1086
Синтезія машини: аудіо-аналіз за допомогою алгоритмів обробки зображень

Якщо ви просто хочете подивитися на Python код, перейдіть на репозиторію GitHub.
Для підготовки матеріалів використовується IPython Notebook. Ви можете завантажити його з посилання.
Графічні процесори були розроблені з метою імітації фізичних властивостей світла, але сьогодні ми використовуємо їх для вирішення багатьох інших, дуже різноманітних завдань. Чи можна використовувати алгоритми обробки зображень поза звичним доменом? Чому не використовувати їх для обробки сигналів?
Щоб вивчити це питання, я вирішив використовувати метод відповідних шаблонів і зображень для визначення аудіо. Класичні алгоритми беруть зображення і візерунок при вході, і повертає ступінь схожості малюнка до будь-якої частини зображення. Моє завдання було визначити аудіозапис в базі даних якого є частина звуку, використовуючи маскуваний метод порівняння (це те, що Shazam або SoundCloud do).
Аудіо дані представлені в одновимірному масиві дискретних чисел рівномірно розподілених за часом. Одноканальні зображення зазвичай зберігаються і обробляються як двовимірні масиви, так що я повинен якось уявити аудіозапис в двох розмірах. Найпримітивніший спосіб просто переформатувати одновимірний масив в двовимірну.
Однак, на практиці це необхідно зробити акуратно. Давайте скажемо, що ми почали захоплювати аудіо з джерела навпіл другий після запуску запису в базі даних – отриманих двовимірних масивів цих двох записів буде дуже різним. Дві вершини, розташовані поруч один з одним, може статися на протилежних кінцях зразка.
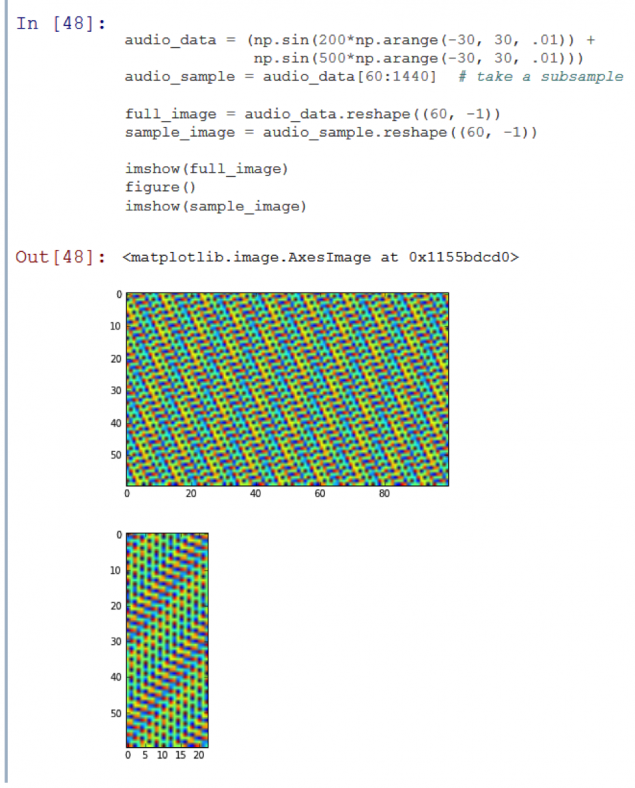
Не зрозуміло, що другий образ є частиною (підсумок) першого.
Простий алгоритм порівняння маски, послідовно направляє маску на зображення і робить порівняння (це функція збігу_template в skimage.feature). Алгоритми, які працюють таким чином, не зможуть розпізнати менший образ, представлений над тим більшим.
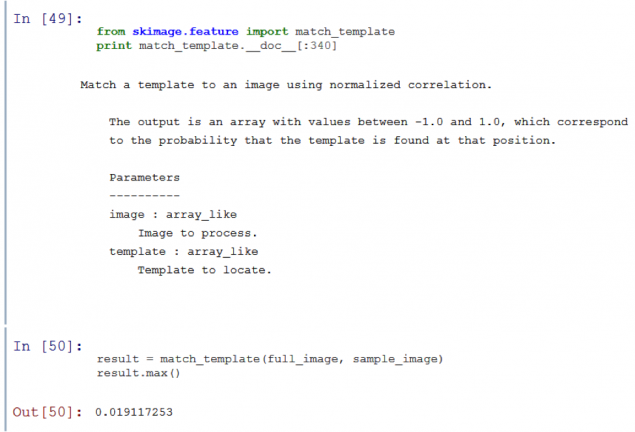
Як ви можете побачити, матч_template дає дуже низький шанс підібрати шаблон з будь-якою порцією зображення.
