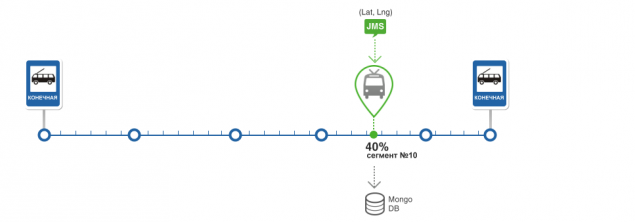
Сбор статистики прохождения ТС сегментов.
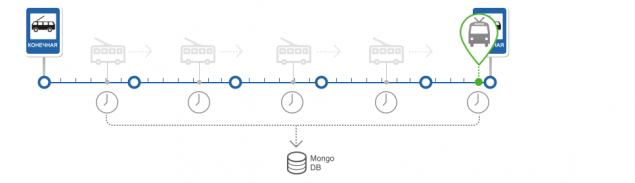
Построение прогноза прибытия на остановку.
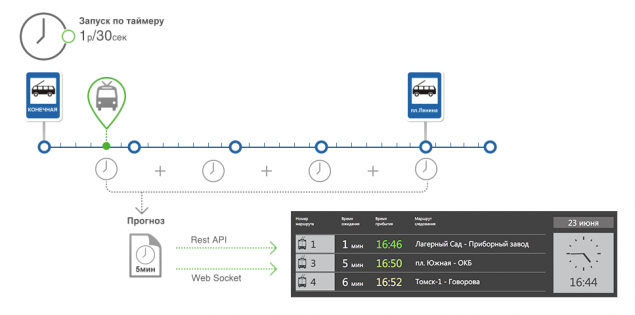
Алгоритм работает следующим образом:
Маршрут разбит на сегменты и в процессе работы система накапливает статистику времени прохождения для каждого сегмента. Каждый сегмент имеет 90 статистических значений.
Разбиение следующее:
Система самодостаточна и по мере работы статистика увеличивается и точность прогноза повышается.
Задача накопления статистики сводится к получению времени прохождения сегмента маршрута. Данное время добавляется в подходящий статистический интервал с учетом веса. Скорость изменения статистики обратна пропорциональна количеству измерений. Это с одной стороны позволит минимизировать врЕменные отклонения в прохождении сегментов, с другой учесть изменившуюся дорожную ситуацию в длительной перспективе.
Актуальное время прохождения сегмента – это последнее измерение времени прохождения сегмента на сегодня. С приходом нового дня эти данные обнуляются.
Сбор статистики — это та часть, которая слабо описана в документах, и это именно та часть, которую мы сделали на свое усмотрение.
Наша задача — получить время прохождения ТС по сегменту. В течении дня сохраняется каждое положение ТС на маршруте и время получения данных о положении ТС.
ТС проходит маршрут целиком, а именно оказывается на одном из конечных сегментов маршрута. Когда мы фиксируем этот факт, мы запускаем процесс подсчета времени прохождения сегментов по маршруту.
Рассмотрев имеющиеся сегменты и частоту получение данных мы выделили четыре ситуации:
Ситуация 1.

