2222
Parada Smyshlёnye
Hoy tenemos una oportunidad inusual para compartir nuestras experiencias con habrosoobschestvom. No es ningún secreto que la mayoría de los proyectos y productos que creamos un mundo vivo "virtual", y que no siempre se puede remontar de nuevo al principio y el fin de todo lo que trabajamos en la vida real.
El proyecto, que queremos decirle que tenemos un código y un poco de un nombre divertido "Smyshlёnye Detener."

Así que, ¿cuáles son - en la ciudad de "H" es el transporte urbano, que estableció un sistema de seguimiento basado en sensores de datos GLONASS móviles rebaño al servicio de despacho central en forma de un flujo constante de informes de estos mismos sensores. Me gustaría hacer una parada en un panel de cristal líquido que mostrará cuándo y qué vehículos se ejecutan en rutas para llegar.
La idea suena simple, y para darse cuenta de que es todo lo que hay - el horario de las rutas, las propias rutas, los sensores y la información de los mismos, las coordenadas de paradas, vehículos, publicados en vuelo. El caso de la pequeña - para reunir todo en un solo montón y ponerse a trabajar.
Esto es lo que queremos decirles hoy como el protocolo para comunicarse con los sensores que llegamos a la asamblea de hierro para la parada inteligente y mostró un prototipo de trabajo en la feria Technoprom 2014.
Vamos a empezar con la arquitectura fundamental del sistema, y luego ir a través de los detalles.
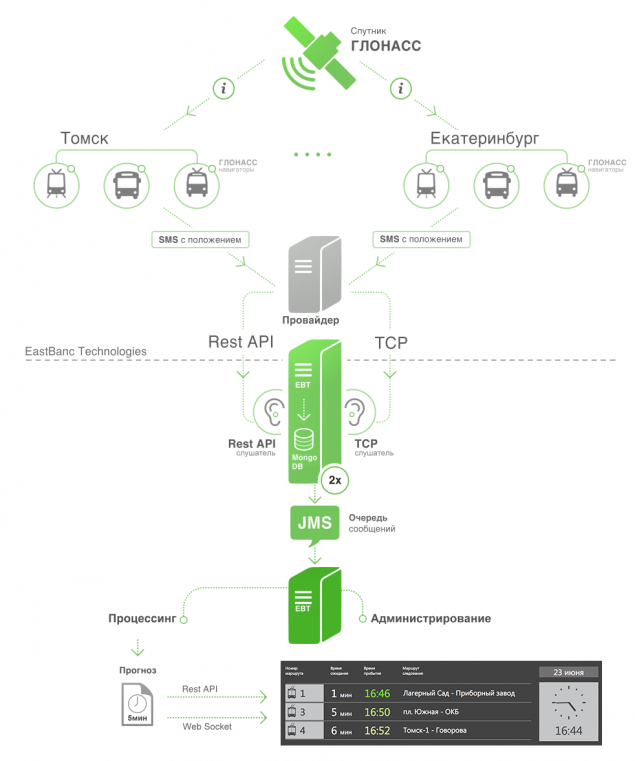
Recopilar datos en tiempo real h4> Actualmente no existe un solo sistema o estándar de los datos operativos. En diferentes ciudades de diferentes proveedores que utilizan diferentes métodos de distribución de datos en diferentes formatos y contenidos. Por el momento, nos enfrentamos a dos:. La transmisión de datos a través de TCP y API REST en el lado del proveedor
Para REST API -
Primavera-WEB
Posicionar el vehículo en la ruta.
Estadísticas Gathering paso de los segmentos de vehículos.
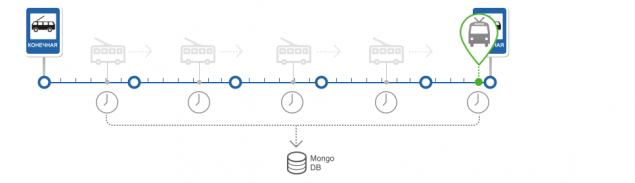
Construcción de la llegada de previsión en la parada.
