Жизнь — интересная!
Подписывайтесь на нашу группу в Telegram и Facebook, чтобы быть в сообществе единомышленников, находить вдохновение и не пропускать свежие и удивительные статьи с bashny.net.
9460
2.3
2014-06-21
Манускрипт Войнича. Маньчжурский кандидат
Манускрипт Войнича (МВ или VMS) называют чашей Грааля криптографии. За несколько сотен лет тысячи человеко-дней были потрачены и продолжают тратиться в попытках разгадать его смысл и перевод. Причем пытались люди очень разные, в том числе выдающиеся мировые криптографы. Пока что получается не очень. Две с небольшим сотни пергаментных страниц, неизвестный алфавит, неизвестный язык, каллиграфический уверенный почерк, десятки рисунков неизвестных растений и обнаженных женщин, купающихся в странных каналах, зодиакальные астрологические диаграммы — множество зацепок, но пока ничего, что позволило бы дешифровать рукопись. Для любого, кто хоть чуть-чуть попробовал поразгадывать крючки, МВ представляется идеальной головоломкой — не имеющей пока известной разгадки.

Видел несколько месяцев назад пост на Хабре про ацтекский язык и ботаников, опознавших несколько центрально-американских растений, но всё-таки достану из черновиков свои записи. Их цель — познакомить читателей с миром разгадывателей VMS и моим не очень глубоким анализом одной из относительно недавних гипотез — о маньчжурском языке манускрипта.
Прогуляться по сканам высокого разрешения можно здесь: Voyage the Voynich Manusript
Впервые с МВ я познакомился из давней статьи в бумажной Компьютерре, но немного позаниматься им захотелось сейчас, после интервью Ленты.ру с автором последнего исследования Марчелло Монтемурро, опубликованным на PLoS One. Советую ознакомиться со статьями в Википедии и Компьютерре и интервью на Ленте.
За историю разгадывания рукописи появилась уйма гипотез о её языке — от европейских (одном или их смеси) и ближневосточных до совершенно редких и дальних, типа древнеяванского или индейских, носители которых с Европой 15 века не контактировали; не обошлось и без перевода с древнеукраинского. Одни из последних «прорывов» начала этого года — это расшифровка десятка слов британским лингвистомСтивеном Бэксом и попытки привязать некоторые рисунки и подписи к центрально-американским эндемикам и индейским языкам. Также немало исследователей отчаялись и решили, что текст — подделка или бессмыслица, абракадабра, созданная с целью напустить тумана или поразить покупателей. Но все же тех, кто верит, что МВ — реальный зашифрованный текст — намного больше. Есть причины полагать, что это так:
1. Наличие сложной структуры текста. Как и все реальные языки, МВ подчиняется закону Ципфа, т.е. частота слова обратно пропорциональна его порядковому номеру в отсортированной по частоте последовательности.
2. По энтропийным характеристикам текст близок к европейским языкам — латинскому, английскому
Помнится, в одной из автобиографических книг Ричарда Фейнмана описывается его анализ альбомных листов якобы неизвестных книг c иероглифами Майя. В том рассказе Фейнману довольно быстро удалось расколоть подделку с помощью статистических оценок и логических рассуждений. Дальше он с восторгом фантазирует — как было бы здорово, если кто-то решился бы создать по-настоящему крутую подделку, с учетом всех закономерностей в таких текстах. Если кому-то когда-то такая подделка удалась — то это МВ.
В 2003-2004 некий польский исследователь Збигнев Банасик (Zbigniew Banasik) предложил маньчжурскую версию. Ссылок на него, кроме его письма о Войниче, я не находил, только при написании этой статьи нашел публикацию в польской газете. Google дает перевод, это любитель-лингвист и полиглот из села под Вроцлавом… Он предложил трансляцию алфавита манускрипта в латиницу и дал начальное толкование первой страницы. Первая страница манускрипта 1r — одна из главных целей атак на VMS, считается, что разгадав хотя бы ее часть, можно получить ключи ко всей рукописи.
Есть статья русской Википедии. Вкратце, маньчжуры — народ, живший в северной части современного Китая и немного дальневосточной России, родом с Прибайкалья и Алтая. Более древнее название — чжурчжени. В 17 веке напали и захватили Китай, спалили Шаолинь, основали династию Цин, которая правила до начала 20 века. В этот период официальный документооборот Поднебесной велся на манчьжурском языке, в китайских архивах скопилось коллосальное число документов, до которых у исследователей не дошли руки. Считается, что хороший историк-китаист должен овладеть маньчжурским хотя бы для того, чтобы прочитать важнейшие документы эпохи в подлиннике. С 17 века у маньчжур был оригинальный алфавит, но потом они перешли на китайские иероглифы. Китайцы сильно развили язык завоевателей, добавили в него множество слов, перевели на маньчурский Дао Де Цзин и военный трактат Сунь-Цзы, и в конце 19 века успешно ассимилировали Маньчжурию. Сейчас почти все маньчжуры говорят на китайском за исключением небольшой обособленной народности Сибо. Уже в конце 19 века маньчжурский язык считали вымирающим, сейчас его можно считать почти мертвым.
Исторически в России XIX в. сложилась мощная школа маньчжуроведов, которая, как пишут, сдала в XX в из-за войн и революций. В сети можно найти скан в pdf глубоко проработанный «Полный маньчжурско-русский словарь» И.И. Захарова издания 1875 г. Но в данном случае удобнее пользоваться оцифрованным маньчжурско-английским словарем Дж.Нормана. Здесь можно послушать песенку ARKI UCUN с латинским подстрочником. Как я понял, название переводится вроде «давайте выпьем» или как-то похоже.