Ситуация 2.
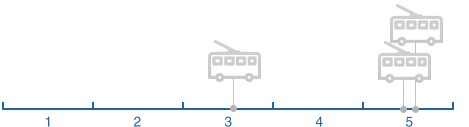
Ситуация 3.
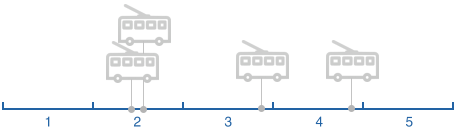
Ситуация 4.
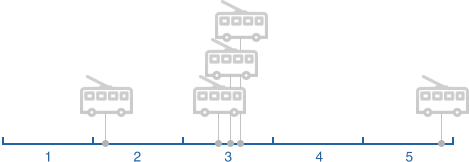
Имея несколько точек положения ТС и время каждой точки мы можем рассчитать за какое время пройден сегмент целиком или его часть. В зависимости от ситуации мы игнорируем какие-то точки положения ТС, например, если их несколько на одном сегменте.
Мы реализовали два варианта алгоритма прибытия.
Первый вариант в двух словах – ТС прибыло на остановку, если оно находится на сегменте сразу перед остановкой или сразу после. И этот вариант оказался не рабочим =) Дело в том, что у разных остановок разные по длине примыкающие сегменты и если сегмент слишком короткий, то навигационные данные просто не попадали в них.
Второй вариант в двух словах – ТС прибыло на остановку, если оно находится на определенном расстоянии от нее. Имея в комплекте MongoDB и geo индексы нам не составило труда написать подходящие запросы. Размер полигона, в котором осуществляется поиск, выбран на основе частоты получения навигационных данных, т.е. мы выбирали размер полигона чтобы минимизировать его размер и при этом повысить вероятность того, что ТС в нем окажется.
В обоих случаях мы рассматривали только ТС, которые находятся на маршруте, для которых определен сегмент.
Прибытие ТС на остановку отображается на табло.
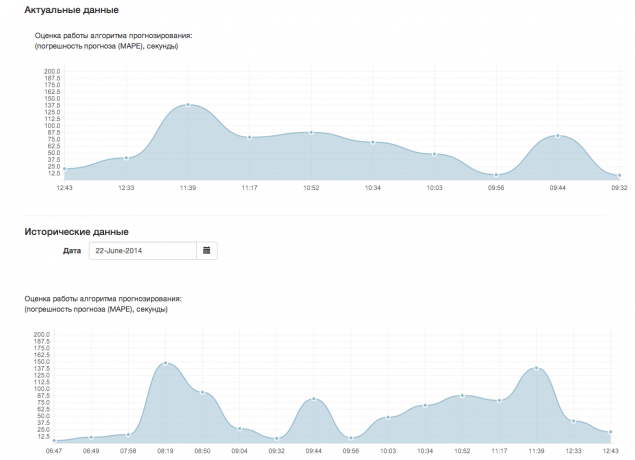
Определив, что ТС прибыло на остановку мы рассчитываем отклонение прогноза от реального времени с помощью показателя MAPE. Более подробно о нем можно прочитать тут.
Краткое изложение алгоритма.
Первый шаг – определить ближайшее по пути следования ТС к остановке, для него мы будем строить прогноз.
Для этого мы выбираем ТС из БД, которые следуют к остановке для которой мы делаем прогноз. При этом учитываем состояние ТС определенное ранее.
У каждого ТС есть положение на маршруте, а именно сегмент маршрута, на котором он находится.
У каждого сегмента есть порядковый номер по ходу движения ТС на маршруте. Выбираем из списка ТС тот, у которого порядковый номер сегмента больший, он и будет ближе всего к остановке.
Второй шаг – получить набор сегментов между ТС и остановкой. Как мы уже знаем ТС находится на сегменте, и каждая остановка «знает» какие сегменты к ней примыкают. Таким образом, мы имеем два сегмента и выбираем список между ними.
Третий шаг – подсчет времени.
Суммируем статическое и актуальное время прохождения сегментов между ТС и Остановкой. Чем дальше сегмент от остановки, тем больший вес имеет статистическое время и наоборот, для близких к остановке сегментов больший вес у актуального времени прохождения сегмента.
Сумма времен это и есть прогноз, когда придет ТС на остановку.
Как результат – мы взяли за основу алгоритм основанный на исторических и реальных данных [2] и в процессе реализации немного его модифицировали чтобы повысить точность прогноза и вот оно:

Теперь у нас есть своя маленькая диспетчерская! С обнаженными женщинами и стройкой =).
Мы разработали большое количество веб приложений с использованием связки AngularJS и Bootstrap, и в этот раз наш выбор пал на эти фреймворки. У нас не было высоких требований по дизайну, и мы использовали стандартные стили.
По сути, все что нужно — это управление клиентами и мониторинг работы алгоритма. Обе эти части системы живые и меняются со временем.
Администратор может создать и скачать стартовую страницу клиента, посмотреть статус клиентов и время последнего обновления информации на клиенте. Выключить, или переназначить клиента на другую остановку и ряд других сервисных функций.
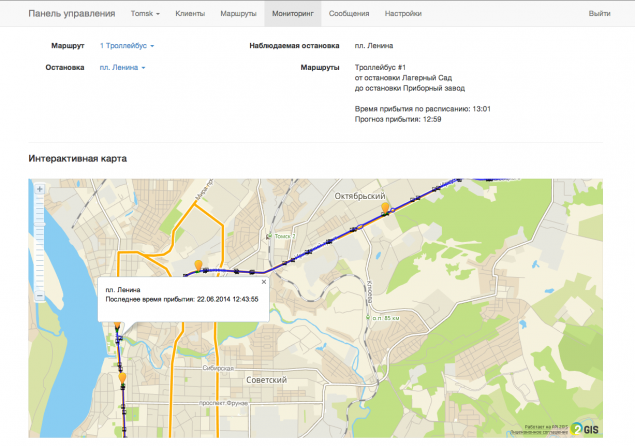
Для отслеживания работы алгоритма мы разработали раздел мониторинга, где администратор может отследить в реальном времени движение транспорта на карте и может оценить работу алгоритма на основе показателя MAPE, отображаемого на графике.
Это самое начало нашего табло. Эта страница работает без интернета, и, в случае подключения системы к интернет, страница пытается узнать у сервера, что она должна отобразить. В общем случае сервер присылает редирект на заданного клиента.
Стартовая страница загружается при монтаже или при подготовке оборудования с USB носителя.
Как и все веб части это приложение AngularJS + Bootstrap + WebSocket загружаемое с сервера в отличии от стартовой страницы.
При разработке пришлось сделать большой упор на рассмотрение внештатных ситуаций. Потеря подключения, закрытие маршрутов по причине каких-то событий (9 мая — парад) и т.д. Мы старались сделать табло как можно более самостоятельным и интеллектуальным. Нам кажется, что у нас получилось.
Немного поясним схему. Мы постарались представить и вникнуть в процесс создания и монтажа остановочных павильонов. И исходя из этого разработали систему управления. Все это похоже на небольшой квест.
Узнать, как проектируют и создают павильоны. Узнать, как, какими силами, в каком порядке и за какое время монтируется павильон.
Хочется сказать, что остановка которая была представлена на выставке была смонтирована за 5 часов, и на самом деле зная начинку и количество деталей это поразительная скорость!!! =) Ребята профессионалы!
За основу был взят самый обычный системник и 4-е ультрашироких монитора LG, которые будут работать попарно.
За сборку и покупку железа отвечали наши партнеры. И вот наступил долгожданный момент, когда нам позвонили и пригласили за железками. Не часто в работе программиста приходится делать что-то, что можно «потрогать» и это круто, что у нас есть такой проект!!!
Съездили, забрали, привезли, распаковали и установили. Казалось бы «Ура!» но это было только начало. Все звучит довольно просто, но глядя на картинку с четырьмя мониторами бывалый линускоид поймет сколько было сделано приседаний чтобы это все завести.
Итак, что же мы получили по итогу.
Был создан образ операционной системы на основе ОС Убунта, и были разработаны скрипты для запуска табло в работу. Процесс очень простой — до монтажа на компьютер для остановки устанавливается образ операционной системы и заливается стартовая страница в которой зашит уникальный идентификатор компьютера. Все настроено таким образом, что при загрузке системы табло откроется и заработает автоматически.
Для настройки расположения и разрешения дисплеев использовали программу XRANDR. В качестве браузера использовали CHROMIUM. Также не обошлось без нестандартного оконного менеджера чтобы заставить браузер работать в полноэкранном режиме на два монитора.
На момент когда все получилось мы испытали локальное счастье =). И весь офис в течении нескольких дней приходил «подождать» троллейбус на нашей собственной остановке «пл. Ленина, город Томск»!
4 июля час дня, звонок от партнеров о том, что выезжаем монтировать остановку. К слову сказать, Экспоцентр, где проходила выставка, находится на противоположном конце города и путь до туда занял почти два часа по обеденным пробкам =).

