1560
Differs from the bus on the car GPS-tracks

Photo Artem Svetlov sup>
To construct a plausible picture of a mirror project Maps Mail.Ru handles a large amount of information on a GPS-track of the movement. Often the source of the tracks, little is known, including for security reasons. But to determine the true situation on the roads I've always wanted to know more. At least in order to understand how the speed of the machine corresponds to the speed the rest of the source stream. In this article we will talk about the method of allocation of route vehicles (buses, trolley buses, minibuses and trams) from the raw data stream GPS.
Why is this vazhnoMarshrutnye vehicles often do not move at the speed of the rest of the stream. They, of course, can be indicators of the transport situation, but with some specifics:
- Buses and trolley buses tend to have their own timetable with plenty of stops along the route. This means that on the open road the bus will go obviously slower flow and often stay for a short time. At rush hour, when the buses run every 7-10 minutes, they can send enough information to reduce the flow velocity near the stop.
- Thanks to dedicated lanes, the bus can go faster in traffic flow.
- Drivers of minibuses often go contrary to all the rules.
Initial dannyeZaranee say, that the purpose of the article is not to compare which of satellite navigation systems better. Almost all client devices now cost chips that receives data from all available systems and produce generalized coordinates. To save space, here and in the future will call the track, produced by using a satellite navigation system, GPS-track.
To begin, let's define what a GPS-track. GPS-track - a sequence of the coordinate position of the device over time. Unfortunately, the only thing we know about each track please send the device - it is a unique identification number. Those are the strict requirements of confidentiality.
All tracks have a different nature and come from different vendors. In this article, I will consider the case when the device is rigidly fixed to the vehicle and sends data at regular intervals. This simplification will allow me not to consider the situation where the device was recording the track in the hands of someone, then that someone got on the bus and rode on it a couple of stops.
The purpose of the analysis is the allocation of the total track list of those who most of the time move along the same sequence of streets - the route.
Method resheniyaPervym affair original continuous track should be divided into single trips, which we will compare to each other. As described earlier - on machines physically stands GPS-tracker that every few seconds sends your coordinates. Most often, the tracker works when the car ignition is on, but there are devices that operate around the clock. Therefore separator trips take longer period of time in which the speed was always 0 or device do not send data.
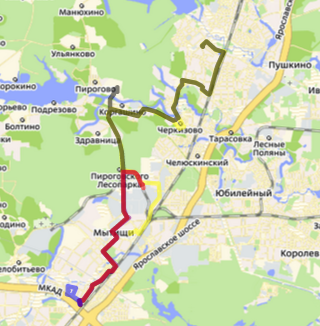
Example of separation of the track on a trip sup>
Now for each vehicle we have a set of tracks, trips that he has committed for a certain period of time. Among them are real travelers and malosvyazannye tracks caused by errors of determining the coordinates, displacements within the closed area of the enterprise, "pereparkovkami" and similar waste. In order not to waste it on computing resources, I filter all the tracks of less than 400 meters, the number of points is less than 10, and the geographical spread of less than 200 meters to the bounding rectangle of the track (bounding box). This will avoid the tracks, sprockets, which are formed due to large random errors in the GPS-receiver.
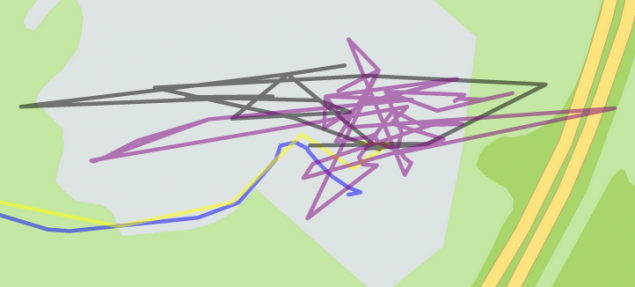
Characteristic track sprockets sup>
The next task - to compare the tracks together and determine whether they are tested by the same route. To do this, first of all I give all GPS-tracks in a single form, tying them to our routing graph. The work privyazchika I wrote in my last post . Since then, it has undergone some changes, but the basic principles remain the same. At the exit of privyazchika I get the track as a chain of pairs (id edges of the graph, the direction (forward or reverse)). At this stage, you can filter tracks that did not fall on our road graph. This may be the tracks of airplanes / helicopters containers in the seas, combine harvesters. Or just from machines that have passed through places where we have, for whatever reasons, no routing graph. I note that there are filtered only those tracks that do not correspond to routing graph. If the car leaves the parking lot, where we do not have routing graph, then long riding on the roads, where attached to the routing graph and the way we stopped at the end of the parking lot (where again there is no routing graph), this track will be counted.
The resulting chain is much easier to compare with each other. I was browsing through various metrics comparison and eventually stopped at метрике Lowenstein . Alphabet in this case is the set of all possible pairs of edge-direction. So I got the opportunity to numerically determine the "similarity" of the tracks as the number of edits ribs route (adding / removing / replacing the ribs) to one route to get another route.
The next step is worth grouping the tracks on the route. This question is answered clustering algorithms of data. Since I already have a one-dimensional metric of "similarity" of the tracks, I took a very simple algorithm for hierarchical clustering of data: дендрограмму. The tree is constructed based on the minimum Levenshtein distance after breaking its branches, which differ by more than n edges. Imperatively happened calculate the optimal n equal to 16.