El algoritmo h4> del algoritmo se puede dividir en las siguientes partes:
Colocación del vehículo para la ruta y determinar el estado del vehículo El cálculo de los tramos de ruta estadísticas de paso y calcular el tiempo real de los segmentos de transmisión de la ruta li> La definición de llegar a una parada y el cálculo del error de predicción < / Crear el pronóstico
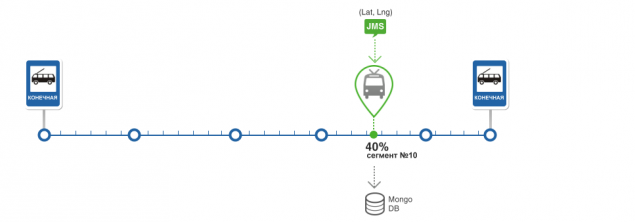
determinar la posición del vehículo sobre la ruta y determinar el estado del vehículo h5> En la preparación de los datos de navegación se ejecuta algoritmo para encontrar la posición del vehículo a lo largo de la ruta. Coloque el vehículo consta de un segmento de la ruta y el porcentaje de su paso y se almacena en la base de datos junto con el vehículo.
Obtenga los detalles sobre la ruta y el vehículo de la base de datos. Si el vehículo no existe, crearlo Búsqueda de segmentos de ruta a una distancia predeterminada desde la posición actual del vehículo. La búsqueda se realiza utilizando el operador MongoDB - cerca Para cada segmento se calcula el ángulo entre el movimiento del vehículo y un vector de movimiento para el segmento. Si la diferencia de estos ángulos es mínimo y si no supera un cierto error, el sistema considera que el segmento deseado encontró En el segmento encontrado calculado el porcentaje de aprobación. Por esta es la proyección de la posición del vehículo en el segmento, y el porcentaje se calcula a partir del principio del segmento a la proyección. Una vez que el segmento en que el vehículo, determina el estado de la TC. Son cuatro estado inicial, por supuesto, el panorama no está claro. El partido primero y último segmentos inicial y final de la ruta. Forecast - significa que se determina la posición del vehículo. Desconocido - si no se ha encontrado el segmento. Todos los estados se utilizan para construir el pronóstico y el cálculo de las estadísticas
Estadísticas de cálculo tramos de ruta de paso y el cálculo del tiempo de viaje real de los segmentos de ruta h5> La base del algoritmo es una estadística.
invierno, verano, fuera de la temporada Día de la semana y el fin de semana Cada hora de comenzar 6:00-21:00
El sistema es autónomo y funciona como estadísticas aumenta y una mayor precisión de los pronósticos.
El problema de la acumulación de estadísticas se reduce a la obtención de tramo de ruta el tiempo de viaje. Esta vez se añade a un intervalo adecuado, teniendo en cuenta los pesos estadísticos. La tasa de las estadísticas de cambio inversamente proporcionales mediciones. Por un lado minimizará las desviaciones temporales en el paso de los segmentos, el otro a tener en cuenta la nueva situación en el camino en el largo plazo.
El tiempo real del segmento - esta es la última medición segmento paso del tiempo hoy. Con la llegada de un nuevo día, estos datos se borran.
Recopilación de estadísticas - esta es la parte que está mal se describe en los documentos, y esta es la parte que hemos hecho a su discreción
.
Nuestra tarea - para conseguir el paso del segmento de vehículos. Durante el día el vehículo se almacena cada posición en la ruta y hora de recepción de los datos sobre la situación del vehículo.
Vehículo ruta pasa por completo, es decir, se convierte en uno de los tramos extremos de la ruta. Cuando nos fijamos este hecho, vamos a iniciar el proceso de contar el paso de los segmentos de tiempo de la ruta.
Habiendo examinado los segmentos y la frecuencia de la obtención de datos, hemos identificado cuatro situaciones:
Situación 1.

Situación 2.