Заезд с оборудованием в выставочные павильоны в три часа дня, а закончить сборку необходимо в восемь вечера. За эти часы по среди выставки выросла красавица остановка. В сборке принимало участие много человек и каждый делал свою работу практически параллельно, поэтому почти удалось уложиться в отведенное время.

Мы хоть и программисты, но тоже вооружившись отвертками и шуруповертами смело взялись за дело =) Подвели интернет, установили наше «железо», питание, роутер, проводка до дисплеев… И вот все готово!

Стоит сказать, что наша экспозиция была самой популярной на выставке и многие и многие люди выражали надежду, что такие остановочные павильоны появятся в городах, хотя бы на центральных остановках!

Хочется сказать, что это проект приключение во многом и мы получили большое удовлетворение от проделанной работы.
Как видите мы получили простую, но в тоже время рабочую систему, но как было бы здорово, если бы сервисы пробок давали информацию в открытом виде и в алгоритм можно было внести соответствующие корректировки. А пока – увы, если случилась авария на дороге, которая спровоцировала пробку, то наше табло покажет, что задержка на неопределенное время.
Чтобы быть уж до конца честными и полезными ниже мы решили добавить список работ и литературы, который возможно не раз пригодится:
Источник: habrahabr.ru/company/eastbanctech/blog/227165/
Проект, о котором мы хотим рассказать получил у нас кодовое и немного смешное название «Смышлёные Остановки».

Итак, в чем суть – в городе «Н» есть городской транспорт на котором установлены системы слежения основанные на датчиках ГЛОНАСС, данные о перемещении стекаются в центральную диспетчерскую службу в виде постоянного потока сообщений от этих самых датчиков. Хочется разместить на остановке жидкокристаллическую панель, которая покажет, когда и какие транспортные средства, идущие по маршрутам прибудут.
Идея звучит просто и для ее реализации все есть – расписание маршрутов, сами маршруты, датчики и информация от них, координаты остановок, транспортные средства, вышедшие в рейс. Дело за малым – собрать это все в одну кучу и заставить работать.
Именно об этом мы и хотим сегодня рассказать, как от протокола общения с датчиками мы дошли до сборки железа для умной остановки и показали работающий прототип на выставке ТЕХНОПРОМ 2014.
Начнем с принципиальной архитектуры системы, а потом пробежимся по деталям.

