1570
Розшук автобуса з авто GPS треки

Фото Артем Светлов
Щоб побудувати чуйний корк малюнок, пошта. Проект Ru Maps обробляє велику кількість інформації про GPS треки учасників руху. Нерідко мало відомо про джерело треків, в тому числі з причин безпеки. Але визначити справжню ситуацію на дорогах, я завжди хотів дізнатися більше. Принаймні зрозуміти, як швидкість вихідного верстата відповідає швидкості решти потоку. У цій статті ми будемо говорити про метод ізоляції маршрутних транспортних засобів (автобуси, тролейбуси, мікроавтобуси та трамваї) з сирого потоку GPS.
Маршрутні транспортні засоби найчастіше не рухаються на швидкості решти потоку. Звісно, вони можуть бути індикаторами транспортної ситуації, але з певною специфікою:
- Автобуси і тролейбуси зазвичай мають власний розклад з багатьма зупинками на маршруті. Це означає, що на безкоштовному шляху автобус буде чутно повільніше, ніж потік і часто зупиняється на короткий час. Під час щітки час, коли автобуси працюють в інтервалах 7-10 хвилин, вони можуть надсилати достатню кількість інформації про зменшення швидкості потоку в зоні зупинки.
- Завдяки виділеним м'язам автобус може швидше, ніж потік у трафікі.
- Драйвери автобуса часто приводять до будь-яких правил.
Мета даної статті не порівняти які супутникові системи навігації краще. Практично всі пристрої клієнта тепер мають чіпси, які приймають дані з усіх доступних систем і видають узагальнені координати. Для економії простору я продовжую називати трек, отриманий за допомогою супутникової навігаційної системи GPS трек.
Спочатку ми визначаємо, що GPS трек. GPS трек – це послідовність координати положення пристрою в часі. На жаль, ми знаємо про те, що кожен пристрій відправки - це унікальний номер ідентифікації. Це суворі вимоги до конфіденційності.
Всі треки відрізняються різною природою і приходять з різних постачальників. У цій статті я розглянемо випадок, коли пристрій жорстко фіксується до транспортного засобу і відправляє дані за інтервалами. Це спрощення дозволить мені не розглянути ситуацію, де пристрій запису був в руках когось, то ця людина потрапила на автобус і поїхав на пару зупинок.
Мета аналізу буде відрізнити від загального переліку треків, які більшість часу переходять уздовж однакових послідовностей вулиць – маршрутів.
Перш за все, оригінальна безперервна траса повинна бути розділена на одиночні поїздки, які ми порівняємо один з одним. Як описано раніше, є GPS трекер, який надсилає свої координати кожні кілька секунд. Найчастіше тракер працює при запаленні автомобіля, але є пристрої, які працюють цілодобово. Таким чином, туристичний дивідектор займе тривалий період часу, в якому швидкість була завжди 0 або пристрій не надішло даних.
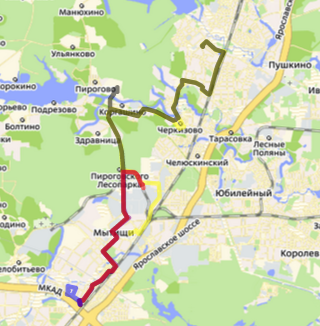
Приклад розщеплення доріжки для подорожі
Тепер для кожного транспортного засобу ми маємо набір трекових поїздок, які він зробив протягом часу. Серед них є як реальні поїздки, так і не пов'язані треки, викликані координацією помилок, рухами всередині закритої зони підприємства, «відновлення» і аналогічним сміттям. Для того, щоб не витрачати обчислювальні ресурси на неї, я відфільтрую всі доріжки менше 400 метрів довга, менше, ніж 10 точок довга, і менше 200 метрів географічно для обмеженої коробки. Це дозволить уникнути зоряних треків, які утворюються через великі випадкові помилки GPS ресивера.
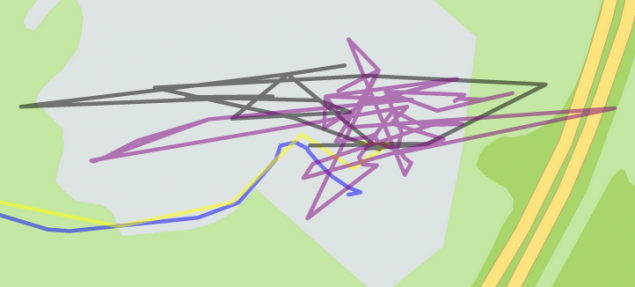 16
16Характеристика треків зірки
Наступне завдання полягає в тому, щоб порівняти ці доріжки один з одним і визначити, чи слідують за тим самим маршрутом. Так, перше, що я збираюся зробити, я збираю всі GPS треки в одну форму і зв'язувати їх на наш графік руху. Я написав про роботу вкладення в мій попередній пост. З тих пір, як і деякі зміни, але основні принципи залишаються однаковими. На виході з обов'язки я отримую трек у вигляді ланцюжка пар (і краю графіка, напрямок (пряма або зворотна)). На цьому етапі можна відфільтрувати доріжки, які не падають на наш графік. Це може бути доріжок з літаків / вертольотів, контейнерів у морях, зернових комбайнах. Або просто від автомобілів, які поїхали на місця, де ми з тієї причини або іншого не маємо дорожнього рахунку. Хочу відзначити, що тут фільтруються лише ті треки, які не відповідають дорожній графіку. Якщо автомобіль залишив автостоянку, де ми не маємо дорожніх рахунках, то поїхав довгий час на дорогах, де було прив'язано до дорожніх рахунках і в кінці шляху поїхав в паркувальний лот (де ще немає дорожніх рахунках), то такий трек буде розраховувати.