В общем, я взял очень много из работы, которую проделал William Porquet. На его страничке есть большой пост A Manchu Skeleton Key to the Voynich Manuscript. С главной страницы там ссылок на него нет, но он гуглится, и также я много интересно нашел в корневой веб-папке, где лежит статья. Кроме этого он оставлял ссылки на статью на разных форумах войничеведов.
Итак, взяв алфавит Банасика и его расширение, которое предложил Porquet, можно перевести текст манускрипта в несколько вариантов текста на латинице с небольшим числом дополнительных букв. Далее двигаясь в предположении, что мы получили некий текст на маньчжурском языке или же на одном из его диалектов — вымершим или смешанным с дополнительными словами из другого языка, мы можем попытаться получить варианты переводов каждого слова и фраз из нескольких слов. Одно из главных предположений состоит в том, что слова были написаны на слух или же человеком, владеющих языком без глубокого знания грамматики и орфографии — если таковая была на момент создания. Это значит, что одно слово может быть записано несколькими похожими вариантами. В пользу этого говорят особенно распространенные окончания ain, aiin, aiiin, daiin, итд. в нотации EVA (European Voynich Alphabet).
Первым делом я создал базу для анализа текста. По ряду причин был выбран Oracle 11g. Oracle упомянут из-за того, что примеры запросов будут приводиться на его версии SQL. Со скриптами вы можете ознакомиться в репозитории Github. Там выложен набор скриптов, создающих схему, таблицы и ряд DML SQL скриптов, наполняющих данными таблицы манускрипта, маньчжурско-английского словаря и некоторых других.
Итак, несложной последовательностью регулярных выражений из текстовых записей манускрипта в EVA и в расширенном алфавите Банасика получаем скрипты, импортирующие VMS построчно, где индекс строки выглядит как
Первые 2 строки VMS в нотации EVA выглядят так (взято с www.voynich.nu/analysis.html):
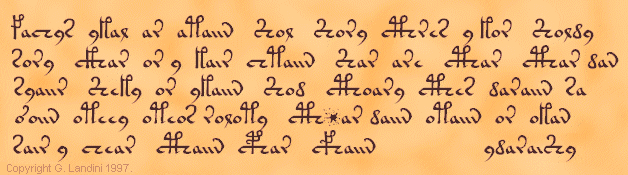
fachys.ykal.ar.ataiin.Shol.Shory.cThres.y,kor.Sholdy
sory.cKhar.or,y.kair.chtaiin.Shar.are.cThar.cThar,dan
Трансляция будет выглядеть так:
Подпись в конце пятой строки первого параграфа ydaraiShy превращается в ibusurti. Мне кажется, что это какое-то имя собственное. В маньчжурском словаре такого слова нет, как я выяснил через простой поиск в facebook, это может означать человек родом из города Сурат ( «солнечный город») на юге Индии — по-русски как суртиец. Правда, не на маньчжурском, а на хинди или гуджарати…
Слова и словосочетания, переведенные таблицей из VMS в латиницу, нужно сопоставить с словами из словаря Нормана. Одна запись в словаре содержит одно слово или словосочетание из нескольких маньчжурских слов заглавными буквами и их английский перевод, который может иметь несколько значений. Например:
CŪŠILE crystal
NIYOHOMBI to have sexual intercourse
В CŪŠILE транслируется первое слово fachys на первой странице 1r, второе неоднократно мелькает в рукописи, включая грамматически верные склонения в маньчжурском. В этом же слове удобно показать добавочные буквы: C звучит как твердое «ч», Š — как «ш», Ū — примерно как «ю».
Для начала, чтобы проиндексировать и сопоставить словарь и рукопись я взял проcто функцию SOUNDEX. Это старейший фонетический алгоритм, создан аж в 1918 году и по-моему использовался еще до компьютеров при переписи населения США. Создав в таблице словаря и в таблице, где хранятся словарные фрагменты рукописи, столбцы с индексом SOUNDEX, можно по нему посмотреть варианты перевода.
К сожалению, SOUNDEX загребает слишком много лишнего. Он берет первые 2-3 слога из слова, переводит из в буквенно-цифровой код, где группы похожих звуков (т.е. букв) переводятся в один символ. Подробнее — в приведенной ссылке в Вики. Но он дает варианты перевода на английский! Это первое приближение, и оно очень важно.
Развитие фонетических алгоритмов привело к созданию Metaphone и потом — Double Metaphone. Это более продвинутый вариант сравнения слов. Вместо буквенно-цифрового кода из слова или фразы вычисляется чисто буквенный код, приведенный к одному регистру. Обычно гласные убираются, парные или похожие согласные сворачиваются в одного представителя. Все разделители и небуквенные символы игнорируются. Metaphone появился на границе 80х-90х, Double Metaphone — в середине 90х, Metaphone 3 — в 2009. Последний является коммерческим софтом, продается вместе с небольшой базой для сравнения имен и фамилий, написанных по-английски. Есть реализации Double Metaphone для разных языков, учитывающих произношения в них латинских букв и буквосочетаний. Есть и для русского. Для маньчжурского нет. Я нашел свободную реализацию Double Metaphone на PL/SQL, и немного расширил ее, добавив вышеописанные буквы и еще парочку подобных. В репозитории она доступна, там буквально несколько строчек изменены. Да, особенности морфологии языка со всякими склонениями, суффиксами и приставками он не поймает, но даже то, что получилось — очень интересно.
Соединение таблицы с пословной нарезкой манускрипта и маньчжурского словаря по полю кода METAPHONE (MPH_CODE) через LEFT JOIN.
Ниже в таблице показаны варианты перевода первой строки первой страницы <1r.1>. Большинство слов имеет несколько вариантов, но для слова 5 ( uhungg ) и 8 ( jolkl ) их нет ни одного.
N — номер слова в строке <1r.1>
NWORD — слово в предложенный алфавит
MPH_CODE — метафоновский код слова NWORD
WORD — вариант маньчжурского слова из словаря Нормана, у которого метафоновский код равен коду от NWORD
TRANSLATION — перевод маньчжурского слова
Как видите, некоторые слова похожи по виду, некоторые отстоят далековато, из-за почти полного вырезания гласных в коде от слова выдаются все варианты маньчжурских слов, у которых между согласными совсем другие гласные звуки. Коротки одно- и двух-буквенные слова — вообще «пальцем в небо». Но уже интересно — намного интереснее, чем искать по словарю вручную с Ctrl-F.
Всего использовалось три модификации метафона — исходная английская и еще две модифицированные, со дополнительными буквами и с изменениями правил свертки.
Небольшая коррекция словаря — к полю перевода, содержащее пересылки «see SOME_OTHER_WORD» через разделитель добавляется перевод этого синонима.
Пересылки на синонимы ловятся регулярным выражением.
Например приведенный выше в таблице:
TOSE see toose
сразу дополняется переводом ссылки:
TOSE see toose :: 1. weight (for a balance) 2. power, authority, right 3. spindle
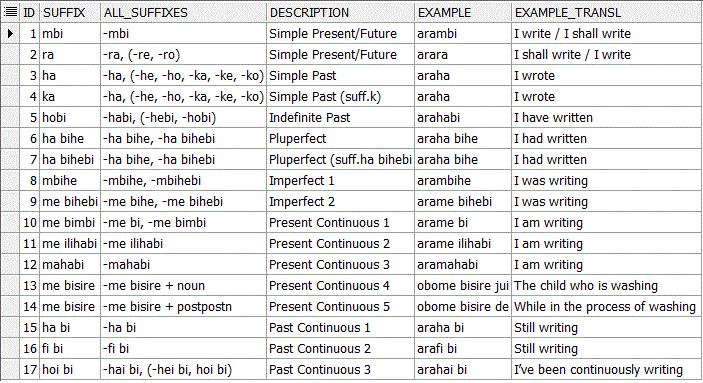
Идем дальше. Можно погрузиться в язык глубже. Глаголы в маньчжурском склоняются по временам добавлением окончания. Вот здесь приведена таблица склонений с примерами и соответствиями английским временам. Можно заметить, что на один английский Present Continious или Past Continious есть несколько разных маньчжурских вариантов. Видимо они отражают какие-то непонятные мне тонкости или это просто синонимы, но для поиска соответствий в Войниче это не важно. Из таблицы словаря делаем и сохраняем выборку глаголов в форме инфинитива — то есть все слова заканчивающиеся на инфинитивное окончание -MBI и имеющие в поле перевода подстроку " to ". Убрав окончание и сохранив результат в отдельную таблицу, получаем список глагольных маньчжурских корней MANCHU_VERB_STEM.
Например, глагол AKŪMBI (to die) сохраняется как: AKŪ.
Из указанной выше ссылки берем таблицу склонений и делаем справочную таблицу MANCHU_VERB_SUFFIX:
Все возможные варианты склонений глаголов — это фактически декартово произведение этих таблиц. Причем поиск в манускрипте проводится точно так же, по коду Metaphone, а при склонении к коду корня глагола добавляется метафоновский код окончания-суффикса. Из-за этого можно пренебречь разными вариантами окончаний для большинства времен.
Например из склонений Simple Past в словаре к разным глаголам добавляются разные окончания, но для поиска по по нарезанному манускрипту к метафоновскому коду добавится только H или K.
Past -ha (-he, -ho, -ka, -ke, -ko), Example: araha (I wrote)
Вот так выглядит часть кода представления TRANSL_VERBS21, выдающее варианты перевода сразу одно- и двух-словных сочетаний с учетом морфологии глаголов: варианты склонений выдаются через внутренний подзапрос с UNION ALL:
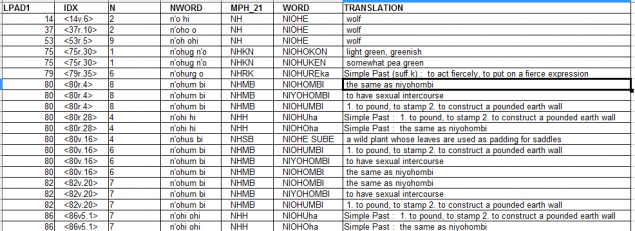
Пример. В маньчжурской грамматике есть еще множество вариантов изменения глаголов с помощью суффиксов, но совсем глубоко закапываться — заняло слишком много сил, так что давайте просто посмотрим, как выявляются морфологии глагола NIYOHOMBI:
Списки Сводеша (Swadesh lists) — базисная лексика, наборы основных слов, по которым лингвисты оценивают родство двух или нескольких языков между собой. Например, вот здесь таблица сравнения славянских языков по списку Сводеша. Также по таблицам оценивают скорость изменения языка во времени. Базовые слова из таких списков замещаются или меняются намного реже, чем другие, но время от времени и они тоже. Например, в русском языке слово «глаз» — наносное, почти жаргонное, пришло на смену общеславянскому слову «око» в каком-то там 13 или 14 веке. Первоначально означало камешек с дыркой внутри. Очи остались в поэзии, пословицах и церковных текстах. Списки Сводеша есть на 100, 200 и 215 слов. Пишут, что лингвисты больше всего используют самый короткий список на 100 слов. Если интересно, вот биография Морриса Сводеша на русском.