Собираем данные в реальном времени
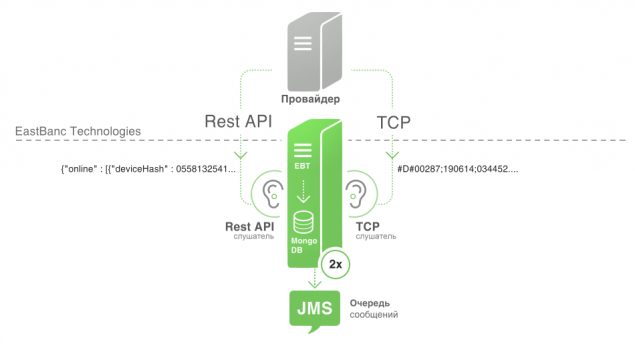
На данный момент нет единой системы или стандарта предоставления оперативных данных. В разных городах различные провайдеры, которые используют различные способы раздачи данных и различный формат и содержание. На данный момент мы столкнулись с двумя: передача данных по TCP и REST API на стороне провайдера.Пример пакета, который мы получаем по TCP
<code>#D#00287;190614;034452;5628.0000;N;8457.8226;E;0;272;123;12;gosnum:3:379,num:3:3 тролл </code>
Пример пакета из REST API
<code>{ "online" : [ { "deviceHash" : 0558132541, "name" : "Автобус Х564ВЕ96", "timestamp" : 1384710565, "latitude" : 50.65, "longitude" : 60.56, "speed" : 43.5, "course" : 120.1, "sats" : 8, "route" : "021-bus" }, ... ] } </code>Формат и содержание пакетов:
- Идентификатор устройства.
- Именование или идентификатор ТС – номер ТС и тип ТС.
- Время снятия данных.
- Широта и долгота.
- Скорость.
- Курс.
- Количество спутников.
- Идентификатор маршрута по которому движется ТС.
Рассмотрим оба варианта получения данных.
Функции и ответственность листнера:
- Получение “сырых” данных от провайдера.
- Парсинг данных и переработка в формат понимаемый системой. Из строки или из JSON в POJO.
- Пересылка полученного POJO с данными в JMS в заранее определенный топик.
- Отказоустойчивость. Для идентификации проблем в получении данных от провайдера или физической недоступности листнера, листнер должен отсылать ping пакеты в JMS.
- Сохранение POJO после парсинга в отдельную базу данных. Сохранение сырых данных длинной в неделю. Данный механизм сделан для того, чтобы иметь возможность накопить минимальную статистику работы алгоритма. В процессе жизни системы предполагалась доработка и донастройка алгоритма, и, чтобы иметь возможность проверить изменения в алгоритме, мы сохраняем данные. И умеем их проигрывать для накопления статистики и оценки работы алгоритма после изменений.
В случае с TCP мы указываем хост и порт, и провайдер данных отсылает пакеты на этот хост. Далее в дело вступает наш листенер TCP канала.
Мы использовали в качестве основы для TCP листнера Netty. Он очень прост в использовании и стабилен в работе. В случае с REST API мы использовали клиента Jsoup, который опрашивает api по таймеру.
Сам листнер, это консольное приложение с возможностью указать хост, порт и настройки для JMS и базы данных.
Процесс работы листнера:
- Получение данных по факту в случае с TCP или по таймеру в случае REST API.
- Разбор строки или JSON и создание объекта класса NavigationPackage.
- Отправка NavigationPackage в JMS.
- Сохранение NavigationPackage в базу.
- Отправка ping пакета в JMS (объект класса PingPackage).