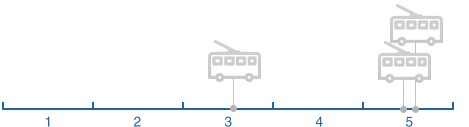
Situación 3.
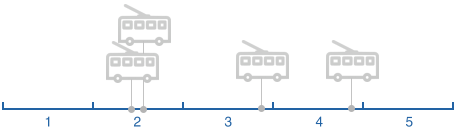
Situación 4.
Con múltiples puntos del vehículo y la posición de cada punto del tiempo, podemos calcular cuánto tiempo pasó segmento de la totalidad o parte de ella. Dependiendo de la situación, ignoramos algunos puntos de la posición del vehículo, por ejemplo, si más de un segmento.
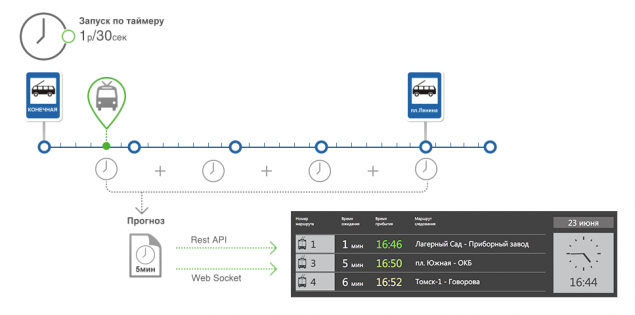
La definición de llegar a una parada y el cálculo del error de predicción h5> Después de determinar la posición actual del vehículo en la ruta se calcula de la siguiente parada y el hecho de que la llegada del vehículo a una parada.
Crear previsión h5> Y entonces llegó el día en que lo hemos hecho todas las piezas excepto la última. En realidad, el establecimiento de la previsión.
En la entrada tenemos una ruta que consta de segmentos. Para cada segmento, sabemos que el tiempo de viaje estadística y la última vez que la corriente que pasa. Estadísticas se selecciona en función de la hora del día, día de la semana y época del año. La última vez que el flujo real de cada segmento se utiliza para minimizar las estadísticas de error.
El primer paso - para determinar la ruta más cercana para el vehículo a una parada, para él, vamos a construir un pronóstico
.
Para ello, se elige un vehículo de la base de datos, que es seguido por una parada para los que hacemos el pronóstico. Esto tiene en cuenta el estado del vehículo como se ha definido anteriormente.
Cada TC tiene una posición en la ruta, a saber, el segmento de la ruta en la que se encuentra.
Cada segmento tiene un número de serie del vehículo mientras se mueve en la ruta. Elija de la lista de la Unión Aduanera, que tiene el número de serie del segmento más grande, que será lo más parecido a un alto.
El segundo paso - para conseguir un conjunto de segmentos entre el vehículo y la parada. Como ya sabemos el vehículo está en el segmento, y cada parada "sabe" qué segmentos contiguos. Por lo tanto, tenemos dos segmentos y seleccionamos la lista entre ellos.
El tercer paso - contar el tiempo
. Resumimos la corriente tiempo estático y del segmento entre el vehículo y detenerlo. El segmento más lejos de la parada, más peso es el momento de estadística y viceversa, por cerca de un segmentos halt más peso en el momento del paso del segmento actual.
La cantidad de veces que este es el pronóstico cuando el vehículo se detenga.
Como resultado - que tenemos una base para un algoritmo basado en datos históricos y reales [2] y en la ejecución de su modificado ligeramente para mejorar la exactitud de predicción y aquí está:

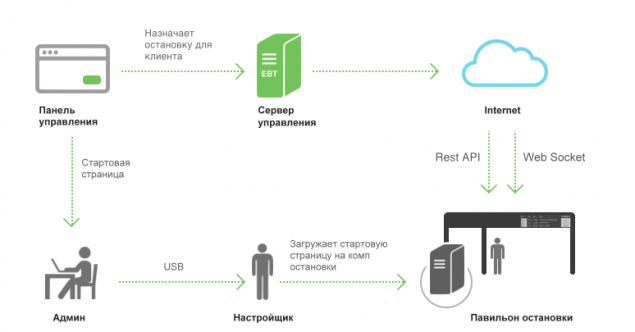
Ahora tenemos nuestra propia pequeña sala de control! Con las mujeres desnudas y el sitio de construcción =).
