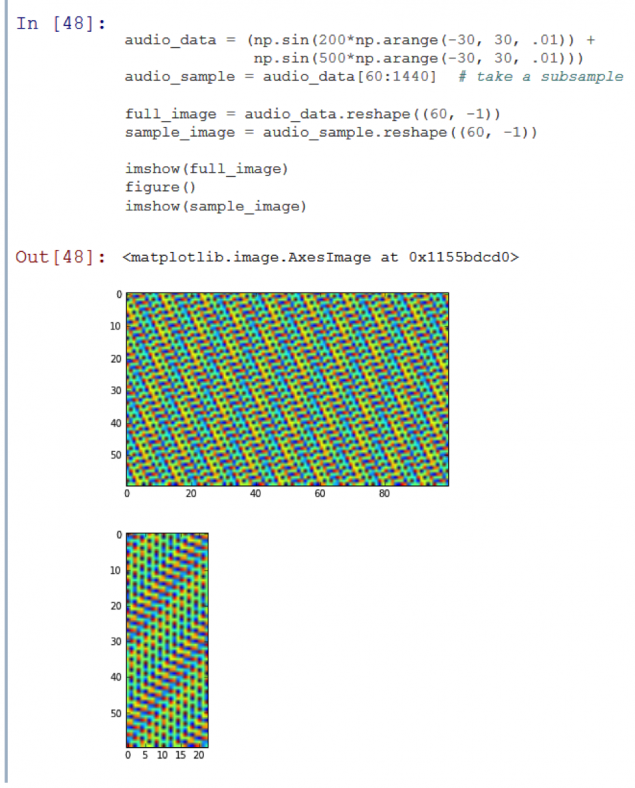
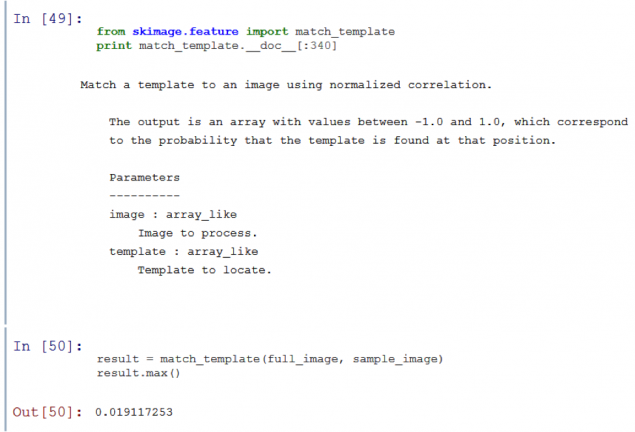
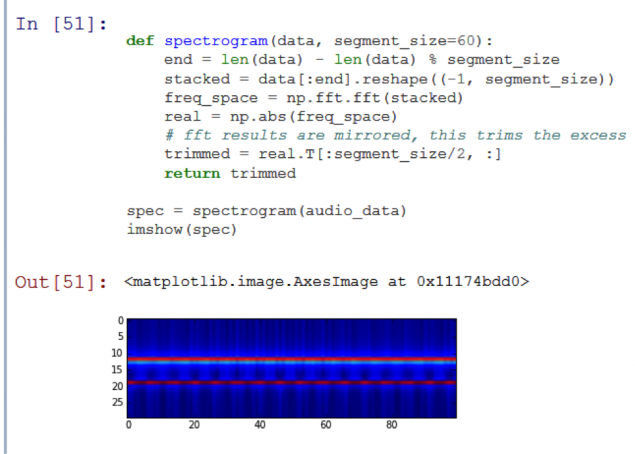
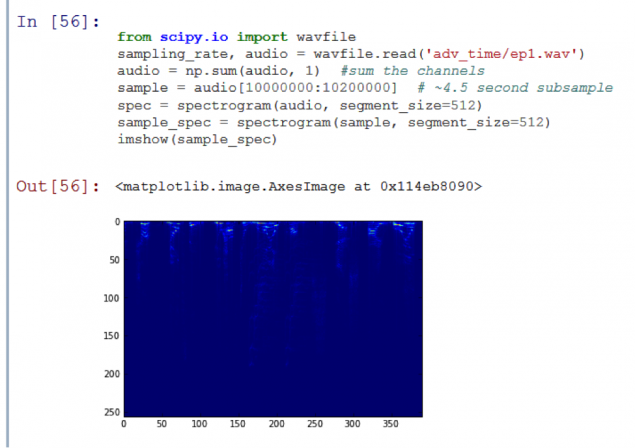
1084
机通感:使用图像处理算法audioanaliz

如果你只是想看看的Python代码,请按照 GitHub上库。
对于使用笔记本电脑IPython的材料的准备工作。您可以在<一个它下载href="http://nbviewer.ipython.org/urls/raw.github.com/jminardi/audio_fingerprinting/master/Computationalsynesthesia-JackMinardi.ipynb">ссылке.