Как результат каждый 30 секунд мы наполняем нашу базу данных информацией о реальных перемещениях транспортных средств (далее ТС).
Что нам нужно, чтобы разобраться с тем что происходит?
1. Сегментированные Маршруты.
2. Координаты остановок.
Мы взяли данные маршрутов и остановок из ГИС систем, обработали их таким образом, чтобы получить сегментированные маршруты
Отлично, теперь мы знаем кто и где едет, а значит пора начинать строить прогноз. Но перед этим для разрядки отвлечемся на цифры.
Для того чтобы лучше почувствовать, как это все работает покажем числа:
- 60 навигационных пакетов мы получаем от 8-ми троллейбусных маршрутов в минуту.
- 10 мс занимает построение прогноза для одной остановки.
- 600 мс занимает обработка одного навигационного пакета в среднем.
- 500 сегментов в среднем в одном маршруте.
- от 5 до 20 транспортных средств в среднем на маршруте для Томска.
- 168 остановок в Томске для 8-ми троллейбусных маршрутов
- 159 часов на двух человек – именно столько времени и таким количеством человек мы реализовали алгоритм целиком.
И конечно же скорость работы очень зависит от железа — все приведенные выше данные сняты с тестовой виртуальной машины.
Идем дальше, нужно выбрать алгоритм, реализовать его и показать результаты.
Как выбирали алгоритм.
Как и в любой другой раз мы не изобретаем велосипед, а стараемся осознать, что из имеющихся алгоритмов больше всего нам подходит. Перелопатили очень много работ не русских и русских ученых. На самом деле подходов к прогнозу не так много, и все алгоритмы — это модификации двух или трех основных.Первым шагом выбрали несколько алгоритмов, которые показались нам “проще”. На самом деле любой из основных алгоритмов имеет одинаковую сложность и в понимании и в реализации. Все отличие — в частных ситуациях, которые можно рассматривать, а можно опустить.
Нашим отправным шагом была исследовательская работа Ran Hee Jeong [1]. Полный список литературы и работ мы привели внизу статьи.
Итак, первым шагом мы выбрали несколько статей и научных работ об алгоритмах внутри команды. На доске прорисовали каждый и осознали все подводные камни и постарались предположить, как будут работать части, не описанные в статьях. Да, далеко не все можно найти. В нашем случае выбранные алгоритмы рассматривали именно прогноз, но не рассматривали способы сбора статистики прохождения маршрутов, на основе которой должен строится прогноз.
Вторым шагом мы устроили мозговой штурм на котором постарались рассказать и объяснить коллегам выбранный алгоритм. Всего в этом мероприятии принимало участие семь человек. По итогу, ответив на все вопросы, мы осознали, что сможем реализовать алгоритм за конечное время.
Дальше дело техники. Анализ, разбиение на задачи, оценка и план работ. К слову сказать, после такой предварительной работы у нас получилось сделать хорошую оценку, и что еще важнее — мы в нее уложились.
Какие критерии выбора алгоритма
При выборе алгоритма старались найти баланс между сложностью реализации и результатами работы алгоритмов. В итоге алгоритм основанный на исторических данных немного проигрывает алгоритму на основе нейронной сети по точности прогноза, но проще в реализации. У нас было требование добиться прогноза с погрешностью 30 – 60 секунд, что вполне приемлемо для простых пассажиров.Процесс разработки процессингового сервера
Небольшое отступление от технической части проекта в сторону ведения подобных проектов.Среди условий на старте мы имели одно очень важное ограничение, мы должны были получить рабочий прототип к определенному числу. Это было связанно с проведением выставки ТЕХНОПРОМ 2014. И при написании плана работ нам пришлось вынести в первую часть проекта разработку алгоритма целиком и клиентского приложения. Без системы управления и других необходимых вещей.
Хороший проект для заказчика, когда он видит прогресс работы как можно чаще. А в нашем случае у нас большая часть времени должна была уйти на реализацию алгоритма и его обкатку.
В итоге мы решили сделать тестовый стенд для одного маршрута и одной остановки.
Тестовый стенд это html + js + webSocket.
В процессе разработки у нас сначала появилась карта и маршрут на ней. Потом появились транспортные средства(ТС) и обновление их положения. Потом положение ТС на маршруте – сегмент и процент прохождения. Потом определение времени прибытия на остановку. Потом собственно прогноз и последним шагом разработки алгоритма был график на котором отображалась погрешность прогноза.
Такой подход дал возможность заказчику «в живую» наблюдать за процессом нашей работы. Все было очень прозрачно.

Далее более подробно о технической части процессинга и о работе алгоритма.
Работа процессингового сервера
Изначально при проектировании предполагалось иметь отдельный сервер для каждого города.Процесс работы и функции процессингового сервера:
- Получение данных из JMS.
- Определение положения ТС на маршруте и состояния ТС на основе навигационных данных.
- Рассчет статистики прохождения сегментов.
- Прогноз прибытия запускаемый для подключенных остановок по таймеру.
- REST API.
- WebSocket API.
Для WebSocket – Spring-WebSocket
Для REST API — Spring-WEB
Определение положения ТС на маршруте.

Сбор статистики прохождения ТС сегментов.

Построение прогноза прибытия на остановку.

Работа алгоритма
Работу алгоритма можно разбить на следующие части:- Определение положения ТС на маршруте и определение состояния ТС
- Расчет статистики прохождения сегментов маршрута и расчет актуального времени прохождения сегментов маршрута
- Определение прибытия на остановку и расчет погрешности прогноза
- Создание прогноза
Определение положения ТС на маршруте и определение состояния ТС
При получении навигационных данных запускается алгоритм нахождения положения ТС на маршруте. Положение ТС состоит из сегмента маршрута и процента его прохождения и сохраняется в БД вместе с ТС.Алгоритм работает следующим образом:
- Получить данные о маршруте и ТС из БД. Если ТС не существует, то создать его
- Поиск сегментов маршрута на заданном расстоянии от текущего положения ТС. Поиск осуществляется с помощью оператора MongoDB – near
- Для каждого сегмента вычисляется угол между вектором движения ТС и вектором движения по сегменту. Если разница этих углов минимальна и если она не превышает определенную ошибку, то система считает, что искомый сегмент найден
- Для найденного сегмента рассчитывается процент прохождения. Для этого делается проекция положения ТС на сегмент и рассчитывается процент от начала сегмента до проекции.
- После определения сегмента на котором находится ТС, определяем состояние тс. Всего четыре состояния Начальное, Конечное, Прогноз, Неизвестно. Начальное и конечное соответствуют первому сегменту маршрута и последнему. Прогноз – значит, что положение ТС определено. Неизвестно – если сегмент не был найден. Все состояния используются при построении прогноза и при расчете статистики
Расчет статистики прохождения сегментов маршрута и расчет актуального времени прохождения сегментов маршрута
Основой работы алгоритма является статистика.Маршрут разбит на сегменты и в процессе работы система накапливает статистику времени прохождения для каждого сегмента. Каждый сегмент имеет 90 статистических значений.
Разбиение следующее:
- Зима, лето, межсезонье
- Будни и выходные
- Каждый час, начиная с 6:00 до 21:00
Система самодостаточна и по мере работы статистика увеличивается и точность прогноза повышается.
Задача накопления статистики сводится к получению времени прохождения сегмента маршрута. Данное время добавляется в подходящий статистический интервал с учетом веса. Скорость изменения статистики обратна пропорциональна количеству измерений. Это с одной стороны позволит минимизировать врЕменные отклонения в прохождении сегментов, с другой учесть изменившуюся дорожную ситуацию в длительной перспективе.
Актуальное время прохождения сегмента – это последнее измерение времени прохождения сегмента на сегодня. С приходом нового дня эти данные обнуляются.
Сбор статистики — это та часть, которая слабо описана в документах, и это именно та часть, которую мы сделали на свое усмотрение.
Наша задача — получить время прохождения ТС по сегменту. В течении дня сохраняется каждое положение ТС на маршруте и время получения данных о положении ТС.
ТС проходит маршрут целиком, а именно оказывается на одном из конечных сегментов маршрута. Когда мы фиксируем этот факт, мы запускаем процесс подсчета времени прохождения сегментов по маршруту.
Рассмотрев имеющиеся сегменты и частоту получение данных мы выделили четыре ситуации:
Ситуация 1.