Administrar marcador h4> Hemos concebido el sistema como solución grande y complejo para las redes de escalas en diferentes ciudades. Tal sistema no puede funcionar sin la gestión y control.
El proyecto, que queremos decirle que tenemos un código y un poco de un nombre divertido "Smyshlёnye Detener."

Así que, ¿cuáles son - en la ciudad de "H" es el transporte urbano, que estableció un sistema de seguimiento basado en sensores de datos GLONASS móviles rebaño al servicio de despacho central en forma de un flujo constante de informes de estos mismos sensores. Me gustaría hacer una parada en un panel de cristal líquido que mostrará cuándo y qué vehículos se ejecutan en rutas para llegar.
La idea suena simple, y para darse cuenta de que es todo lo que hay - el horario de las rutas, las propias rutas, los sensores y la información de los mismos, las coordenadas de paradas, vehículos, publicados en vuelo. El caso de la pequeña - para reunir todo en un solo montón y ponerse a trabajar.
Esto es lo que queremos decirles hoy como el protocolo para comunicarse con los sensores que llegamos a la asamblea de hierro para la parada inteligente y mostró un prototipo de trabajo en la feria Technoprom 2014.
Vamos a empezar con la arquitectura fundamental del sistema, y luego ir a través de los detalles.

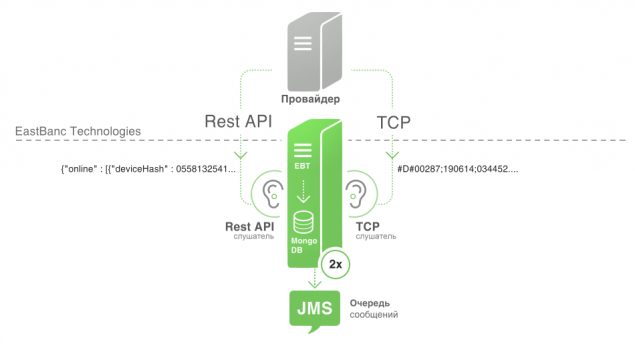
Recopilar datos en tiempo real h4> Actualmente no existe un solo sistema o estándar de los datos operativos. En diferentes ciudades de diferentes proveedores que utilizan diferentes métodos de distribución de datos en diferentes formatos y contenidos. Por el momento, nos enfrentamos a dos:. La transmisión de datos a través de TCP y API REST en el lado del proveedor
Un ejemplo de un paquete que tenemos en
TCP
& lt; código de & gt; # D # 00287; 190614; 034452; 5628,0000; N; 8457,8226; E; 0; 272; 123; 12; gosnum: 3: 379, núm: 3: 3 Troll & lt; / código de & gt; < / pre>
Un ejemplo de un paquete de REST
API
& lt; código de & gt; {& quot; línea & quot; : [{& Quot; deviceHash & quot; : 0558132541, & quot; nombre & quot; : & Quot; bus H564VE96 & quot; & quot; marca de tiempo & quot; : 1384710565, & quot; latitud & quot; : 50,65, & quot; la longitud & quot; : 60,56, & quot; la velocidad de & quot; : 43.5, & quot; por supuesto & quot; : 120,1, & quot; SAT & quot; 8 & quot; ruta & quot; : & Quot; 021-bus & quot; }, ...]} & Lt; / Código & gt; pre>
El formato y contenido paquetes:
- Device ID
- El nombramiento o identificador TA -.... número de TC y el tipo de vehículo
- los datos de tiempo de lanzamiento
- La latitud y longitud < /
- Velocidad.