Просто для интереса я записал большой английско-маньчжурский список на 207 слов в отдельную таблицу и пересек со всеми переводами всех наборов из 1 и 2 слов из манускрипта, отсортировав по частоте. Получилась вот такая таблица — это самые верхние, 33 самых частых слов. Тут тоже не все чисто, потому что многие маньчжурские слова в нем приведены в 2 или 3 вариантах в одном поле и значит в, но для первичной оценки — сойдет.
Похожих слов не так много, но кое что есть: seed, right, sun, you, to give и несколько других:
Топ 30 таблицы
Следующий запрос показывает распределение по частоте таких слов и пар слов с убранными пробелами, которые строго совпадают со словами из словаря. Из всего множества выбраны слова, имеющие характерные для маньчжурского буквосочетания — типа ng , os, mb и так далее. Буквосочетния были выявлены из текста VMS онлайновым анализатором TAPoR с сайта канадского университета Макмастера. Сейчас там есть целая коллекция анализаторов и визуализаторов зависимостей в текстах, но именно этот, что на скриншоте, к сожалению уже недоступен. Есть версия, где нужно копи-пастить текст в форму на страничке, но ссылку на текст передать в параметрах уже нельзя.
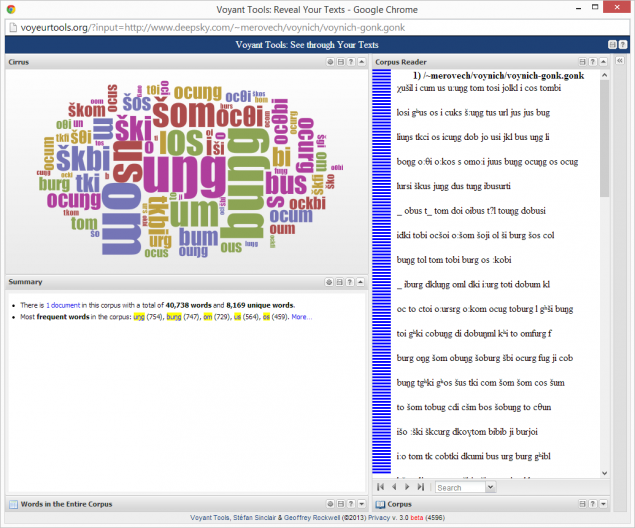
Для сравнения — визуализация то же программой собранного мной крошечного маньчжурского корпуса на 14 кб. Это почти все, что удалось накопать — несколько коротких сказок, несколько страниц перевода Дао Де Цзин и несколько материалов для чтения.
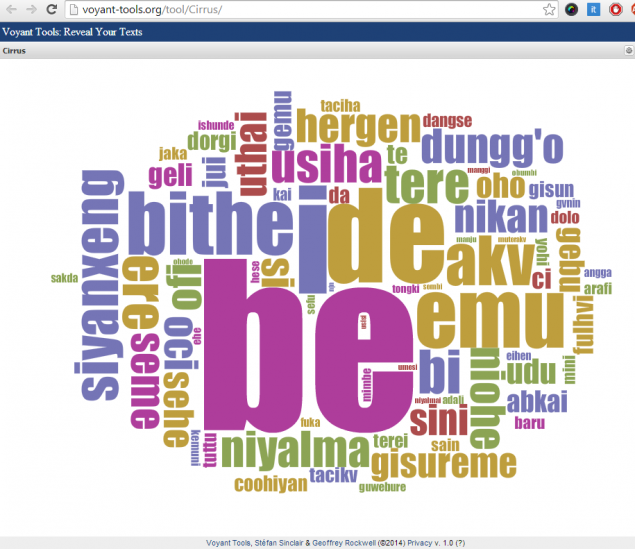
Заметно, что визуализатор выделяет уже целые длинные слова, такие как niyalma (человек) или bithe( книга). Таких слов в манускрипте нет, но зато есть множество редких обрывков или целых слов, вполне согласующихся с грамматикой языка, многие даже со склонениями.
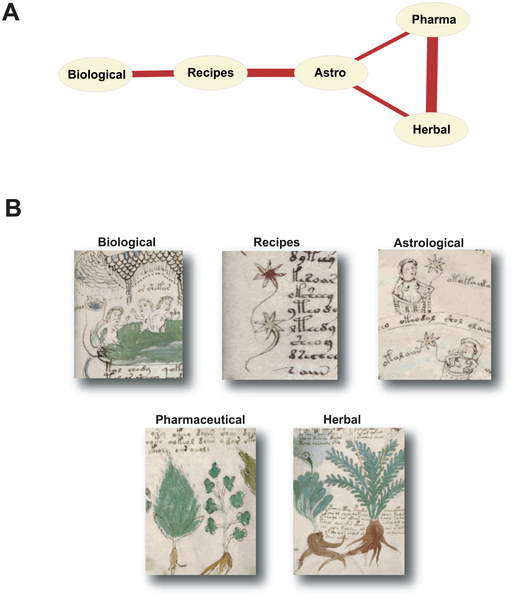
В статье Монтемурро проанализированы энтропийные близости слов рукописи и на построена диаграмма нескольких кластеров слов, связанных между собой большой близостью ( Рис.2 ). Этот же рисунок графов с наложенными «переводами» выглядит так.
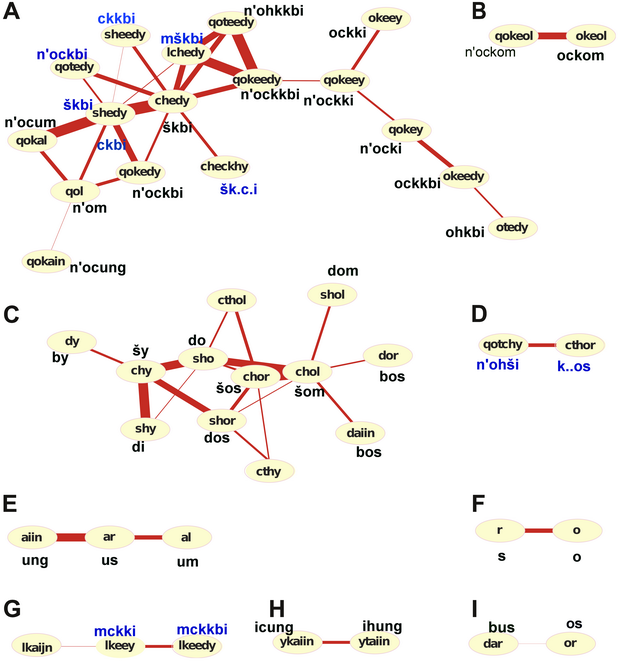
Здесь я пропустил несколько слов и надо было с самого начала делать синий цвет у всех надписей…
Приведенный ниже запрос считает статистику по частоте слов с включениями характерных частей, выделенных онлайновым анализатором из первого скриншота. Еще ниже показаны результаты.
Всего в таблице 38 слов, но показаны 17 с частотой более 1, остальные под спойлером.
Остальные слова с ng, os, mb и т.д.
Напоследок — таблица точных соответствий слов из манускрипта и словаря, длиной не менее 3 букв, отсортированных по убыванию длины и только потом по частоте.
Опять, топ показан, остальное — под спойлером. Тексты запросов приводятся лишь потому, что по моему мнению наиболее компактно выражают, что в таблице.
Остальные 83 слова
Статистика по некоторым словам, отобранных по словарю. Прежде всего интересно искать в травнике. Из списка убрал слово «женщина», чтобы сократить вывод.
Вот, что получается. Здесь уже не только полностью совпадающие слова, но все совпадения по метафону — поэтому некоторые непохожи. Но магии ( FANGGA) в тексте достаточно…
Остальное. Примерно сотня строк, некоторые интересны. Например OKTO — 1. drug, medicine 2. gunpowder 3. dye 4. poison
Топ-15 таких слов. Некоторые из них находят толкование, если их рассматривать в паре с соседним словом — предыдущим или последующим.
Многие из них по структуре могли бы быть каким-нибудь маньчжурским словом — имеют характерные суффиксы и окончания -ng-, -ungg-, -mbi-, -bumbi- и так далее.
Одиночных слов без соответствия по самому широкому охвату (TRANSL_VERB21, со склонениями глаголов ) — 18 К из всего 40К. Однако рассмотрение пар соседних слов дает еще 30К уникальных пар, имеющих по крайней мере один метафоновский перевод. И многие слова, не имеющие вариантов перевода в паре с соседними создают сочетания, для которых перевод находится.
Например, skbi даже в парах не дает пеереводов, но следующее такое слово tkbi в одном из 325 мест образует с соседом tkbi ombi — есть 4 варианта перевода. Слово bum составляет многочисленные пары bum bi — и так далее. Наборы из трех и более соседних слов я не генерил и не проверял, но может быть 3-словные блоки стоило бы посмотреть.
Количество совпадений слов и грамматических изменений текста позволяют сделать осторожный вывод, что в манускрипте Войнича по крайней мере используются слова из диалекта маньчжурского/чжурчжэньского языка. Последовательности слов плохо укладываются в языковые конструкции типа словосочетаний и предложений. Но их не находили и раньше, статистический анализ не выявлял их с самых первых попыток. Похоже, что во многих местах идет индексная запись — то есть короткие заметки с сокращениями, которые автору были понятны, но при этом они не складываются в связный текст. Многие слова разбиты на части, возможно автор текста записывал его с устной речи другого человека.
Я не могу определить, насколько достоверно найденные слова и их частоты говорят о том, что в рукописи есть маньжурские вставки. В тексте около 170К букв и 40К слов. Точных совпадений слов по словарю — несколько сотен, но я не беру в расчет совсем короткие слова на 1-2 знака. Кроме этого есть тысячи приблизительных совпадений, по коду метафона. Беглый просмотр по страницам вроде показывает, что слово есть в словаре, но с первого взгляда в предложения они не складываются.
Здорово было бы показать это все ученому-компаративисту, специалисту по дальневосточным языкам. Я лично с такими не знаком, но в России они должны быть. Статьи о таких личностях как Сергей Старостин и записанные интервью с ними подсказывают, что в РГГУ или МГУ надо искать. Могут, конечно, сказать, что это все ерунда. И вообще, неизвестно, как часто к ним приходят с идеями и вопросами по Войничу, может уже и надоело…
В процессе всего этого я наткнулся на любопытный онлайн-курс Corpus Linguistics от Lancaster University на платформе FutureLearn. Я даже записался на него, но, что называется, не пошло. Сама платформа и подача материала не такая удобная, как на Coursera, да и времени перестало хватать после первой недели. Может быть, стоит взяться за него основательнее в следующий заход. Из него пока могу посоветовать энтузиастам программу AntConc — она предназначена для анализа конкордансов текстов, используя загруженные корпусы их выборки из них. Также переделанная из английской в маньчжурскую версия функции Metaphone очень несовершенна — нуждается в улучшении.
При обсуждении знакомый веб-программист предложил простой способ распознать всю рукопись: порезать картинки страниц на отдельные слова и пары слов вставлять их в капчу при логине на сайты…
Интервью с Марчелло Монтемурро на Lenta.ru
Marcelo A. Montemurro, Damian H. Zanette, PLoS ONE, 2013
Критика его статьи на странице войничеведа
Статья в Компьютерре 2005 года о манускрипте
Обзор-презентация истории VMS, попыток дешифровки и статистический анализ
Удобный просмотр МВ. Voyage the Voynich Manuscript
Full trangokulation with initial VMS text
A visual map of Voynich evidence theories
Hoaxing the Voynich manuscript — part 3
Hoaxing the Voynich manuscript — part 4
Подробный анализ зодиакальной части
Voynich alphabets, scripts — on Omniglot
Ответ Столфи о маньчжурской теории — обсуждение аспектов
Zbigniew Banasik's Manchu theory
Первые переводы Збигнева Банасика
Работа польского профессора, анализ языков Земли и манускрипта
Отзыв на reddit
Wikibooks 2
Wikibooks 3
Wikibooks 4
Google booksManchu: A Textbook for Reading Documents: Чжурчженьский( manchu ) язык
Чжурчженьский на Омниглоте
Jurchen script on Wiki
Монгольские и тюркские заимствования в образцах малого чжурчжэньcкого письма
… Чжурчжэньское письмо. Википедия
О Старостине на Альтаике
Сергей Старостин. Два подхода к изучению истории языка
На каком языке говорили Адам и Ева
Retouching
Большой текст воспоминаний о И.И.Захарове и русско-китайских отношениях в 19 в
Маньчжурские manchzhurskie письменные памятники как источник по истории и культуре империи Цинь 17-18 вв
voynich.net
Еще из Компьютерры 2005 года — про отчаянных расшифровщиков непрочтенных древних текстов
Визуализатор manchu VMS в виде пузырьков — из коллекции TAPoR:
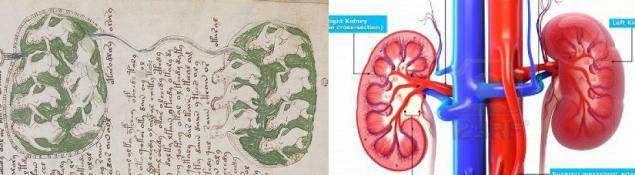
Как некоторые исследователи VMS аргументируют гипотезу о том, что женщины в бассейнах — это изображение внутренних органов человека.
1. Почки
2. Мозг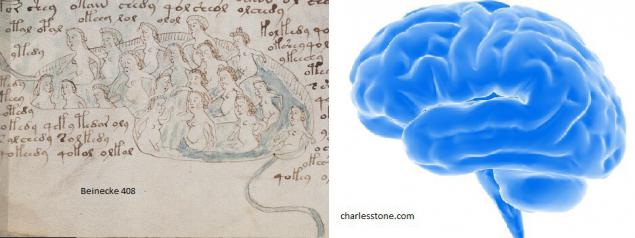
3. Сердце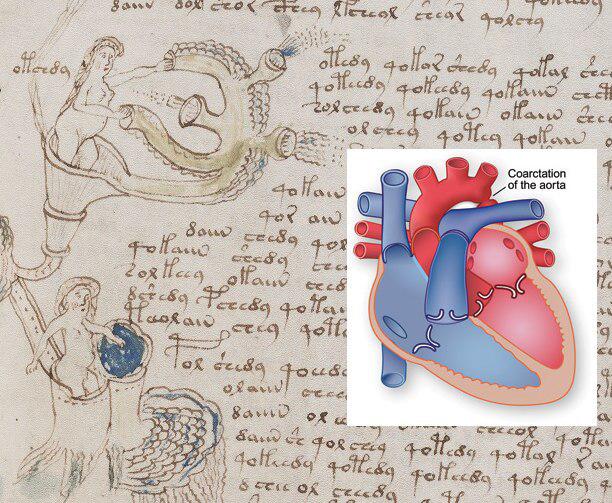
4. Легкие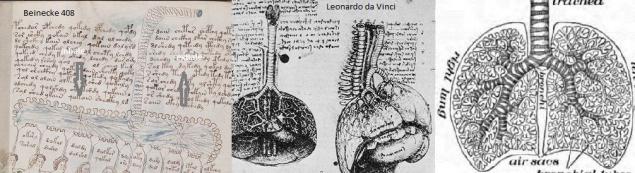
5. Глазные яблоки
Источник: habrahabr.ru/post/186952/