In the end, I get a set of clusters that contains a similar routes. With this information, it is already possible to draw a conclusion about whether the vehicle travels along a predetermined route. I had the idea to use different n depending on the number of edges in the route, but it does not give improved search quality growth, and I decided to keep a fixed n.
Originally thought that the majority of vehicles have 2 itinerary (from the end to end) in both directions. But, as experience has shown, sometimes the route may be circular, or consist of several parts.
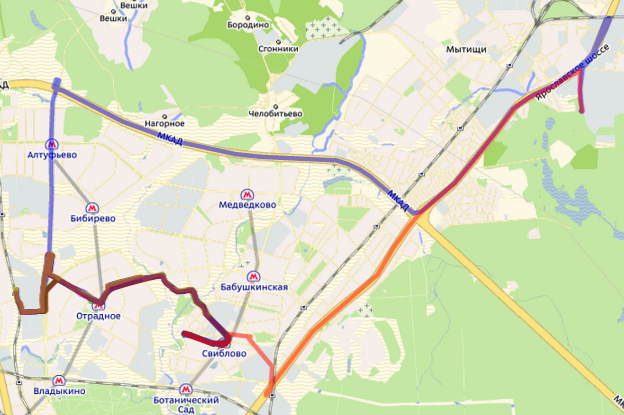
route vehicles do not always move along the route. There are trips to the garage to refuel, etc. Sup>
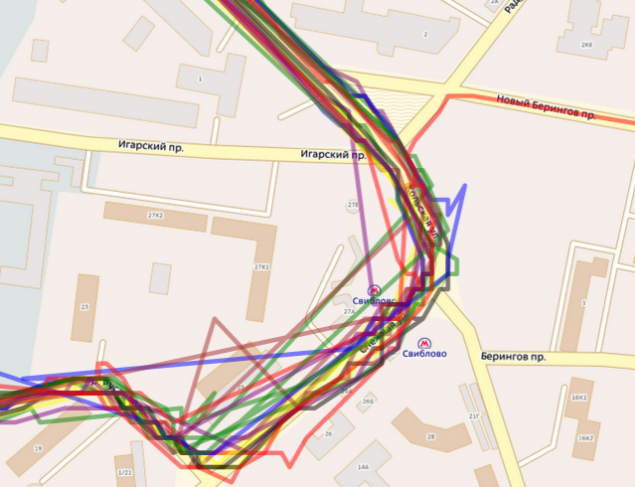
Tracks from the route. Close up view sup>
Thus, most vehicles have at least one cluster in which the piling up trip and some overhead, disposable or more rare routes (to the garage before refueling, etc.). Based on these results, you can check another hypothesis: once we have routes of vehicles and routes metric comparisons, we can allocate vehicles operating on the same route. To do this, just take separate clusters of different vehicles and compare them with each other (especially the comparison function of clusters is already in the implementation of a hierarchical tree).
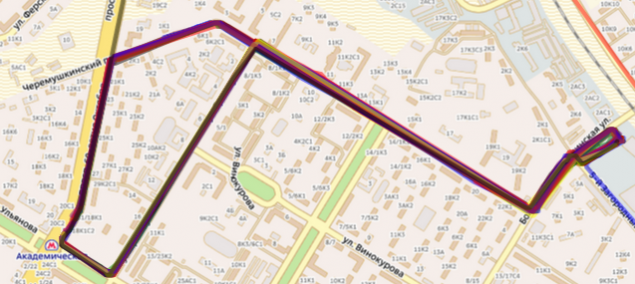
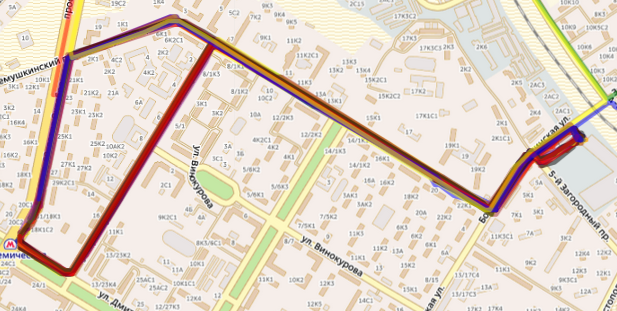
Two different bus traveling the same route sup>
Thus, I can specify the route and group vehicles in the parks.
VyvodyAnonimnye GPS data carry a lot of information. Correctly analyzing these data, we can learn a lot more information about how to produce tracks vehicle and about the city and its roads. Therefore, the scope of the tracks should not be limited in obtaining information about traffic jams, and the information itself can benefit not only motorists, but also municipal and town planning services. Moreover, for the processing of these tracks do not necessarily know the exact data on the machine that creates them. All the necessary information about the vehicle can tell his movements statistics. At the same time, GPS-tracks - is imprecise tool specific information. To get the result you must examine a large amount of data, which places high demands on the manufacturing infrastructure.
Source: habrahabr.ru/company/mailru/blog/228289/






























Wind turbine energy pays off in 5-7 months
Rocket engine is fully printed on the 3d-printer to create a "wave of the hand"