- Por supuesto.
- El número de satélites.
- El ID de la ruta a lo largo de la cual el vehículo.
Considere las dos opciones la recepción de datos.
Roles y responsabilidades listnera:
- Obtener datos "en bruto" del proveedor.
- de análisis y procesamiento de datos en un formato comprensible para el sistema. A partir de la línea, o de JSON en POJO.
- Expedición reciben datos POJO a JMS en un tema predeterminado.
- de conmutación por error. Para identificar los problemas en la obtención de datos del proveedor o el listnera inaccesibilidad física, listner debe enviar paquetes ping a JMS.
- Ahorro POJO después de analizar en una base de datos independiente. Aseguramiento de los datos en bruto en una semana larga. Este mecanismo se hace con el fin de ser capaz de acumular estadísticas del algoritmo es mínima. Durante la vida útil del sistema supone la conclusión y adaptar el algoritmo, y para poder comprobar los cambios en el algoritmo, almacenamos datos. Y saben cómo jugar para acumular estadísticas y evaluación del algoritmo después de los cambios.
En el caso de TCP, especificamos el host y el puerto, y el proveedor de datos envía paquetes a ese host. Entonces entra en nuestro canal de escucha TCP.
Se utilizó como base para listnera TCP Netty. Es muy fácil de usar y estable en funcionamiento. En el caso de la API REST utilizamos cliente Jsoup, que temporizador encuestas api.
Sí Listner, es una aplicación de consola con la posibilidad de especificar el host, el puerto y la configuración de JMS y base de datos.
El proceso de listnera trabajo:
- Obtener datos en el caso de TCP o temporizador cuando la API REST.
- Análisis de cuerda o JSON, y crear un objeto de clase NavigationPackage.
- Envío NavigationPackage a JMS .
- Ahorro NavigationPackage la base de datos.
- Enviar paquete ping a JMS (clase de objeto PingPackage).
Como resultado, cada 30 segundos, llenan nuestra base de datos de información sobre los movimientos reales de los vehículos (en adelante TC).
Lo que tenemos que entender lo que está pasando con eso?
1. Rutas segmentado.
2. Coordina paradas.
B>
Nos tomamos estas rutas y las paradas de los sistemas de información geográfica, para tratarlos de tal manera que se obtenga rutas segmentadas
Bueno, ahora que sabemos quiénes son y dónde se va, así que es hora de empezar a construir el pronóstico. Pero antes de eso, para la aprobación de la gestión en la digresión números.
Con el fin de tener una mejor idea de cómo funciona todo muestran el número:
- 60 paquetes náuticas que obtenemos de 8 rutas de trolebuses en un minuto.
- 10 ms es la construcción de la previsión de una parada.
- 600 ms se tarda en procesar un paquete de navegación de media.
- 500 segmentos , en promedio, la misma ruta.
- 5 a 20 vehículos promedio en ruta a Tomsk.
- 168 paradas en Tomsk por 8 rutas de trolebuses li >
- 159 horas para dos personas -. que es la cantidad de tiempo y tanta gente, se ha implementado un algoritmo completo
Y, por supuesto, la velocidad es muy dependiente de hierro - todos los datos anteriores se retira de la máquina virtual de prueba
.
Adelante, elegir un algoritmo para ponerlo en práctica y demostrar resultados.
¿Cómo elegir el algoritmo. h4> Al igual que en cualquier otro momento, que no reinventar la rueda y tratar de darse cuenta de que los algoritmos disponibles más nos convenga. Paleé mucho trabajo no es ruso, y los científicos rusos. De hecho enfoque para la predicción no es tanto, y todos los algoritmos - una modificación de los dos o tres principales.
El primer paso ha seleccionado varios algoritmos que nos parecían "más fácil". De hecho, cualquiera de los algoritmos básicos tienen la misma complejidad en la comprensión y aplicación. Toda diferencia - en situaciones particulares que pueden considerarse, y pueden ser omitidos.