Страница 16v
Видел несколько месяцев назад пост на Хабре про ацтекский язык и ботаников, опознавших несколько центрально-американских растений, но всё-таки достану из черновиков свои записи. Их цель — познакомить читателей с миром разгадывателей VMS и моим не очень глубоким анализом одной из относительно недавних гипотез — о маньчжурском языке манускрипта.
Прогуляться по сканам высокого разрешения можно здесь: Voyage the Voynich Manusript
Впервые с МВ я познакомился из давней статьи в бумажной Компьютерре, но немного позаниматься им захотелось сейчас, после интервью Ленты.ру с автором последнего исследования Марчелло Монтемурро, опубликованным на PLoS One. Советую ознакомиться со статьями в Википедии и Компьютерре и интервью на Ленте.

Граф статистической связанности между частями манускрипта — рисунок из статьи Монтемурро
За историю разгадывания рукописи появилась уйма гипотез о её языке — от европейских (одном или их смеси) и ближневосточных до совершенно редких и дальних, типа древнеяванского или индейских, носители которых с Европой 15 века не контактировали; не обошлось и без перевода с древнеукраинского. Одни из последних «прорывов» начала этого года — это расшифровка десятка слов британским лингвистомСтивеном Бэксом и попытки привязать некоторые рисунки и подписи к центрально-американским эндемикам и индейским языкам. Также немало исследователей отчаялись и решили, что текст — подделка или бессмыслица, абракадабра, созданная с целью напустить тумана или поразить покупателей. Но все же тех, кто верит, что МВ — реальный зашифрованный текст — намного больше. Есть причины полагать, что это так:
1. Наличие сложной структуры текста. Как и все реальные языки, МВ подчиняется закону Ципфа, т.е. частота слова обратно пропорциональна его порядковому номеру в отсортированной по частоте последовательности.
2. По энтропийным характеристикам текст близок к европейским языкам — латинскому, английскому
Помнится, в одной из автобиографических книг Ричарда Фейнмана описывается его анализ альбомных листов якобы неизвестных книг c иероглифами Майя. В том рассказе Фейнману довольно быстро удалось расколоть подделку с помощью статистических оценок и логических рассуждений. Дальше он с восторгом фантазирует — как было бы здорово, если кто-то решился бы создать по-настоящему крутую подделку, с учетом всех закономерностей в таких текстах. Если кому-то когда-то такая подделка удалась — то это МВ.
В 2003-2004 некий польский исследователь Збигнев Банасик (Zbigniew Banasik) предложил маньчжурскую версию. Ссылок на него, кроме его письма о Войниче, я не находил, только при написании этой статьи нашел публикацию в польской газете. Google дает перевод, это любитель-лингвист и полиглот из села под Вроцлавом… Он предложил трансляцию алфавита манускрипта в латиницу и дал начальное толкование первой страницы. Первая страница манускрипта 1r — одна из главных целей атак на VMS, считается, что разгадав хотя бы ее часть, можно получить ключи ко всей рукописи.
Короткая справка о маньчжурском языке.
Есть статья русской Википедии. Вкратце, маньчжуры — народ, живший в северной части современного Китая и немного дальневосточной России, родом с Прибайкалья и Алтая. Более древнее название — чжурчжени. В 17 веке напали и захватили Китай, спалили Шаолинь, основали династию Цин, которая правила до начала 20 века. В этот период официальный документооборот Поднебесной велся на манчьжурском языке, в китайских архивах скопилось коллосальное число документов, до которых у исследователей не дошли руки. Считается, что хороший историк-китаист должен овладеть маньчжурским хотя бы для того, чтобы прочитать важнейшие документы эпохи в подлиннике. С 17 века у маньчжур был оригинальный алфавит, но потом они перешли на китайские иероглифы. Китайцы сильно развили язык завоевателей, добавили в него множество слов, перевели на маньчурский Дао Де Цзин и военный трактат Сунь-Цзы, и в конце 19 века успешно ассимилировали Маньчжурию. Сейчас почти все маньчжуры говорят на китайском за исключением небольшой обособленной народности Сибо. Уже в конце 19 века маньчжурский язык считали вымирающим, сейчас его можно считать почти мертвым.
Исторически в России XIX в. сложилась мощная школа маньчжуроведов, которая, как пишут, сдала в XX в из-за войн и революций. В сети можно найти скан в pdf глубоко проработанный «Полный маньчжурско-русский словарь» И.И. Захарова издания 1875 г. Но в данном случае удобнее пользоваться оцифрованным маньчжурско-английским словарем Дж.Нормана. Здесь можно послушать песенку ARKI UCUN с латинским подстрочником. Как я понял, название переводится вроде «давайте выпьем» или как-то похоже.