Відчутливість до перемикання діапазону часу може бути зведена шляхом абстрагування часової ваги і переходу на рівень сигналу. Це робиться за допомогою дискретного трансформатора Фур'єра (DPF), і робиться швидко – за допомогою швидкого перетворення Фур'є або BPF (Якщо вам потрібна додаткова інформація про DPF та BPF, перевірте пост Jake VanderPlas).
Якщо ми застосовуємо Чотириє трансформацію до кожного стовпця нашого переформатованого сигналу, ми отримуємо ідею зміни гармоніки з часом. Виявляється, що це досить поширена техніка, широко використовується при створенні спектрограм.
У своїй серці трансформатор Фур'єр розповідає про те, що на частотах сигналів є найвищі енергії. Оскільки гармоніка звукового сигналу зазвичай змінюється з часом, спектрограм містить властивості часових і частотних регіонів.
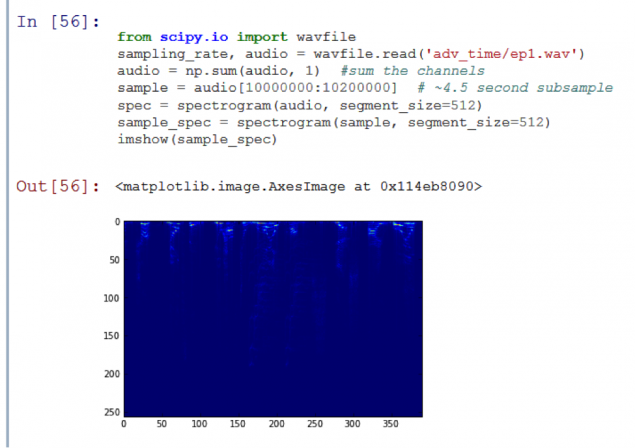
Давайте подивимося на спектрограму тестового звукового сегмента:
221280
Як видно, є дві горизонтальні лінії на малюнку. Це означає, що аудіо складається з двох змінних сигналів. Це сталося тому, що тестовий запис нічого не більше, ніж сума двох синів хвильових сигналів різної частоти.
Ми зараз маємо щось схоже на зображення і, в теорії, наш підхід працює добре з таймерами. Давайте перевіримо нашу теорію.

Успіх Функція «під ключ» розповідає про те, що ці два «знімки» мають сильну кореляцію. Але буде алгоритм роботи з звуком, що більше, ніж просто сума сигналів синової хвилі?
Я хочу переконатися, що мій комп'ютер може визначити, який епізод заданої серії грає в даний момент. Як приклад, я буду використовувати сезон 1 з анімаційного серіалу Adventure Time. Я зберіг 11 WAV-файлів (один для кожного епізоду) в субdirectory adv_time.
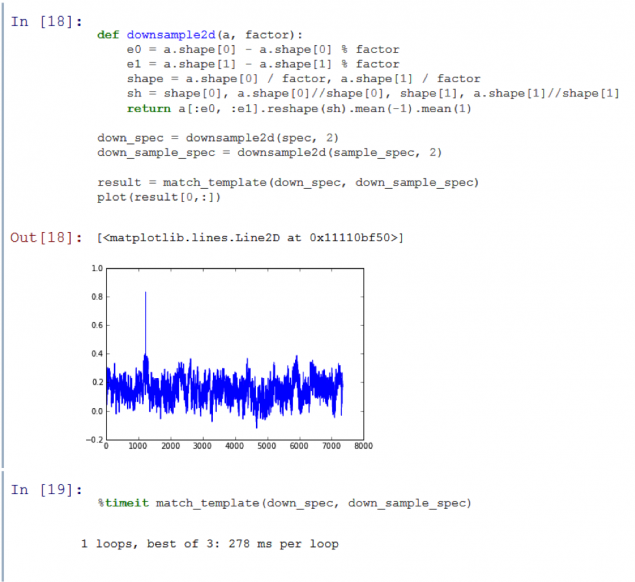
На графіку вийшов пік! Функція матчу_template визначає, що підсамбль був частиною оригінальної аудіо доріжки. Тим не менш, алгоритм порівняння приймав 20 секунд, що занадто довго. Щоб прискорити його, потрібно втратити деякі дані.
Чоловік назвав Гаррі Некількість, що найвища частота, яку ми можемо надійно визначити, це половина швидкості відбору.

Частота вибірки 44.1 кГц означає, що ми можемо визначити звукові частоти до 22 кГц. Це досить достатньо, так як вухо людини сприймає частоту всього 20 кГц.
Однак спектрограма вище показує, що майже всі дані, які ми зацікавлені в тому, що це в верхній половині, а найбільша кількість знаходиться в верхній восьмий. Здається, що область корисної інформації, що міститься на звуковому доріжку Часу Пригоди навіть не приєднується до верхньої межі сприйняття людини. Це означає, що ми можемо перезапустити на крок 8 без втрати занадто важливої інформації.