Nuestro paso de partida fue la investigación Ran Hee Jeong [1]. Lista completa de las obras de la literatura, y nos han dado en la parte inferior del artículo.
Así, el primer paso que eligió diversos artículos y trabajos de investigación sobre los algoritmos dentro del equipo. A bordo de cada atraídos y se dio cuenta de todas las trampas y trató de asumir como parte de la obra, no se describe en el artículo. Sí, no todo se puede encontrar. En este caso, los algoritmos seleccionados considerados se pronostica, pero no consideraron formas de recolectar estadísticas pasan rutas en las que debe construirse el pronóstico.
El segundo paso que tenía una sesión de lluvia de ideas en la que trató de decirle a sus colegas y explicar el algoritmo elegido. En total, este evento contó con la presencia de siete personas. Según los resultados, respondiendo a todas las preguntas, nos dimos cuenta de que podíamos implementar el algoritmo en un tiempo finito.
Siguiente truco. División de Análisis en tareas, evaluación y plan de trabajo. Por cierto, después de este trabajo preliminar que tenemos que hacer una buena evaluación y lo más importante - lo perdimos
.
¿Cuáles son los criterios para el algoritmo de selección h4> Al seleccionar un algoritmo trataron de encontrar un equilibrio entre la complejidad de la aplicación y los resultados de los algoritmos. Como resultado, el algoritmo se basa en datos históricos, pierde un poco de algoritmos basados en la red neural exactitud de predicción, pero es más fácil de implementar. Tuvimos un requisito para lograr el pronóstico con una precisión de 30 -. 60 segundos, lo cual es bastante aceptable para los pasajeros ordinarios
El proceso de desarrollo de un servidor de procesamiento h4> Una pequeña digresión sobre la parte técnica del proyecto para el lado de hacer este tipo de proyectos.
Entre las condiciones al inicio tuvimos una limitación muy importante, tuvimos que conseguir un prototipo de trabajo a un número determinado. Se conecta con la exposición Technoprom 2014. Y en la redacción del plan de trabajo que tuvimos que soportar en la primera parte del desarrollo del proyecto del algoritmo y todo el cliente. Sin gobernanza y otras cosas necesarias.
Un buen proyecto para el cliente, cuando ve el progreso de los trabajos lo antes posible. Y en nuestro caso tenemos una gran parte del tiempo era dejar para la implementación del algoritmo y su rodaje.
Como resultado, hemos decidido hacer un banco de pruebas para una ruta y una parada.
El banco de pruebas es html + js + WebSocket. B>
Durante el proceso de desarrollo que apareció por primera vez en el mapa y la ruta misma. Luego vinieron los vehículos (TC) y actualizar su estado. A continuación, la posición del vehículo en la ruta - un segmento y el porcentaje de fallecimiento. Entonces, el momento de la llegada de la parada de autobús. Entonces la previsión actual y el último paso fue el desarrollo de la gráfica algoritmo que muestra el error de pronóstico.
Este enfoque hizo posible que el cliente "en vivo" monitorear el proceso de nuestro trabajo. Todo era muy transparente.
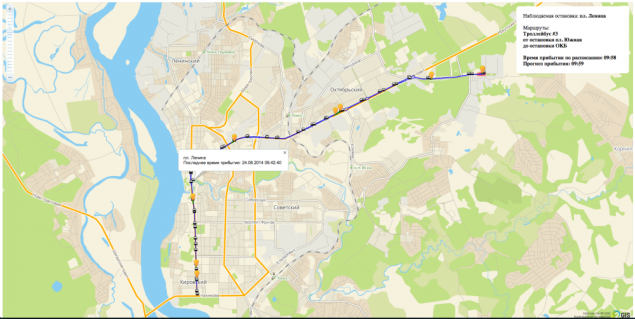
Más detalles en la parte técnica de la transformación y el algoritmo.
Trabajo Processing Server h4> Originalmente, se suponía que el diseño para tener un servidor separado para cada ciudad.