Маньчжурский офицер династии Цин, поздние 1700е, картинка из Википедии
Описание методики
Алфавит и трансляция
В общем, я взял очень много из работы, которую проделал William Porquet. На его страничке есть большой пост A Manchu Skeleton Key to the Voynich Manuscript. С главной страницы там ссылок на него нет, но он гуглится, и также я много интересно нашел в корневой веб-папке, где лежит статья. Кроме этого он оставлял ссылки на статью на разных форумах войничеведов.
Итак, взяв алфавит Банасика и его расширение, которое предложил Porquet, можно перевести текст манускрипта в несколько вариантов текста на латинице с небольшим числом дополнительных букв. Далее двигаясь в предположении, что мы получили некий текст на маньчжурском языке или же на одном из его диалектов — вымершим или смешанным с дополнительными словами из другого языка, мы можем попытаться получить варианты переводов каждого слова и фраз из нескольких слов. Одно из главных предположений состоит в том, что слова были написаны на слух или же человеком, владеющих языком без глубокого знания грамматики и орфографии — если таковая была на момент создания. Это значит, что одно слово может быть записано несколькими похожими вариантами. В пользу этого говорят особенно распространенные окончания ain, aiin, aiiin, daiin, итд. в нотации EVA (European Voynich Alphabet).
Первым делом я создал базу для анализа текста. По ряду причин был выбран Oracle 11g. Oracle упомянут из-за того, что примеры запросов будут приводиться на его версии SQL. Со скриптами вы можете ознакомиться в репозитории Github. Там выложен набор скриптов, создающих схему, таблицы и ряд DML SQL скриптов, наполняющих данными таблицы манускрипта, маньчжурско-английского словаря и некоторых других.
Итак, несложной последовательностью регулярных выражений из текстовых записей манускрипта в EVA и в расширенном алфавите Банасика получаем скрипты, импортирующие VMS построчно, где индекс строки выглядит как
<page_numberSIDE_LETTER.row_number>. Например, вторая строка первой страницы рукописи имеет индекс
<b><1r.2></b>:
Первые 2 строки VMS в нотации EVA выглядят так (взято с www.voynich.nu/analysis.html):
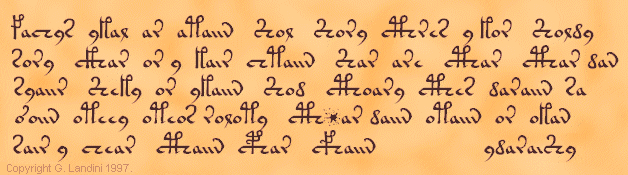
fachys.ykal.ar.ataiin.Shol.Shory.cThres.y,kor.Sholdy
sory.cKhar.or,y.kair.chtaiin.Shar.are.cThar.cThar,dan
Трансляция будет выглядеть так:
'<1r.1> ', 'fachys.ykal.ar.ataiin.Shol.Shory.cThres.y,kor.Sholdy''<1r.1> ', 'cušil i cum us uhungg tom tosi jolkl i cos tombi''<1r.2> ', 'sory.cKhar.or,y.kair.chtaiin.Shar.are.cThar.cThar,dan''<1r.2> ', 'losi gus os i cuks šhungg tus url jus jus bug'Подпись в конце пятой строки первого параграфа ydaraiShy превращается в ibusurti. Мне кажется, что это какое-то имя собственное. В маньчжурском словаре такого слова нет, как я выяснил через простой поиск в facebook, это может означать человек родом из города Сурат ( «солнечный город») на юге Индии — по-русски как суртиец. Правда, не на маньчжурском, а на хинди или гуджарати…
Сравнение функции подобия
Слова и словосочетания, переведенные таблицей из VMS в латиницу, нужно сопоставить с словами из словаря Нормана. Одна запись в словаре содержит одно слово или словосочетание из нескольких маньчжурских слов заглавными буквами и их английский перевод, который может иметь несколько значений. Например:
CŪŠILE crystal
NIYOHOMBI to have sexual intercourse
В CŪŠILE транслируется первое слово fachys на первой странице 1r, второе неоднократно мелькает в рукописи, включая грамматически верные склонения в маньчжурском. В этом же слове удобно показать добавочные буквы: C звучит как твердое «ч», Š — как «ш», Ū — примерно как «ю».
SOUNDEX
Для начала, чтобы проиндексировать и сопоставить словарь и рукопись я взял проcто функцию SOUNDEX. Это старейший фонетический алгоритм, создан аж в 1918 году и по-моему использовался еще до компьютеров при переписи населения США. Создав в таблице словаря и в таблице, где хранятся словарные фрагменты рукописи, столбцы с индексом SOUNDEX, можно по нему посмотреть варианты перевода.
К сожалению, SOUNDEX загребает слишком много лишнего. Он берет первые 2-3 слога из слова, переводит из в буквенно-цифровой код, где группы похожих звуков (т.е. букв) переводятся в один символ. Подробнее — в приведенной ссылке в Вики. Но он дает варианты перевода на английский! Это первое приближение, и оно очень важно.
METAPHONE
Развитие фонетических алгоритмов привело к созданию Metaphone и потом — Double Metaphone. Это более продвинутый вариант сравнения слов. Вместо буквенно-цифрового кода из слова или фразы вычисляется чисто буквенный код, приведенный к одному регистру. Обычно гласные убираются, парные или похожие согласные сворачиваются в одного представителя. Все разделители и небуквенные символы игнорируются. Metaphone появился на границе 80х-90х, Double Metaphone — в середине 90х, Metaphone 3 — в 2009. Последний является коммерческим софтом, продается вместе с небольшой базой для сравнения имен и фамилий, написанных по-английски. Есть реализации Double Metaphone для разных языков, учитывающих произношения в них латинских букв и буквосочетаний. Есть и для русского. Для маньчжурского нет. Я нашел свободную реализацию Double Metaphone на PL/SQL, и немного расширил ее, добавив вышеописанные буквы и еще парочку подобных. В репозитории она доступна, там буквально несколько строчек изменены. Да, особенности морфологии языка со всякими склонениями, суффиксами и приставками он не поймает, но даже то, что получилось — очень интересно.
Соединение таблицы с пословной нарезкой манускрипта и маньчжурского словаря по полю кода METAPHONE (MPH_CODE) через LEFT JOIN.
Ниже в таблице показаны варианты перевода первой строки первой страницы <1r.1>. Большинство слов имеет несколько вариантов, но для слова 5 ( uhungg ) и 8 ( jolkl ) их нет ни одного.
'<1r.1> ', 'fachys.ykal.ar.ataiin.Shol.Shory.cThres.y,kor.Sholdy''<1r.1> ', 'cušil i cum us uhungg tom tosi jolkl i cos tombi'N — номер слова в строке <1r.1>
NWORD — слово в предложенный алфавит
MPH_CODE — метафоновский код слова NWORD
WORD — вариант маньчжурского слова из словаря Нормана, у которого метафоновский код равен коду от NWORD
TRANSLATION — перевод маньчжурского слова
| N | NWORD | MPH_CODE | WORD | TRANSLATION |
|---|---|---|---|---|
| 1 | cusil | CSL | CUSILE | crystal |
| 2 | i | I | I | 1. he, she 2. the genitive particle 3. an interjection used to get the attention of subordinates |
| 2 | i | I | IO | oil, paint, lacquer |
| 2 | i | I | II | see i i |
| 2 | i | I | IOI | 1. a musical instrument made in the shape of a lying tiger--the toothed ridge down the back is stroked with a wooden stick at the conclusion of a musical selection 2. one of the five tones; cf. yumk'a |
| 2 | i | I | I I | 1. (onom.) the sound of sobbing 2. an interjection of derision |
| 3 | cum | CM | CIME | a salt-water fish resembling the salmon |
| 3 | cum | CM | COMO | see coman |
| 4 | us | US | USE | seed, egg (of an insect) |
| 4 | us | US | UCE | door |
| 4 | us | US | USA | exclamation used to get someone's attention |
| 5 | uhungg | |||
| 6 | tom | TM | TOOME | see tome |
| 6 | tom | TM | TOMOO | frame used for weaving nets |
| 6 | tom | TM | TIMU | topic, theme |
| 6 | tom | TM | TOME | (postposition) every, each |
| 6 | tom | TM | TAMA | sole (fish) |
| 7 | tosi | TS | TEISU | 1. assigned place, designated place, responsibility, one's part 2. corresponding, matching, facing, opposite |
| 7 | tosi | TS | TESU | original, local |
| 7 | tosi | TS | TOOSE | 1. weight (for a balance) 2. power, authority, right 3. spindle |
| 7 | tosi | TS | TOSE | see toose |
| 7 | tosi | TS | TESE | plural of tere: those, they |
| 7 | tosi | TS | TES | (onom.) the sound of rope, thread, or a leather thong breaking under stress |
| 7 | tosi | TS | TOSI | white spot on the forehead of an animal |
| 7 | tosi | TS | TSU | vinegar |
| 7 | tosi | TS | TUSA | profit, gain, benefit, advantage |
| 7 | tosi | TS | TUSY | chieftain of a native tribe |
| 8 | jolkl | |||
| 9 | i | I | II | see i i |
| 9 | i | I | IOI | 1. a musical instrument made in the shape of a lying tiger--the toothed ridge down the back is stroked with a wooden stick at the conclusion of a musical selection 2. one of the five tones; cf. yumk'a |
| 9 | i | I | I I | 1. (onom.) the sound of sobbing 2. an interjection of derision |
| 9 | i | I | IO | oil, paint, lacquer |
| 9 | i | I | I | 1. he, she 2. the genitive particle 3. an interjection used to get the attention of subordinates |
| 10 | cos | CS | CECE | silk gauze |
| 10 | cos | CS | CASI | in that direction, thither, there |
| 10 | cos | CS | CESE | register, official record |
| 10 | cos | CS | CISE | vegetable or flower garden |
| 10 | cos | CS | CAISI | see caste |
| 10 | cos | CS | CISU | private, private interest or profit |
| 10 | cos | CS | CISUI | out of one's own interest, on one's initiative, naturally (see also ini cisui), privately, on one's own |
| 10 | cos | CS | COS | the sound of ricocheting or rebounding |
| 10 | cos | CS | CUSE | 1. bamboo 2. silk 3. a cook |
| 10 | cos | CS | CAISE | 1. hairpin 2. a cake made of fried vermicelli |
| 11 | tombi | TMB | TUMBI | to hunt, to pursue |
| 11 | tombi | TMB | TOOMBI | to scold, to rail at, to abuse, to curse |
| 11 | tombi | TMB | TEMBI | 1. to sit 2. to reside, to live 3. to occupy (a post) |
| 11 | tombi | TMB | TAMBI | 1. to get caught on something, to get entangled and trip over something 2. to get caught in a trap or net |
| 11 | tombi | TMB | TUMBI | to hit, to beat, to pound; cf. dumbi |
| 11 | tombi | TMB | TOMBI | see toombi |
Как видите, некоторые слова похожи по виду, некоторые отстоят далековато, из-за почти полного вырезания гласных в коде от слова выдаются все варианты маньчжурских слов, у которых между согласными совсем другие гласные звуки. Коротки одно- и двух-буквенные слова — вообще «пальцем в небо». Но уже интересно — намного интереснее, чем искать по словарю вручную с Ctrl-F.
Всего использовалось три модификации метафона — исходная английская и еще две модифицированные, со дополнительными буквами и с изменениями правил свертки.
Пересылки на синонимы в поле перевода
Небольшая коррекция словаря — к полю перевода, содержащее пересылки «see SOME_OTHER_WORD» через разделитель добавляется перевод этого синонима.
Пересылки на синонимы ловятся регулярным выражением.
Например приведенный выше в таблице:
TOSE see toose
сразу дополняется переводом ссылки:
TOSE see toose :: 1. weight (for a balance) 2. power, authority, right 3. spindle
Морфология. Склонения глаголов по временам
Идем дальше. Можно погрузиться в язык глубже. Глаголы в маньчжурском склоняются по временам добавлением окончания. Вот здесь приведена таблица склонений с примерами и соответствиями английским временам. Можно заметить, что на один английский Present Continious или Past Continious есть несколько разных маньчжурских вариантов. Видимо они отражают какие-то непонятные мне тонкости или это просто синонимы, но для поиска соответствий в Войниче это не важно. Из таблицы словаря делаем и сохраняем выборку глаголов в форме инфинитива — то есть все слова заканчивающиеся на инфинитивное окончание -MBI и имеющие в поле перевода подстроку " to ". Убрав окончание и сохранив результат в отдельную таблицу, получаем список глагольных маньчжурских корней MANCHU_VERB_STEM.
Например, глагол AKŪMBI (to die) сохраняется как: AKŪ.
Из указанной выше ссылки берем таблицу склонений и делаем справочную таблицу MANCHU_VERB_SUFFIX:

Все возможные варианты склонений глаголов — это фактически декартово произведение этих таблиц. Причем поиск в манускрипте проводится точно так же, по коду Metaphone, а при склонении к коду корня глагола добавляется метафоновский код окончания-суффикса. Из-за этого можно пренебречь разными вариантами окончаний для большинства времен.
Например из склонений Simple Past в словаре к разным глаголам добавляются разные окончания, но для поиска по по нарезанному манускрипту к метафоновскому коду добавится только H или K.
Past -ha (-he, -ho, -ka, -ke, -ko), Example: araha (I wrote)
Вот так выглядит часть кода представления TRANSL_VERBS21, выдающее варианты перевода сразу одно- и двух-словных сочетаний с учетом морфологии глаголов: варианты склонений выдаются через внутренний подзапрос с UNION ALL:
<code class="sql">SELECT LPAD ( TRIM ( REGEXP_REPLACE (idx, '<([[:digit:]]+)([rv]).([[:digit:]]*)>', '\1')), 3, '0') lpad1, REGEXP_REPLACE (idx, '<([[:digit:]]+)([rv]).([[:digit:]]*)>', '\2') lpad2, LPAD( trim( regexp_replace(idx, '(\.[:digit:]*)>', '\1') ) , 3, '0') lpad3, nw.ID, nw.id_type, nw.n_type, nw.idx, nw.n, nw.nword, nw.sound_code, nw.mph21_code, v.word, v.translation FROM VMS.gonk2_nword nw LEFT JOIN (SELECT VS.STEM || suff.suffix WORD, suff.description || ' : ' || VS.TRANSLATION translation, metaphone21 (VS.STEM || suff.suffix) mph21 FROM VMS.MANCHU_VERB_STEM vs CROSS JOIN VMS.MANCHU_VERB_SUFFIX suff WHERE suff.suffix <> 'mbi' UNION ALL SELECT D.WORD, D.TRANSLATION, D.MPH21_CODE FROM VMS.MANCHU_DICT_JOIN d) v ON NW.MPH21_CODE = v.mph21 WHERE nw.n_type IN (1, 2) </code>
Пример. В маньчжурской грамматике есть еще множество вариантов изменения глаголов с помощью суффиксов, но совсем глубоко закапываться — заняло слишком много сил, так что давайте просто посмотрим, как выявляются морфологии глагола NIYOHOMBI:
<code class="sql">select * from VMS.TRANSL_VERBS21 rt where 1=1 and ( word like '%HOMBI%' or translation like '%niyohomb%' or word like '%NIOH%' ) and n_type = 2 </code>

Результаты
Пересечение со словами из списка Сводеша
Списки Сводеша (Swadesh lists) — базисная лексика, наборы основных слов, по которым лингвисты оценивают родство двух или нескольких языков между собой. Например, вот здесь таблица сравнения славянских языков по списку Сводеша. Также по таблицам оценивают скорость изменения языка во времени. Базовые слова из таких списков замещаются или меняются намного реже, чем другие, но время от времени и они тоже. Например, в русском языке слово «глаз» — наносное, почти жаргонное, пришло на смену общеславянскому слову «око» в каком-то там 13 или 14 веке. Первоначально означало камешек с дыркой внутри. Очи остались в поэзии, пословицах и церковных текстах. Списки Сводеша есть на 100, 200 и 215 слов. Пишут, что лингвисты больше всего используют самый короткий список на 100 слов. Если интересно, вот биография Морриса Сводеша на русском.
Просто для интереса я записал большой английско-маньчжурский список на 207 слов в отдельную таблицу и пересек со всеми переводами всех наборов из 1 и 2 слов из манускрипта, отсортировав по частоте. Получилась вот такая таблица — это самые верхние, 33 самых частых слов. Тут тоже не все чисто, потому что многие маньчжурские слова в нем приведены в 2 или 3 вариантах в одном поле и значит в, но для первичной оценки — сойдет.
<code class="sql">select T21.NWORD, SWM.ENG_WORD, SWM.WORD, count(*) from VMS.TRANSL_VERBS21 t21 JOIN (select eng_word, upper(word) WORD from VMS.SWADESH_MANCHU ) swm ON swm.word = t21.word group by T21.NWORD, SWM.ENG_WORD, swm.word order by 4 desc </code>
Похожих слов не так много, но кое что есть: seed, right, sun, you, to give и несколько других:
Топ 30 таблицы
| NWORD | SWADESH_ENGLISH | SWADESH_MANCHU | COUNT |
| us | seed | USE | 559 |
| bi | moon | BIYA | 306 |
| s | you (sing.) | SI | 290 |
| burg | dust | BURAKI | 194 |
| n'o | earth | NA | 171 |
| ji | and | JAI | 111 |
| ji | child | JUI | 111 |
| b | moon | BIYA | 101 |
| tgi | cloud | TUGI | 57 |
| tobi | there | TUBA | 52 |
| fus | back | FISA | 47 |
| tbi | there | TUBA | 40 |
| usi | seed | USE | 35 |
| n'oh | earth | NA | 34 |
| n | earth | NA | 32 |
| tji | cloud | TUGI | 32 |
| šun | sun | ŠUN | 21 |
| šun | ear | ŠAN | 21 |
| jo | child | JUI | 20 |
| jo | and | JAI | 20 |
| bo | moon | BIYA | 20 |
| ici | right | ICI | 19 |
| ici | new | ICE | 19 |
| šon | ear | ŠAN | 15 |
| šon | sun | ŠUN | 15 |
| tob | there | TUBA | 12 |
| si | you (sing.) | SI | 12 |
| toji | cloud | TUGI | 12 |
| tb | there | TUBA | 12 |
| sun | good | SAIN | 12 |
| so | you (sing.) | SI | 11 |
| bumbi | to give | BUMBI | 9 |
Статистика по характерным маньчжурским буквосочетаниям
Следующий запрос показывает распределение по частоте таких слов и пар слов с убранными пробелами, которые строго совпадают со словами из словаря. Из всего множества выбраны слова, имеющие характерные для маньчжурского буквосочетания — типа ng , os, mb и так далее. Буквосочетния были выявлены из текста VMS онлайновым анализатором TAPoR с сайта канадского университета Макмастера. Сейчас там есть целая коллекция анализаторов и визуализаторов зависимостей в текстах, но именно этот, что на скриншоте, к сожалению уже недоступен. Есть версия, где нужно копи-пастить текст в форму на страничке, но ссылку на текст передать в параметрах уже нельзя.

Для сравнения — визуализация то же программой собранного мной крошечного маньчжурского корпуса на 14 кб. Это почти все, что удалось накопать — несколько коротких сказок, несколько страниц перевода Дао Де Цзин и несколько материалов для чтения.

Заметно, что визуализатор выделяет уже целые длинные слова, такие как niyalma (человек) или bithe( книга). Таких слов в манускрипте нет, но зато есть множество редких обрывков или целых слов, вполне согласующихся с грамматикой языка, многие даже со склонениями.
В статье Монтемурро проанализированы энтропийные близости слов рукописи и на построена диаграмма нескольких кластеров слов, связанных между собой большой близостью ( Рис.2 ). Этот же рисунок графов с наложенными «переводами» выглядит так.