В результаті ланцюги набагато простіше порівнювати один з одним. Я дивився на різні метрики порівняння і закінчився метрією Лоевенштейна. Абетка в цьому випадку є набором всіх можливих пар ребер-направлення. Таким чином, я мав можливість чисельно визначити «сімейність» треків як кількість країв маршруту (додатково/ремовне/переміщення ребер) для отримання іншого маршруту з одного маршруту.
Наступним кроком є групування трас вздовж трас. Цей випуск вирішує алгоритми кластеризації даних. З У мене вже є одновимірна траса «сімейність» метрика, я взяв найпростіший алгоритм кластеризації даних ієрархії: дендрограма. Дерево побудоване на основі мінімальної відстані Levenstein, а потім його гілки розбиваються, відрізняються більш ніж n країв. Для розрахунку оптимальної n дорівнює 16.
Отже, що я кінець із набором кластерів, які мають аналогічні маршрути. З цією інформацією вже можна зробити висновок про те, чи приводи автомобіля на заздалегідь визначений маршрут. Я мав ідеї використовувати різні n в залежності від кількості країв в маршруті, але це поліпшення не підвищує якість пошуку, тому я вирішив зберегти фіксовану n.
Спочатку думав, що більшість транспортних засобів мають 2 маршрути (фінал до фіналу) в обох напрямках. Але, як показує практика, іноді маршрут може бути круглим, або складається з декількох частин.
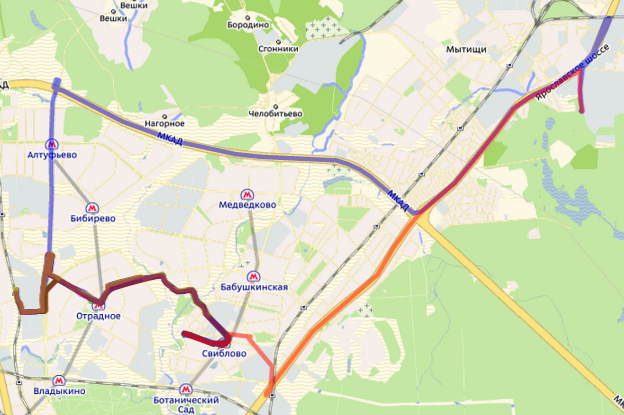
Маршрутні транспортні засоби не завжди рухаються по маршруту. До гаража, станції метро тощо.
3338234
Відстежуйте маршрут. Приват
Таким чином, більшість транспортних засобів мають принаймні один кластер, в якому накопичуються поїздки, і кілька маршрутів обслуговування: одноразові або більш рідкісні маршрути (до гаража, до заправки і так далі). Виходячи з отриманих даних, ми можемо перевірити ще одну гіпотезу: оскільки у нас є транспортні маршрути та маршрути порівняння метрики, ми можемо визначити транспортні засоби, що працюють на одному маршруті. Для цього потрібно лише взяти окремі кластери різних транспортних засобів і порівняти їх один з одним (більше функцій порівняння кластерів вже в реалізації ієрархічного дерева).
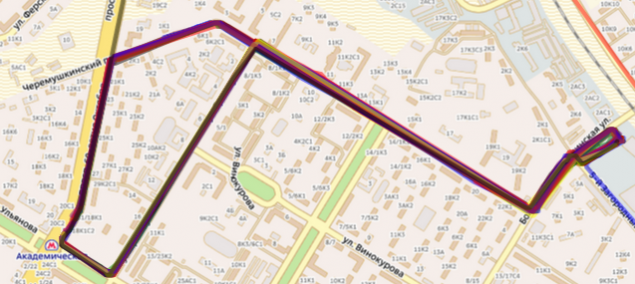
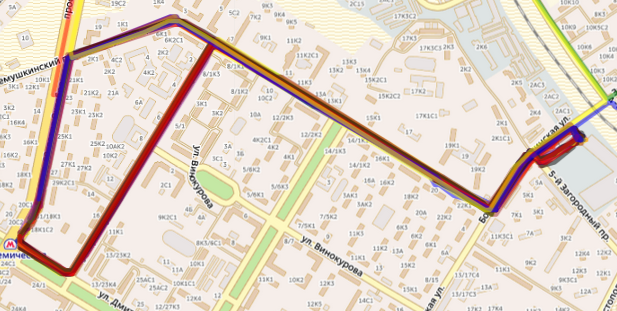
Два різних автобусів на одному маршруті
Таким чином, я можу вказати маршрут і групувати транспортні засоби в парки.
Анонімні GPS дані несе багато інформації. Правильно аналізувати дані, можна дізнатися багато додаткової інформації про транспортний засіб, який створив трек, а також про місто і його дороги. Таким чином, обсяг цих треків не обмежується отриманням інформації про дорожні джеми, а сама інформація може скористатися не тільки автомобілебудування, але й комунальними службами та службами міського розвитку. Для обробки цих доріжок не потрібно знати дані про машину, яка створює їх. Вся необхідна інформація про транспортний засіб може розповісти статистику його руху. У той же час GPS треки є неточний інструмент для визначення інформації. Для отримання результату необхідно вивчити велику кількість даних, які розміщують високі вимоги до інфраструктури обробки.
Джерело: habrahabr.ru/company/mailru/blog/228289/
























Витрата енергії вітрової турбіни за 5-7 місяців
Ракетний двигун повністю надрукований на принтері 3D, створений «закрилком руки»