El proceso de trabajo y las funciones del servidor de procesamiento:
- Obtener datos de JMS.
- Colocación del vehículo para la ruta y el estado del vehículo en base a los datos de navegación.
- Calcular Estadísticas segmentos de paso.


Para REST API -
Primavera-WEB
Posicionar el vehículo en la ruta.

Estadísticas Gathering paso de los segmentos de vehículos.

Construcción de la llegada de previsión en la parada.

El algoritmo h4> del algoritmo se puede dividir en las siguientes partes:
Colocación del vehículo para la ruta y determinar el estado del vehículo El cálculo de los tramos de ruta estadísticas de paso y calcular el tiempo real de los segmentos de transmisión de la ruta li> La definición de llegar a una parada y el cálculo del error de predicción < / Crear el pronóstico determinar la posición del vehículo sobre la ruta y determinar el estado del vehículo h5> En la preparación de los datos de navegación se ejecuta algoritmo para encontrar la posición del vehículo a lo largo de la ruta. Coloque el vehículo consta de un segmento de la ruta y el porcentaje de su paso y se almacena en la base de datos junto con el vehículo.
El algoritmo funciona de la siguiente manera:
Obtenga los detalles sobre la ruta y el vehículo de la base de datos. Si el vehículo no existe, crearlo Búsqueda de segmentos de ruta a una distancia predeterminada desde la posición actual del vehículo. La búsqueda se realiza utilizando el operador MongoDB - cerca Para cada segmento se calcula el ángulo entre el movimiento del vehículo y un vector de movimiento para el segmento. Si la diferencia de estos ángulos es mínimo y si no supera un cierto error, el sistema considera que el segmento deseado encontró En el segmento encontrado calculado el porcentaje de aprobación. Por esta es la proyección de la posición del vehículo en el segmento, y el porcentaje se calcula a partir del principio del segmento a la proyección. Una vez que el segmento en que el vehículo, determina el estado de la TC. Son cuatro estado inicial, por supuesto, el panorama no está claro. El partido primero y último segmentos inicial y final de la ruta. Forecast - significa que se determina la posición del vehículo. Desconocido - si no se ha encontrado el segmento. Todos los estados se utilizan para construir el pronóstico y el cálculo de las estadísticas Estadísticas de cálculo tramos de ruta de paso y el cálculo del tiempo de viaje real de los segmentos de ruta h5> La base del algoritmo es una estadística.
La ruta se divide en segmentos, y durante la operación, el sistema recoge estadísticas de tiempo de tránsito para cada segmento. Cada segmento 90 tiene un valor estadístico.
La división de los siguientes:
invierno, verano, fuera de la temporada Día de la semana y el fin de semana Cada hora de comenzar 6:00-21:00 El sistema es autónomo y funciona como estadísticas aumenta y una mayor precisión de los pronósticos.
El problema de la acumulación de estadísticas se reduce a la obtención de tramo de ruta el tiempo de viaje. Esta vez se añade a un intervalo adecuado, teniendo en cuenta los pesos estadísticos. La tasa de las estadísticas de cambio inversamente proporcionales mediciones. Por un lado minimizará las desviaciones temporales en el paso de los segmentos, el otro a tener en cuenta la nueva situación en el camino en el largo plazo.
El tiempo real del segmento - esta es la última medición segmento paso del tiempo hoy. Con la llegada de un nuevo día, estos datos se borran.
Recopilación de estadísticas - esta es la parte que está mal se describe en los documentos, y esta es la parte que hemos hecho a su discreción
.
Nuestra tarea - para conseguir el paso del segmento de vehículos. Durante el día el vehículo se almacena cada posición en la ruta y hora de recepción de los datos sobre la situación del vehículo.
Vehículo ruta pasa por completo, es decir, se convierte en uno de los tramos extremos de la ruta. Cuando nos fijamos este hecho, vamos a iniciar el proceso de contar el paso de los segmentos de tiempo de la ruta.