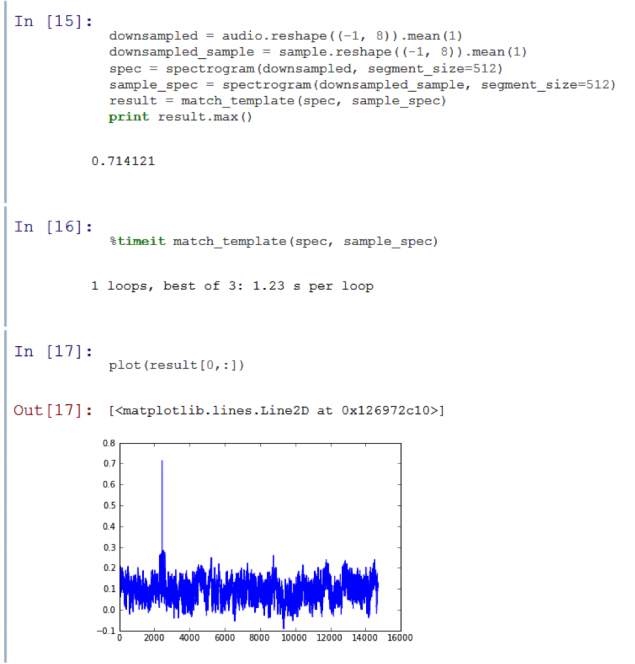
Багато кращих. Підсумки прискорили функцію фактором 15, при цьому все ще виробляють чіткий сигнал від рівня шуму навколишнього середовища 71%. Тим не менш, я хочу прискорити обробку навіть далі, відрізаючи назад на кількість даних. Якщо ми знову підберемо час, ми починаємо втратити важливі високочастотні дані. Але можна квантізувати.
Ми отримали 4x прискорення ще раз, зберігаючи гарне співвідношення сигналу! Дуже задоволена швидкістю алгоритму. Тепер я можу порівняти п'ятисекундний зразок до двогодинної аудіо доріжки менше другого. Але є один останній тест зліва. На даний момент ми використовуємо підпамки, які ріжуться з записів бази даних. Хочу зрозуміти, чи працює алгоритм з зразками, записаними за допомогою мікрофона.
Результат експерименту представлений після нижче коду. По-перше, я підготував аудіо доріжки для кожного епізоду і зберіг їх в каталозі магазину. Я потім використовував pyaudio на моєму ноутбуці, щоб записувати звук Часу пригоди від телевізора.
 р.
р.
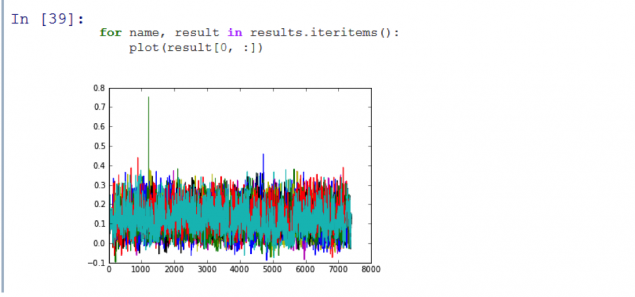
Працює! Як бачите, отриманий графік показує пік, що означає, що програма правильно визнана першим епізодом сезону. Код I писав вдалося визначити перші з 11 епізодів Часу пригод з достатньою точністю і менше 3 секунд.
Я змогла використовувати алгоритми обробки зображень за звичним обсягом. Я змогла створити працездатну програму, яка розпізнає аудіозаписи. Не може бути реалізований найкращим чином (Я впевнений, що Shazaam використовує більш ефективний алгоритм), але він залишив мене кількома приємними враженнями. Я спробував інші методи, які використовують порівняння масок, такі як модуляція Corner і SURF (див. github), але класичний підхід був найбільш зрозумілим. Подальша робота може зосередитися на вивченні інших методів.
Я не пишу чистий код, який використовує комп'ютерну пам'ять, і я думаю, що ви можете squeeze набагато більше продуктивності з нього. На додаток до проблем пам'яті, ці алгоритми мають багато проблем для вирішення – я не витрачав багато часу оптимізації. Подальша робота може розкрити красу підводного плавання в часі і частоті. Я також хотів би експериментувати з довжиною зразка і підзуванням.
Я хотів би перевірити надійність цього алгоритму в роботі з різними аудіо джерелами. Я не прив'язував до певного типу звуку, але він міг руйнувати все, заглуши в іншому джерело звуку.
Всі коди доступні на github.
Джерело: geektimes.ru/company/audiomania/blog/251144/























Як інтернет не працює - жовті сторінки замість сучасного інструменту
Poor Californians Отримати безкоштовні сонячні панелі