Здесь я пропустил несколько слов и надо было с самого начала делать синий цвет у всех надписей…
Приведенный ниже запрос считает статистику по частоте слов с включениями характерных частей, выделенных онлайновым анализатором из первого скриншота. Еще ниже показаны результаты.
<code class="sql"> select nword, word, translation , count(*) from VMS.TRANSL_VERBS21 t where ( T.NWORD like '%ng%' OR nword like '%mb%' OR nword like '%us%' OR nword like '%os%' OR nword like '%šom%' OR nword like '%um%' OR nword like '%tk%' OR nword like '%urg%' OR nword like '%ur%' ) and upper(trim( replace(nword,' ') )) = word group by nword, word, translation order by 4 desc </code>
Всего в таблице 38 слов, но показаны 17 с частотой более 1, остальные под спойлером.
| NWORD | WORD | TRANSLATION | COUNT(*) |
|---|---|---|---|
| cos | COS | the sound of ricocheting or rebounding | 28 |
| ombi | OMBI | (imperfect participle -joro, imperative -so) 1. to become, to change into 2. to be, to exist 3. to be proper, to be permissible | 18 |
| usun | USUN | fussy, bothersome, overly talkative | 11 |
| us un | USUN | fussy, bothersome, overly talkative | 10 |
| bumbi | BUMBI | (-he) to give | 9 |
| šom bi | ŠOMBI | (-ha) 1. to scrape, to scrape off, to level off 2. to curry (livestock) | 8 |
| tombi | TOMBI | see toombi :: to scold, to rail at, to abuse, to curse | 8 |
| oso | OSO | the imperative of ombi | 6 |
| tosi | TOSI | white spot on the forehead of an animal | 6 |
| šombi | ŠOMBI | (-ha) 1. to scrape, to scrape off, to level off 2. to curry (livestock) | 5 |
| os o | OSO | the imperative of ombi | 4 |
| bum bi | BUMBI | (-he) to give | 3 |
| fusi | FUSI | abominable, loathsome, frightful, monstrous | 3 |
| bombi | BOMBI | (-ngko, -re) to pierce, to bore, to make a hole with an awl or pick | 2 |
| urg un | URGUN | 1. joy, felicity, happiness 2. auspicious sign, good portent 3. congratulations | 2 |
| uri | URI | 1. a round straw container used for storing grain 2. see urui :: 1. just, only 2. steadily, consistently, always | 2 |
| dombi | DOMBI | to alight (of birds and insects) | 2 |
Остальные слова с ng, os, mb и т.д.
| NWORD | WORD | TRANSLATION | COUNT(*) |
|---|---|---|---|
| dumbi | DUMBI | (for tūmbi) to hit, to strike | 1 |
| jombi | JOMBI | (2) (-ngko, -ndoro, -mpi) 1. to bring to mind, to recall, to mention, to bring up 2. to move in the womb | 1 |
| fus i | FUSI | abominable, loathsome, frightful, monstrous | 1 |
| tos i | TOSI | white spot on the forehead of an animal | 1 |
| jombi | JOMBI | (1) (-ho, -ro) to cut with a fodder knife | 1 |
| gombi | GOMBI | (-ha) to go back on one's word, to break a promise, to renege | 1 |
| obumbi | OBUMBI | 1. caus. of ombi 2. to make, to make into, to cause to become, to consider as | 1 |
| urgun | URGUN | 1. joy, felicity, happiness 2. auspicious sign, good portent 3. congratulations | 1 |
| mus i | MUSI | a broth made of roasted flour, sugar., and water | 1 |
| šos ihi | ŠOSIHI | see šosiki :: 1. quick-tempered, irascible 2. chipmunk (Eutamius sibiricus) | 1 |
| fumbi | FUMBI | (2) (-ngke, -mpi) to become numb | 1 |
| fursun | FURSUN | 1. shoots, sprouts (especially of a grain) 2. sawdust | 1 |
| šum bi | ŠUMBI | (-ngke, -mpi) to be thoroughly acquainted with, to be well-versed in, to know thoroughly | 1 |
| ungg u | UNGGU | 1. first, original 2. the first player at the gacuha game | 1 |
| urg umbi | URGUMBI | see urhumbi :: to lean to one side, to be lopsided, to be partial, to be prejudiced to one side | 1 |
| b ombi | BOMBI | (-ngko, -re) to pierce, to bore, to make a hole with an awl or pick | 1 |
| us umbi | USUMBI | to go downstream, to go with the current | 1 |
| tumbi | TUMBI | to hunt, to pursue | 1 |
| om osi | OMOSI | plural of omolo | 1 |
| bombon | BOMBON | a pile, a wad, a cluster, a bunch | 1 |
| fumbi | FUMBI | (1) (-ha/he) to wipe, to wipe off | 1 |
Напоследок — таблица точных соответствий слов из манускрипта и словаря, длиной не менее 3 букв, отсортированных по убыванию длины и только потом по частоте.
Опять, топ показан, остальное — под спойлером. Тексты запросов приводятся лишь потому, что по моему мнению наиболее компактно выражают, что в таблице.
<code class="sql"> select nword, word, translation , count(*) from VMS.TRANSL_VERBS21 t where upper(trim( replace(nword,' ') )) = word and length(word) >= 3 group by nword, word, translation order by length(word) desc, 4 desc </code>
| NWORD | WORD | TRANSLATION | COUNT(*) |
|---|---|---|---|
| urg umbi | URGUMBI | see urhumbi :: to lean to one side, to be lopsided, to be partial, to be prejudiced to one side | 1 |
| bombon | BOMBON | a pile, a wad, a cluster, a bunch | 1 |
| obumbi | OBUMBI | 1. caus. of ombi 2. to make, to make into, to cause to become, to consider as | 1 |
| šos ihi | ŠOSIHI | see šosiki :: 1. quick-tempered, irascible 2. chipmunk (Eutamius sibiricus) | 1 |
| us umbi | USUMBI | to go downstream, to go with the current | 1 |
| fursun | FURSUN | 1. shoots, sprouts (especially of a grain) 2. sawdust | 1 |
| bumbi | BUMBI | (-he) to give | 9 |
| tombi | TOMBI | see toombi :: to scold, to rail at, to abuse, to curse | 8 |
| šom bi | ŠOMBI | (-ha) 1. to scrape, to scrape off, to level off 2. to curry (livestock) | 8 |
| šombi | ŠOMBI | (-ha) 1. to scrape, to scrape off, to level off 2. to curry (livestock) | 5 |
| tom bi | TOMBI | see toombi :: to scold, to rail at, to abuse, to curse | 4 |
| bum bi | BUMBI | (-he) to give | 3 |
| bombi | BOMBI | (-ngko, -re) to pierce, to bore, to make a hole with an awl or pick | 2 |
| dombi | DOMBI | to alight (of birds and insects) | 2 |
| urg un | URGUN | 1. joy, felicity, happiness 2. auspicious sign, good portent 3. congratulations | 2 |
| b ombi | BOMBI | (-ngko, -re) to pierce, to bore, to make a hole with an awl or pick | 1 |
| jom bi | JOMBI | (1) (-ho, -ro) to cut with a fodder knife | 1 |
| ungg u | UNGGU | 1. first, original 2. the first player at the gacuha game | 1 |
| bom bi | BOMBI | (-ngko, -re) to pierce, to bore, to make a hole with an awl or pick | 1 |
| jombi | JOMBI | (2) (-ngko, -ndoro, -mpi) 1. to bring to mind, to recall, to mention, to bring up 2. to move in the womb | 1 |
| dumbi | DUMBI | (for tūmbi) to hit, to strike | 1 |
| dom bi | DOMBI | to alight (of birds and insects) | 1 |
| šum bi | ŠUMBI | (-ngke, -mpi) to be thoroughly acquainted with, to be well-versed in, to know thoroughly | 1 |
Остальные 83 слова
| NWORD | WORD | TRANSLATION | COUNT(*) |
|---|---|---|---|
| ici hi | ICIHI | spot, blemish, flaw | 1 |
| fumbi | FUMBI | (2) (-ngke, -mpi) to become numb | 1 |
| jom bi | JOMBI | (2) (-ngko, -ndoro, -mpi) 1. to bring to mind, to recall, to mention, to bring up 2. to move in the womb | 1 |
| tumbi | TUMBI | to hunt, to pursue | 1 |
| urgun | URGUN | 1. joy, felicity, happiness 2. auspicious sign, good portent 3. congratulations | 1 |
| om osi | OMOSI | plural of omolo | 1 |
| gombi | GOMBI | (-ha) to go back on one's word, to break a promise, to renege | 1 |
| jombi | JOMBI | (1) (-ho, -ro) to cut with a fodder knife | 1 |
| fumbi | FUMBI | (1) (-ha/he) to wipe, to wipe off | 1 |
| ombi | OMBI | (imperfect participle -joro, imperative -so) 1. to become, to change into 2. to be, to exist 3. to be proper, to be permissible | 18 |
| usun | USUN | fussy, bothersome, overly talkative | 11 |
| us un | USUN | fussy, bothersome, overly talkative | 10 |
| tosi | TOSI | white spot on the forehead of an animal | 6 |
| om bi | OMBI | (imperfect participle -joro, imperative -so) 1. to become, to change into 2. to be, to exist 3. to be proper, to be permissible | 4 |
| gobi | GOBI | desert, wasteland | 4 |
| lobi | LOBI | gluttonous, ravenous | 4 |
| lomi | LOMI | rice kept in storage for a number of years--the same as hukšeri bele | 3 |
| uhun | UHUN | bundle, package | 3 |
| hogi | HOGI | turkey | 3 |
| fusi | FUSI | abominable, loathsome, frightful, monstrous | 3 |
| šoho | ŠOHO | the white of an egg | 3 |
| kobi | KOBI | 1. concave place, depression 2. the depressions on both sides of the nose | 3 |
| šuci | ŠUCI | one who pretends to know what he in fact doesn't | 2 |
| šoli | ŠOLI | falling short, short of the mark | 2 |
| ucun | UCUN | song, ballad | 2 |
| l omi | LOMI | rice kept in storage for a number of years--the same as hukšeri bele | 1 |
| to bo | TOBO | a simple hut made from willow branches or other like material | 1 |
| fus i | FUSI | abominable, loathsome, frightful, monstrous | 1 |
| un un | UNUN | a load (that can be carried on the back), burden | 1 |
| hoji | HOJI | coriander | 1 |
| tos i | TOSI | white spot on the forehead of an animal | 1 |
| šol o | ŠOLO | 1. free time, leisure, vacation, leave 2. opportunity 3. empty space | 1 |
| jo lo | JOLO | 1. doe, female deer 2. hateful, hideous | 1 |
| luši | LUŠI | secretary in a Board of the eighth or ninth rank | 1 |
| foji | FOJI | a skin covering for boots and shoes (worn in cold weather) | 1 |
| mus i | MUSI | a broth made of roasted flour, sugar., and water | 1 |
| onon | ONON | the male zeren; cf. jeren | 1 |
| com o | COMO | see coman :: goblet, large cup for wine | 1 |
| joli | JOLI | a ladle with many small holes in it used for straining | 1 |
| biši | BIŠI | crab louse, tick | 1 |
| l obi | LOBI | gluttonous, ravenous | 1 |
| goji | GOJI | a crooked finger | 1 |
| bi ši | BIŠI | crab louse, tick | 1 |
| dobi | DOBI | fox | 1 |
| toho | TOHO | a half-grown moose | 1 |
| oton | OTON | a wooden tub without handles or feet | 1 |
| oci | OCI | (conditional of ombi) a particle used to set off the subject: 'as for' | 106 |
| cos | COS | the sound of ricocheting or rebounding | 28 |
| fun | FUN | 1. one-hundredth (of a Chinese foot) 2. powder 3. fragrant odor | 28 |
| šun | ŠUN | 1. sun 2. day | 21 |
| ici | ICI | 1. right (as opposed to left) 2. direction, dimension 3. in accordance with, along with, after, according to, facing, on the side of, toward | 19 |
| oho | OHO | armpit; cf. 0, o mayan, ogū | 18 |
| sun | SUN | milk | 12 |
| tob | TOB | straight, upright, serious, right, just | 12 |
| tun | TUN | island | 8 |
| jon | JON | memory, recall | 8 |
| ofi | OFI | 1. a snare for catching pheasants 2. (perfect converb of ombi) because | 7 |
| bon | BON | pick, awl, tool for making holes in ice | 7 |
| oso | OSO | the imperative of ombi | 6 |
| ton | TON | 1. number 2. counting, reckoning 3. fate 4. one of the twenty-four divisions of the solar year | 5 |
| omo | OMO | lake, pond | 4 |
| os o | OSO | the imperative of ombi | 4 |
| hoi | HOI | see hūi :: 1. red felt edging on the lower part of a saddle blanket 2. an exclamation--now, then 3. meeting, assembly, association | 3 |
| s un | SUN | milk | 2 |
| uri | URI | 1. a round straw container used for storing grain 2. see urui :: 1. just, only 2. steadily, consistently, always | 2 |
| ošo | OŠO | a leather glove with three fingers used for holding falcons | 2 |
| icu | ICU | a fur coat or jacket without an outer covering | 2 |
| son | SON | rafter, roof support of a tent | 2 |
| jo n | JON | memory, recall | 2 |
| om o | OMO | lake, pond | 2 |
| o so | OSO | the imperative of ombi | 1 |
| ogo | OGO | 1. the depression of a mortar 2. the holes on the iron plate that is used for making the heads of nails | 1 |
| i ci | ICI | 1. right (as opposed to left) 2. direction, dimension 3. in accordance with, along with, after, according to, facing, on the side of, toward | 1 |
| joo | JOO | 1. an imperial order 2. interjection: enough! stop! it won't do! | 1 |
| isi | ISI | Japanese larch | 1 |
| coo | COO | a spade | 1 |
| tok | TOK | (onom.) the sound of striking a hollow wooden object | 1 |
| don | DON | fluttering of birds from one place to another, alighting (of birds) | 1 |
| co s | COS | the sound of ricocheting or rebounding | 1 |
| jun | JUN | 1. stove, hearth 2. tissue, pulp of a tree 3. vein | 1 |
| too | TOO | a hand drum | 1 |
| hon | HON | very, most, too | 1 |
| uli | ULI | 1. bowstring 2. fruit of the flowering cherry (Prunus sinensis) | 1 |
Отдельные слова
Статистика по некоторым словам, отобранных по словарю. Прежде всего интересно искать в травнике. Из списка убрал слово «женщина», чтобы сократить вывод.
<code class="sql"> select nword, word, translation , count(*) from VMS.TRANSL_VERBS21 t where ( translation like '%magic%' or translation like '%medicine%' or translation like '%herb%' or translation like '%grass%' or translation like '%medicine%' -- or translation like '%woman%' ) group by nword, word, translation order by word , 4 desc </code>
Вот, что получается. Здесь уже не только полностью совпадающие слова, но все совпадения по метафону — поэтому некоторые непохожи. Но магии ( FANGGA) в тексте достаточно…
| NWORD | WORD | TRANSLATION | COUNT(*) |
|---|---|---|---|
| bcti | BEKTO | fritillary (an herbal medicine) | 2 |
| b icti | BEKTO | fritillary (an herbal medicine) | 1 |
| bi octo | BEKTO | fritillary (an herbal medicine) | 1 |
| bi gti | BEKTO | fritillary (an herbal medicine) | 1 |
| bocti | BEKTO | fritillary (an herbal medicine) | 1 |
| bkt | BEKTO | fritillary (an herbal medicine) | 1 |
| bi icto | BEKTO | fritillary (an herbal medicine) | 1 |
| bicti | BEKTO | fritillary (an herbal medicine) | 1 |
| c kurg | CACARAKŪ | a gray grasshopper | 1 |
| droci | DERESU | feather grass, broom grass (Lasiagrostis splendens) | 1 |
| fungg | FANGGA | magic, possessed of magic powers | 108 |
| f ungg | FANGGA | magic, possessed of magic powers | 4 |
| fo ungg | FANGGA | magic, possessed of magic powers | 1 |
| fi iungg | FANGGA | magic, possessed of magic powers | 1 |
| fungg i | FANGGA | magic, possessed of magic powers | 1 |
| fngg | FANGGA | magic, possessed of magic powers | 1 |
| fungg? | FANGGA | magic, possessed of magic powers | 1 |
| fun icko | FANGGA | magic, possessed of magic powers | 1 |
| fumobi | FEMBI | 1. to lay out new-mown hay or other grass to dry 2. to talk heedlessly | 1 |
| fumbi | FEMBI | 1. to lay out new-mown hay or other grass to dry 2. to talk heedlessly | 1 |
| fi hi | FEha | Simple Past: 1. to lay out new-mown hay or other grass to dry 2. to talk heedlessly | 1 |
| fug | FEka | Simple Past (suff.k): 1. to lay out new-mown hay or other grass to dry 2. to talk heedlessly | 2 |
| fi ohki | FEka | Simple Past (suff.k): 1. to lay out new-mown hay or other grass to dry 2. to talk heedlessly | 1 |
| fuk | FEka | Simple Past (suff.k): 1. to lay out new-mown hay or other grass to dry 2. to talk heedlessly | 1 |
| fum bumbi | FEme bimbi | Present Continuous 1: 1. to lay out new-mown hay or other grass to dry 2. to talk heedlessly | 1 |
Остальное. Примерно сотня строк, некоторые интересны. Например OKTO — 1. drug, medicine 2. gunpowder 3. dye 4. poison
| NWORD | WORD | TRANSLATION | COUNT(*) |
|---|---|---|---|
| fi | FOYO | 1. ula grass--a soft grass used as padding in shoes 2. cloth woven from horsehair | 67 |
| f | FOYO | 1. ula grass--a soft grass used as padding in shoes 2. cloth woven from horsehair | 16 |
| ?fi | FOYO | 1. ula grass--a soft grass used as padding in shoes 2. cloth woven from horsehair | 4 |
| fu | FOYO | 1. ula grass--a soft grass used as padding in shoes 2. cloth woven from horsehair | 2 |
| fo | FOYO | 1. ula grass--a soft grass used as padding in shoes 2. cloth woven from horsehair | 2 |
| fi oh | FOYO | 1. ula grass--a soft grass used as padding in shoes 2. cloth woven from horsehair | 1 |
| f? | FOYO | 1. ula grass--a soft grass used as padding in shoes 2. cloth woven from horsehair | 1 |
| fus l | FUSELI | an inedible freshwater fish resembling the black carp whose gall is used as a medicine | 1 |
| gurg | GURUka | Simple Past (suff.k): (1) to dig up, to dig out (vegetables, herbs) | 1 |
| hkohti | HAKDA | old grass left over from the previous year, a spot of grass remaining in an area that has been burnt over | 1 |
| hocti | HAKDA | old grass left over from the previous year, a spot of grass remaining in an area that has been burnt over | 1 |
| hkti | HAKDA | old grass left over from the previous year, a spot of grass remaining in an area that has been burnt over | 1 |
| h?i octi | HAKDA | old grass left over from the previous year, a spot of grass remaining in an area that has been burnt over | 1 |
| hurs | HERESU | a grass growing along the edges of salt marshes that is eaten by camels | 17 |
| ?hurs | HERESU | a grass growing along the edges of salt marshes that is eaten by camels | 1 |