Ситуация 2.

Ситуация 3.

Ситуация 4.

Имея несколько точек положения ТС и время каждой точки мы можем рассчитать за какое время пройден сегмент целиком или его часть. В зависимости от ситуации мы игнорируем какие-то точки положения ТС, например, если их несколько на одном сегменте.
Определение прибытия на остановку и расчет погрешности прогноза
После определения текущего положения ТС на маршруте вычисляется следующая остановка для ТС и факт прибытия на остановку.Мы реализовали два варианта алгоритма прибытия.
Первый вариант в двух словах – ТС прибыло на остановку, если оно находится на сегменте сразу перед остановкой или сразу после. И этот вариант оказался не рабочим =) Дело в том, что у разных остановок разные по длине примыкающие сегменты и если сегмент слишком короткий, то навигационные данные просто не попадали в них.
Второй вариант в двух словах – ТС прибыло на остановку, если оно находится на определенном расстоянии от нее. Имея в комплекте MongoDB и geo индексы нам не составило труда написать подходящие запросы. Размер полигона, в котором осуществляется поиск, выбран на основе частоты получения навигационных данных, т.е. мы выбирали размер полигона чтобы минимизировать его размер и при этом повысить вероятность того, что ТС в нем окажется.
В обоих случаях мы рассматривали только ТС, которые находятся на маршруте, для которых определен сегмент.
Прибытие ТС на остановку отображается на табло.
Определив, что ТС прибыло на остановку мы рассчитываем отклонение прогноза от реального времени с помощью показателя MAPE. Более подробно о нем можно прочитать тут.
Создание прогноза
И вот пришел день, когда мы сделали все части кроме последней. Собственно, создание прогноза.Краткое изложение алгоритма.
- На входе мы имеем маршрут состоящий из сегментов. Для каждого сегмента мы знаем статистическое время прохождения и последнее актуальное время прохождения.
- Статистика выбирается на основе времени дня, дня недели и времени года.
- Последнее актуальное время прохождение каждого сегмента используется для минимизации погрешности статистики.
Первый шаг – определить ближайшее по пути следования ТС к остановке, для него мы будем строить прогноз.
Для этого мы выбираем ТС из БД, которые следуют к остановке для которой мы делаем прогноз. При этом учитываем состояние ТС определенное ранее.
У каждого ТС есть положение на маршруте, а именно сегмент маршрута, на котором он находится.
У каждого сегмента есть порядковый номер по ходу движения ТС на маршруте. Выбираем из списка ТС тот, у которого порядковый номер сегмента больший, он и будет ближе всего к остановке.
Второй шаг – получить набор сегментов между ТС и остановкой. Как мы уже знаем ТС находится на сегменте, и каждая остановка «знает» какие сегменты к ней примыкают. Таким образом, мы имеем два сегмента и выбираем список между ними.
Третий шаг – подсчет времени.
Суммируем статическое и актуальное время прохождения сегментов между ТС и Остановкой. Чем дальше сегмент от остановки, тем больший вес имеет статистическое время и наоборот, для близких к остановке сегментов больший вес у актуального времени прохождения сегмента.
Сумма времен это и есть прогноз, когда придет ТС на остановку.
Как результат – мы взяли за основу алгоритм основанный на исторических и реальных данных [2] и в процессе реализации немного его модифицировали чтобы повысить точность прогноза и вот оно:

Теперь у нас есть своя маленькая диспетчерская! С обнаженными женщинами и стройкой =).
Управляем табло
Мы задумывали систему как большое и комплексное решение, для сетей остановок в различных городах. Такая система не может работать без управления и контроля.
Состав системы
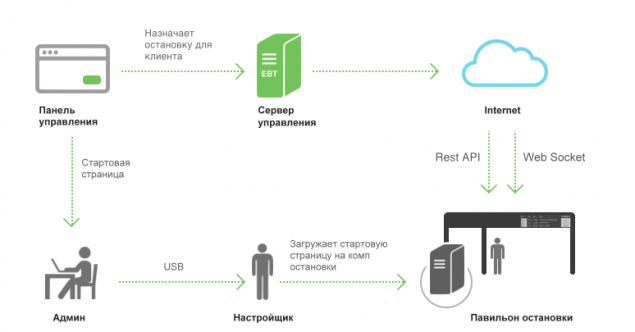
Всю системы можно разбить на следующие составляющие:- Панель управления.
- Стартовая страница.
- Клиент.
Панель управления
Панель управления — это веб приложение для создания, управления и мониторинга клиентской сети. Вторая часть проекта заключалась в разработке этого приложения.Мы разработали большое количество веб приложений с использованием связки AngularJS и Bootstrap, и в этот раз наш выбор пал на эти фреймворки. У нас не было высоких требований по дизайну, и мы использовали стандартные стили.
По сути, все что нужно — это управление клиентами и мониторинг работы алгоритма. Обе эти части системы живые и меняются со временем.
Администратор может создать и скачать стартовую страницу клиента, посмотреть статус клиентов и время последнего обновления информации на клиенте. Выключить, или переназначить клиента на другую остановку и ряд других сервисных функций.

Для отслеживания работы алгоритма мы разработали раздел мониторинга, где администратор может отследить в реальном времени движение транспорта на карте и может оценить работу алгоритма на основе показателя MAPE, отображаемого на графике.

Стартовая страница
Небольшое статическое html+js приложение, которое общается с сервером по WebSocket и откликается на действия администратора, при этом восстанавливает подключение в случае обрыва.Это самое начало нашего табло. Эта страница работает без интернета, и, в случае подключения системы к интернет, страница пытается узнать у сервера, что она должна отобразить. В общем случае сервер присылает редирект на заданного клиента.
Стартовая страница загружается при монтаже или при подготовке оборудования с USB носителя.
Клиент
Наше обожаемое табло =). Мы старались выдержать очень простой и понятный дизайн.Как и все веб части это приложение AngularJS + Bootstrap + WebSocket загружаемое с сервера в отличии от стартовой страницы.
При разработке пришлось сделать большой упор на рассмотрение внештатных ситуаций. Потеря подключения, закрытие маршрутов по причине каких-то событий (9 мая — парад) и т.д. Мы старались сделать табло как можно более самостоятельным и интеллектуальным. Нам кажется, что у нас получилось.
Немного поясним схему. Мы постарались представить и вникнуть в процесс создания и монтажа остановочных павильонов. И исходя из этого разработали систему управления. Все это похоже на небольшой квест.
Узнать, как проектируют и создают павильоны. Узнать, как, какими силами, в каком порядке и за какое время монтируется павильон.
Хочется сказать, что остановка которая была представлена на выставке была смонтирована за 5 часов, и на самом деле зная начинку и количество деталей это поразительная скорость!!! =) Ребята профессионалы!
Собираем железо
Было подобрано специализированное промышленное оборудование, которое способно выдержать агрессивные условия работы. Это касается и дисплеев и компьютера. Данное оборудование стоит на порядок дороже и не продается, так сказать, под рукой. Поэтому для выставки, которая уже должна была вот-вот случится мы выбрали более бюджетный вариант.За основу был взят самый обычный системник и 4-е ультрашироких монитора LG, которые будут работать попарно.
- Блок питания 450W ATX v.2.2 INWIN (RB-S450T7)
- Видеокарта Asus GF-GT610, 1Gb DDR3, 64bit, PCI-E, DVI, HDMI, LP, Retail (GT610-SL-1GD3-L)
- Жесткий диск Toshiba 1Tb DT01ACA100 3.5" 7200rpm 32Mb SATA3
За сборку и покупку железа отвечали наши партнеры. И вот наступил долгожданный момент, когда нам позвонили и пригласили за железками. Не часто в работе программиста приходится делать что-то, что можно «потрогать» и это круто, что у нас есть такой проект!!!
Съездили, забрали, привезли, распаковали и установили. Казалось бы «Ура!» но это было только начало. Все звучит довольно просто, но глядя на картинку с четырьмя мониторами бывалый линускоид поймет сколько было сделано приседаний чтобы это все завести.
Итак, что же мы получили по итогу.
Был создан образ операционной системы на основе ОС Убунта, и были разработаны скрипты для запуска табло в работу. Процесс очень простой — до монтажа на компьютер для остановки устанавливается образ операционной системы и заливается стартовая страница в которой зашит уникальный идентификатор компьютера. Все настроено таким образом, что при загрузке системы табло откроется и заработает автоматически.
Для настройки расположения и разрешения дисплеев использовали программу XRANDR. В качестве браузера использовали CHROMIUM. Также не обошлось без нестандартного оконного менеджера чтобы заставить браузер работать в полноэкранном режиме на два монитора.
На момент когда все получилось мы испытали локальное счастье =). И весь офис в течении нескольких дней приходил «подождать» троллейбус на нашей собственной остановке «пл. Ленина, город Томск»!
День X
Первая часть проекта готова, готово и табло и софт и железо. Все готово к выставке ТЕХНОПРОМ 2014.4 июля час дня, звонок от партнеров о том, что выезжаем монтировать остановку. К слову сказать, Экспоцентр, где проходила выставка, находится на противоположном конце города и путь до туда занял почти два часа по обеденным пробкам =).