Habiendo examinado los segmentos y la frecuencia de la obtención de datos, hemos identificado cuatro situaciones:
Situación 1.

Situación 2.

Situación 3.

Situación 4.

Con múltiples puntos del vehículo y la posición de cada punto del tiempo, podemos calcular cuánto tiempo pasó segmento de la totalidad o parte de ella. Dependiendo de la situación, ignoramos algunos puntos de la posición del vehículo, por ejemplo, si más de un segmento.
La definición de llegar a una parada y el cálculo del error de predicción h5> Después de determinar la posición actual del vehículo en la ruta se calcula de la siguiente parada y el hecho de que la llegada del vehículo a una parada.
Hemos implementado dos versiones de la llegada algoritmo.
La primera opción en pocas palabras - el vehículo se detuvo, si está en un segmento inmediatamente antes o inmediatamente después de parar. Y esta opción no estaba funcionando =) El hecho de que varias paradas diferentes a lo largo de la longitud de los segmentos adyacentes, y si el segmento es demasiado corta, los datos de navegación simplemente no se encuentran en ellos.
La segunda opción en pocas palabras - el vehículo se detuvo, si es a una cierta distancia de ella. Con los códigos completos MongoDB y geo, teníamos un montón de espacio para escribir las preguntas adecuadas. El tamaño del polígono en el que la lista se selecciona basándose en la frecuencia de recepción de los datos de navegación, es decir, elegimos el tamaño del relleno sanitario para minimizar su tamaño y por lo tanto aumentar la probabilidad de que será el vehículo.
En ambos casos hemos considerado sólo el vehículo que se encuentran en la ruta, que identifica el segmento.
La llegada del vehículo a una parada se visualiza en el marcador.
Habiendo determinado que el vehículo se detuvo, esperamos que la desviación de la previsión en tiempo real por el índice de MAPE. Más detalles al respecto se pueden encontrar aquí .
Crear previsión h5> Y entonces llegó el día en que lo hemos hecho todas las piezas excepto la última. En realidad, el establecimiento de la previsión.
Un resumen del algoritmo.
En la entrada tenemos una ruta que consta de segmentos. Para cada segmento, sabemos que el tiempo de viaje estadística y la última vez que la corriente que pasa. Estadísticas se selecciona en función de la hora del día, día de la semana y época del año. La última vez que el flujo real de cada segmento se utiliza para minimizar las estadísticas de error.
El primer paso - para determinar la ruta más cercana para el vehículo a una parada, para él, vamos a construir un pronóstico
.
Para ello, se elige un vehículo de la base de datos, que es seguido por una parada para los que hacemos el pronóstico. Esto tiene en cuenta el estado del vehículo como se ha definido anteriormente.
Cada TC tiene una posición en la ruta, a saber, el segmento de la ruta en la que se encuentra.
Cada segmento tiene un número de serie del vehículo mientras se mueve en la ruta. Elija de la lista de la Unión Aduanera, que tiene el número de serie del segmento más grande, que será lo más parecido a un alto.
El segundo paso - para conseguir un conjunto de segmentos entre el vehículo y la parada. Como ya sabemos el vehículo está en el segmento, y cada parada "sabe" qué segmentos contiguos. Por lo tanto, tenemos dos segmentos y seleccionamos la lista entre ellos.
El tercer paso - contar el tiempo
. Resumimos la corriente tiempo estático y del segmento entre el vehículo y detenerlo. El segmento más lejos de la parada, más peso es el momento de estadística y viceversa, por cerca de un segmentos halt más peso en el momento del paso del segmento actual.
La cantidad de veces que este es el pronóstico cuando el vehículo se detenga.
Como resultado - que tenemos una base para un algoritmo basado en datos históricos y reales [2] y en la ejecución de su modificado ligeramente para mejorar la exactitud de predicción y aquí está:

Ahora tenemos nuestra propia pequeña sala de control! Con las mujeres desnudas y el sitio de construcción =).