| hurci | HERESU | a grass growing along the edges of salt marshes that is eaten by camels | 1 |
| hurs i | HERESU | a grass growing along the edges of salt marshes that is eaten by camels | 1 |
| hofi | HIFE | barnyard grass (Panicum crusgalli) | 3 |
| h?fi | HIFE | barnyard grass (Panicum crusgalli) | 2 |
| hfi | HIFE | barnyard grass (Panicum crusgalli) | 1 |
| ici hi | ISIha | Simple Past: (2) (-ha) to pull up (grass), to pluck | 1 |
| ios ug | ISIka | Simple Past (suff.k): (2) (-ha) to pull up (grass), to pluck | 1 |
| icico | ISIka | Simple Past (suff.k): (2) (-ha) to pull up (grass), to pluck | 1 |
| jol n | JALAN | 1. a section (of bamboo, grass, etc.), a joint 2. generation, age 3. world 4. subdivision of a banner, ranks 5. measure word for walls and fences | 1 |
| n'oci mbi | NIYECEMBI | 1. to mend 2. to fill in, to fill (a post) 3. to supplement 4. to nourish (of foods and medicines) | 1 |
| n'oci ohobi | NIYECEha bi | Past Continuous 1: 1. to mend 2. to fill in, to fill (a post) 3. to supplement 4. to nourish (of foods and medicines) | 1 |
| n'oc?i hob | NIYECEha bi | Past Continuous 1: 1. to mend 2. to fill in, to fill (a post) 3. to supplement 4. to nourish (of foods and medicines) | 1 |
| n'oc?i hob | NIYECEhobi | Indefinite Past: 1. to mend 2. to fill in, to fill (a post) 3. to supplement 4. to nourish (of foods and medicines) | 1 |
| n'oci ohobi | NIYECEhobi | Indefinite Past: 1. to mend 2. to fill in, to fill (a post) 3. to supplement 4. to nourish (of foods and medicines) | 1 |
| n'oc?i hob | NIYECEhoi bi | Past Continuous 3: 1. to mend 2. to fill in, to fill (a post) 3. to supplement 4. to nourish (of foods and medicines) | 1 |
| n'oci ohobi | NIYECEhoi bi | Past Continuous 3: 1. to mend 2. to fill in, to fill (a post) 3. to supplement 4. to nourish (of foods and medicines) | 1 |
| n'octi | NUKTE | 1. an area in which nomads lead their flocks and herds following water and grass 2. baggage carried on pack animals | 318 |
| n'octo | NUKTE | 1. an area in which nomads lead their flocks and herds following water and grass 2. baggage carried on pack animals | 28 |
| n'ogti | NUKTE | 1. an area in which nomads lead their flocks and herds following water and grass 2. baggage carried on pack animals | 3 |
| n'octi o | NUKTE | 1. an area in which nomads lead their flocks and herds following water and grass 2. baggage carried on pack animals | 3 |
| n'o cti | NUKTE | 1. an area in which nomads lead their flocks and herds following water and grass 2. baggage carried on pack animals | 3 |
| n'ohkti | NUKTE | 1. an area in which nomads lead their flocks and herds following water and grass 2. baggage carried on pack animals | 3 |
| n'cto | NUKTE | 1. an area in which nomads lead their flocks and herds following water and grass 2. baggage carried on pack animals | 1 |
| n'o ct | NUKTE | 1. an area in which nomads lead their flocks and herds following water and grass 2. baggage carried on pack animals | 1 |
| n'oct | NUKTE | 1. an area in which nomads lead their flocks and herds following water and grass 2. baggage carried on pack animals | 1 |
| n'okti | NUKTE | 1. an area in which nomads lead their flocks and herds following water and grass 2. baggage carried on pack animals | 1 |
| n'oocti | NUKTE | 1. an area in which nomads lead their flocks and herds following water and grass 2. baggage carried on pack animals | 1 |
| n'oicti | NUKTE | 1. an area in which nomads lead their flocks and herds following water and grass 2. baggage carried on pack animals | 1 |
| n'ocoti | NUKTE | 1. an area in which nomads lead their flocks and herds following water and grass 2. baggage carried on pack animals | 1 |
| n' octi | NUKTE | 1. an area in which nomads lead their flocks and herds following water and grass 2. baggage carried on pack animals | 1 |
| n'oct? | NUKTE | 1. an area in which nomads lead their flocks and herds following water and grass 2. baggage carried on pack animals | 1 |
| n'ohki ohti | NUKTE | 1. an area in which nomads lead their flocks and herds following water and grass 2. baggage carried on pack animals | 1 |
| n'okhti | NUKTE | 1. an area in which nomads lead their flocks and herds following water and grass 2. baggage carried on pack animals | 1 |
| n'cti | NUKTE | 1. an area in which nomads lead their flocks and herds following water and grass 2. baggage carried on pack animals | 1 |
| n'octu | NUKTE | 1. an area in which nomads lead their flocks and herds following water and grass 2. baggage carried on pack animals | 1 |
| octi | OKTO | 1. drug, medicine 2. gunpowder 3. dye 4. poison | 180 |
| octo | OKTO | 1. drug, medicine 2. gunpowder 3. dye 4. poison | 26 |
| o cti | OKTO | 1. drug, medicine 2. gunpowder 3. dye 4. poison | 8 |
| oicti | OKTO | 1. drug, medicine 2. gunpowder 3. dye 4. poison | 3 |
| oct | OKTO | 1. drug, medicine 2. gunpowder 3. dye 4. poison | 2 |
| ocou ti | OKTO | 1. drug, medicine 2. gunpowder 3. dye 4. poison | 1 |
| ohkti | OKTO | 1. drug, medicine 2. gunpowder 3. dye 4. poison | 1 |
| o octo | OKTO | 1. drug, medicine 2. gunpowder 3. dye 4. poison | 1 |
| ocoti | OKTO | 1. drug, medicine 2. gunpowder 3. dye 4. poison | 1 |
| ohko ?ohti | OKTO | 1. drug, medicine 2. gunpowder 3. dye 4. poison | 1 |
| ogti | OKTO | 1. drug, medicine 2. gunpowder 3. dye 4. poison | 1 |
| ohkoti | OKTO | 1. drug, medicine 2. gunpowder 3. dye 4. poison | 1 |
| octoi | OKTO | 1. drug, medicine 2. gunpowder 3. dye 4. poison | 1 |
| oc to | OKTO | 1. drug, medicine 2. gunpowder 3. dye 4. poison | 1 |
| ohki to | OKTO | 1. drug, medicine 2. gunpowder 3. dye 4. poison | 1 |
| octi o | OKTO | 1. drug, medicine 2. gunpowder 3. dye 4. poison | 1 |
| ok?hti | OKTO | 1. drug, medicine 2. gunpowder 3. dye 4. poison | 1 |
| octu | OKTO | 1. drug, medicine 2. gunpowder 3. dye 4. poison | 1 |
| ohktl ohko | OKTOLOka | Simple Past (suff.k): 1. to treat with medicine 2. to poison | 1 |
| octol ohki | OKTOLOka | Simple Past (suff.k): 1. to treat with medicine 2. to poison | 1 |
| omombi | OMIMBI | 1. to drink 2. to smoke (tobacco) 3. to take (medicine) | 2 |
| ommbi | OMIMBI | 1. to drink 2. to smoke (tobacco) 3. to take (medicine) | 1 |
| omumbi | OMIMBI | 1. to drink 2. to smoke (tobacco) 3. to take (medicine) | 1 |
| omhi | OMIha | Simple Past: 1. to drink 2. to smoke (tobacco) 3. to take (medicine) | 2 |
| omohi | OMIha | Simple Past: 1. to drink 2. to smoke (tobacco) 3. to take (medicine) | 1 |
| omhibi | OMIha bi | Past Continuous 1: 1. to drink 2. to smoke (tobacco) 3. to take (medicine) | 2 |
| omi hob?i | OMIha bi | Past Continuous 1: 1. to drink 2. to smoke (tobacco) 3. to take (medicine) | 1 |
| omhibi | OMIhobi | Indefinite Past: 1. to drink 2. to smoke (tobacco) 3. to take (medicine) | 2 |
| omi hob?i | OMIhobi | Indefinite Past: 1. to drink 2. to smoke (tobacco) 3. to take (medicine) | 1 |
| omhibi | OMIhoi bi | Past Continuous 3: 1. to drink 2. to smoke (tobacco) 3. to take (medicine) | 2 |
| omi hob?i | OMIhoi bi | Past Continuous 3: 1. to drink 2. to smoke (tobacco) 3. to take (medicine) | 1 |
| om hki | OMIka | Simple Past (suff.k): 1. to drink 2. to smoke (tobacco) 3. to take (medicine) | 2 |
| om c | OMIka | Simple Past (suff.k): 1. to drink 2. to smoke (tobacco) 3. to take (medicine) | 1 |
| omhki | OMIka | Simple Past (suff.k): 1. to drink 2. to smoke (tobacco) 3. to take (medicine) | 1 |
| omcu | OMIka | Simple Past (suff.k): 1. to drink 2. to smoke (tobacco) 3. to take (medicine) | 1 |
| omo ohko? | OMIka | Simple Past (suff.k): 1. to drink 2. to smoke (tobacco) 3. to take (medicine) | 1 |
| omc | OMIka | Simple Past (suff.k): 1. to drink 2. to smoke (tobacco) 3. to take (medicine) | 1 |
| omug | OMIka | Simple Past (suff.k): 1. to drink 2. to smoke (tobacco) 3. to take (medicine) | 1 |
| omco?i | OMIka | Simple Past (suff.k): 1. to drink 2. to smoke (tobacco) 3. to take (medicine) | 1 |
| s | SA | 1. shaft or thill of an oxcart 2. feather grass from which the outside surface of summer hats are made 3. plural suffix (sometimes written separately) | 290 |
| si | SA | 1. shaft or thill of an oxcart 2. feather grass from which the outside surface of summer hats are made 3. plural suffix (sometimes written separately) | 12 |
| so | SA | 1. shaft or thill of an oxcart 2. feather grass from which the outside surface of summer hats are made 3. plural suffix (sometimes written separately) | 11 |
| s _ | SA | 1. shaft or thill of an oxcart 2. feather grass from which the outside surface of summer hats are made 3. plural suffix (sometimes written separately) | 4 |
| s ^ | SA | 1. shaft or thill of an oxcart 2. feather grass from which the outside surface of summer hats are made 3. plural suffix (sometimes written separately) | 4 |
| s i | SA | 1. shaft or thill of an oxcart 2. feather grass from which the outside surface of summer hats are made 3. plural suffix (sometimes written separately) | 2 |
| s o | SA | 1. shaft or thill of an oxcart 2. feather grass from which the outside surface of summer hats are made 3. plural suffix (sometimes written separately) | 2 |
| s h | SA | 1. shaft or thill of an oxcart 2. feather grass from which the outside surface of summer hats are made 3. plural suffix (sometimes written separately) | 1 |
| ^s | SA | 1. shaft or thill of an oxcart 2. feather grass from which the outside surface of summer hats are made 3. plural suffix (sometimes written separately) | 1 |
| sus urg | SOSOROka | Simple Past (suff.k): (-ko) 1. to back up, to withdraw, to retreat 2. to wither, to become senile 3. to rake (grass) | 2 |
| sosurg | SOSOROka | Simple Past (suff.k): (-ko) 1. to back up, to withdraw, to retreat 2. to wither, to become senile 3. to rake (grass) | 1 |
| ucti | UKADA | a mound with grass growing on it | 11 |
| ucto | UKADA | a mound with grass growing on it | 1 |
| ucti | UKŪDA | see ukada :: a mound with grass growing on it | 11 |
| ucto | UKŪDA | see ukada :: a mound with grass growing on it | 1 |
| ungg un | UNGKAN | frozen snow on the top of grass | 6 |
| ungg n'o | UNGKAN | frozen snow on the top of grass | 3 |
| ungg on | UNGKAN | frozen snow on the top of grass | 2 |
| ungcun | UNGKAN | frozen snow on the top of grass | 1 |
Слова, для которых metaphone не смог подобрать ни одного перевода
Топ-15 таких слов. Некоторые из них находят толкование, если их рассматривать в паре с соседним словом — предыдущим или последующим.
| NWORD | COUNT(*) |
|---|---|
| škbi | 380 |
| tkbi | 325 |
| n'ocungg | 239 |
| bum | 234 |
| n'octbi | 230 |
| ocungg | 204 |
| n'ocum | 202 |
| n'ockbi | 181 |
| ohus | 181 |
| škfi | 179 |
| škom | 172 |
| ohungg | 166 |
| ocum | 163 |
| ohum | 161 |
Многие из них по структуре могли бы быть каким-нибудь маньчжурским словом — имеют характерные суффиксы и окончания -ng-, -ungg-, -mbi-, -bumbi- и так далее.
Одиночных слов без соответствия по самому широкому охвату (TRANSL_VERB21, со склонениями глаголов ) — 18 К из всего 40К. Однако рассмотрение пар соседних слов дает еще 30К уникальных пар, имеющих по крайней мере один метафоновский перевод. И многие слова, не имеющие вариантов перевода в паре с соседними создают сочетания, для которых перевод находится.
Например, skbi даже в парах не дает пеереводов, но следующее такое слово tkbi в одном из 325 мест образует с соседом tkbi ombi — есть 4 варианта перевода. Слово bum составляет многочисленные пары bum bi — и так далее. Наборы из трех и более соседних слов я не генерил и не проверял, но может быть 3-словные блоки стоило бы посмотреть.
Мысли
Количество совпадений слов и грамматических изменений текста позволяют сделать осторожный вывод, что в манускрипте Войнича по крайней мере используются слова из диалекта маньчжурского/чжурчжэньского языка. Последовательности слов плохо укладываются в языковые конструкции типа словосочетаний и предложений. Но их не находили и раньше, статистический анализ не выявлял их с самых первых попыток. Похоже, что во многих местах идет индексная запись — то есть короткие заметки с сокращениями, которые автору были понятны, но при этом они не складываются в связный текст. Многие слова разбиты на части, возможно автор текста записывал его с устной речи другого человека.
Я не могу определить, насколько достоверно найденные слова и их частоты говорят о том, что в рукописи есть маньжурские вставки. В тексте около 170К букв и 40К слов. Точных совпадений слов по словарю — несколько сотен, но я не беру в расчет совсем короткие слова на 1-2 знака. Кроме этого есть тысячи приблизительных совпадений, по коду метафона. Беглый просмотр по страницам вроде показывает, что слово есть в словаре, но с первого взгляда в предложения они не складываются.
Здорово было бы показать это все ученому-компаративисту, специалисту по дальневосточным языкам. Я лично с такими не знаком, но в России они должны быть. Статьи о таких личностях как Сергей Старостин и записанные интервью с ними подсказывают, что в РГГУ или МГУ надо искать. Могут, конечно, сказать, что это все ерунда. И вообще, неизвестно, как часто к ним приходят с идеями и вопросами по Войничу, может уже и надоело…
В процессе всего этого я наткнулся на любопытный онлайн-курс Corpus Linguistics от Lancaster University на платформе FutureLearn. Я даже записался на него, но, что называется, не пошло. Сама платформа и подача материала не такая удобная, как на Coursera, да и времени перестало хватать после первой недели. Может быть, стоит взяться за него основательнее в следующий заход. Из него пока могу посоветовать энтузиастам программу AntConc — она предназначена для анализа конкордансов текстов, используя загруженные корпусы их выборки из них. Также переделанная из английской в маньчжурскую версия функции Metaphone очень несовершенна — нуждается в улучшении.
При обсуждении знакомый веб-программист предложил простой способ распознать всю рукопись: порезать картинки страниц на отдельные слова и пары слов вставлять их в капчу при логине на сайты…
Ссылки с комментариями
Основное
Интервью с Марчелло Монтемурро на Lenta.ru
Marcelo A. Montemurro, Damian H. Zanette, PLoS ONE, 2013
Критика его статьи на странице войничеведа
Статья в Компьютерре 2005 года о манускрипте
Обзор-презентация истории VMS, попыток дешифровки и статистический анализ
Удобный просмотр МВ. Voyage the Voynich Manuscript
Willam Porquet's page
A Manchu Sceleton key to VMSFull trangokulation with initial VMS text
A list of theories
Voynich theoriesA visual map of Voynich evidence theories
Остальное
Visualizing textual structures in the Voynich manuscriptHoaxing the Voynich manuscript — part 3
Hoaxing the Voynich manuscript — part 4
Подробный анализ зодиакальной части
Voynich alphabets, scripts — on Omniglot
Manchu theory
Ответ Столфи о маньчжурской теории — обсуждение аспектов
Бразилец Жорже Столфи ведет самый известный и актуальный сайт по МВ, но есть много других
Zbigniew Banasik's Manchu theory
Первые переводы Збигнева Банасика
Работа польского профессора, анализ языков Земли и манускрипта
Отзыв на reddit
Manchu library
WikibooksWikibooks 2
Wikibooks 3
Wikibooks 4
Google booksManchu: A Textbook for Reading Documents: Чжурчженьский( manchu ) язык
Чжурчженьский на Омниглоте
Jurchen script on Wiki
Монгольские и тюркские заимствования в образцах малого чжурчжэньcкого письма
… Чжурчжэньское письмо. Википедия
Про Сергея Старостина и глоттохронологию
Школа злословияО Старостине на Альтаике
Сергей Старостин. Два подхода к изучению истории языка
На каком языке говорили Адам и Ева
Retouching
Большой текст воспоминаний о И.И.Захарове и русско-китайских отношениях в 19 в
Маньчжурские manchzhurskie письменные памятники как источник по истории и культуре империи Цинь 17-18 вв
voynich.net
Еще из Компьютерры 2005 года — про отчаянных расшифровщиков непрочтенных древних текстов
Картинки
Визуализатор manchu VMS в виде пузырьков — из коллекции TAPoR:

Как некоторые исследователи VMS аргументируют гипотезу о том, что женщины в бассейнах — это изображение внутренних органов человека.
1. Почки

2. Мозг

3. Сердце

4. Легкие

5. Глазные яблоки

Источник: habrahabr.ru/post/186952/
Портал БАШНЯ. Копирование, Перепечатка возможна при указании активной ссылки на данную страницу.
































{kind=link}
«Даурия» в космосе
Краткое изложение освоения космоса СССР, типы ракет и самые значимые победы на этом поприще. Часть 2