Заезд с оборудованием в выставочные павильоны в три часа дня, а закончить сборку необходимо в восемь вечера. За эти часы по среди выставки выросла красавица остановка. В сборке принимало участие много человек и каждый делал свою работу практически параллельно, поэтому почти удалось уложиться в отведенное время.

Мы хоть и программисты, но тоже вооружившись отвертками и шуруповертами смело взялись за дело =) Подвели интернет, установили наше «железо», питание, роутер, проводка до дисплеев… И вот все готово!

Стоит сказать, что наша экспозиция была самой популярной на выставке и многие и многие люди выражали надежду, что такие остановочные павильоны появятся в городах, хотя бы на центральных остановках!

Хочется сказать, что это проект приключение во многом и мы получили большое удовлетворение от проделанной работы.
Как видите мы получили простую, но в тоже время рабочую систему, но как было бы здорово, если бы сервисы пробок давали информацию в открытом виде и в алгоритм можно было внести соответствующие корректировки. А пока – увы, если случилась авария на дороге, которая спровоцировала пробку, то наше табло покажет, что задержка на неопределенное время.
Чтобы быть уж до конца честными и полезными ниже мы решили добавить список работ и литературы, который возможно не раз пригодится:
- Ran Hee Jeong. The prediction of bus arrival time using automatic vehicle location systems data: Submitted to the Office of Graduate Studies of Texas A&M University in partial fulfillment of the requirements for the degree of doctor of philosophy: Civil Engineering / Ran Hee Jeong. — Beon 1–Dong, Kangbuk-Gu, Seoul, Korea, 2004.
- Погребной В. Ю., Фадеев А. С. Алгоритмизация прогнозирования времени прибытия пассажирского транспорта на остановку с использованием модели, основанной на исторических и реальных данных. Интернет-журнал «НАУКОВЕДЕНИЕ» Выпуск 6, ноябрь – декабрь 2013
- Johnson C.M. Automatic Vehicle Location Successful Transit Applications: A Cross- Cutting Study / E.L. Thomas. — Federal Transit Administration, U.S. Department of Transportation, 2000.
- Глобальная навигационная спутниковая система ГЛОНАСС. Интерфейсный контрольный документ: навигационный радиосигнал в диапазонах L1, L2 (редакция 5.1) [Электронный ресурс]. — Москва, 2008. — Режим доступа: www.aggf.ru/gnss/glon/ikd51ru.pdf, свободный. (Дата обращения: 15.03.2013).
- Advanced Public Transportation Systems: The State of the Art Update 2000. Publication FTA-MA-26-7007-00-1 / R.F. Casey, L.N. Labell, L. Moniz, J.W. Royal, M. Sheehan, et al. — Federal Transit Administration, U.S. Department of Transportation, 2000.
- Панамарева О.Н. Интеллектуальные транспортные системы — инструмент повышения эффективности экономики России в целом, 2013.
- Dihua Sun. Predicting Bus Arrival Time on the Basis of Global Positioning System Data / Dihua Sun // Transportation Research Record: Journal of the Transportation Research Board, No. 2034, Transportation Research Board of the National Academies. — Washington, D.C., 2007. — P. 62–72.
- SeemaS.R. Dynamic Bus Arrival Time Prediction Using GPS Data / S.R. Seema // 10th National Conference on Technological Trends (NCTT09). — 2009. — P. 193-197.
- Seyed Mojtaba Tafaghod Sadat Zadeh. А survey on application of artificial intelligence for bus arrival time prediction / Seyed Mojtaba Tafaghod Sadat Zadeh, Toni Anwar, Mina Basirat // Journal of Theoretical and Applied Information Technology. — 2012. — P. 516-525.
- Wei-Hua Lin. Modeling Schedule Recovery Processes in Transit Operations for Bus Arrival Time Prediction / Wei-Hua Lin // Department of Systems and Industrial Engineering The University of Arizona. — 2004.
- Wei-Hua Lin. An experimental study on real time bus arrival time prediction with gps data / Wei-Hua Lin. — Center for Transportation Research And Department of Civil and Environmental Engineering 200 Patton Hall Virginia Polytechnic Institute & State University Blacksburg.
Источник: habrahabr.ru/company/eastbanctech/blog/227165/
Портал БАШНЯ. Копирование, Перепечатка возможна при указании активной ссылки на данную страницу.