3233
Визначення кількості: до 9
Вже кілька разів на Хабре обговорювалися питання про те, як працює розпізнавання номерів. Але не було статей, що демонструють різні підходи до визначення кількості на Habre. Так ми спробуємо розібратися, як це все працює. А потім, якщо стаття викликає інтерес, ми продовжуємо і викладаємо робочу модель, яку можна вивчити.

Одним з ключових параметрів створення системи розпізнавання є залізо, що використовується для фотографії. Чим більш потужна і краща система освітлення, тим краще камера, тим більше шансів дізнатися кількість. Хороший інфрачервоний (IR) точковий світильник може висвітлювати навіть пил і бруду, доступні на кімнаті, закріпити всі фактори інтерферизації. Я думаю, що хтось отримав подібну «віддачу щастя», де можна побачити нічого, але номер.

Чим краще знімальна система, тим надійніше результат. Кращий алгоритм без хорошої системи зйомки: ви завжди можете знайти номер, який не визнається. Ось два дуже різні постріли:
 Р
Р
У цій статті розглядається програмна частина, і акцент поміщається саме на випадок, коли число помітно погано і при спотворенні (просто знімається з рук будь-якої камери).
Алгоритм структура • Попередній пошук номеру Знаходження ділянки, в якій міститься кількість
• Нормалізація кількості Визначення точних меж приміщення, нормалізація констрасті
• Визнання тексту Прочитати все в нормалізації зображення
Це базова структура. Звісно, в ситуації, де кількість знаходиться лінійно і добре освітлено, і у вас є відмінний алгоритм розпізнавання тексту у вашому розпорядженні, зникнуть перші дві точки. Деякі алгоритми можуть поєднувати пошук і нормалізацію номеру.
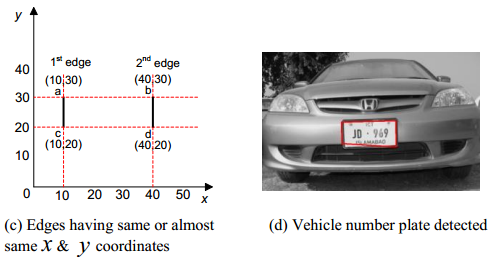
Частина 1: алгоритми попереднього пошуку Аналіз меж і форм, контурний аналіз Найбільш очевидним способом виділити число є пошук прямокутного контуру. Працює тільки в ситуаціях, де є чіткий читальний контур, ненав'язаний, з досить високою роздільною здатністю і з плоским кордоном.

Знімок фільтрується, щоб знайти межі, після чого виділяються всі знайдені контури. Практично всі студентські роботи з обробкою зображень Веб-сайт Погано працює, але якось.
Більш цікавим, стійким і більш практичним є підхід, де проаналізовано лише частина його з рами. Виділяють контури, після чого всі вертикальні лінії. Для будь-яких двох ліній, розташованих в безпосередній близькості один до одного, з невеликим зсувом вздовж осі, з правильним співвідношенням відстані між ними до їх довжини, розглянуто гіпотезу, що число знаходиться між ними. Насправді цей підхід схожий на спрощений метод HOG.
 Р
Р
Одним з найпопулярніших методів підходу є аналіз гістограм образу (1,2). Підхід ґрунтується на припущення, що частота характерна для регіону з числом відрізняється від частоти, характерних для навколишнього середовища.


Зображення висвітлює межі (високочастотні просторові компоненти зображення). Зображення проводиться на осі я (разом на осі x). Максимальний проекція, отримана може збігатися з розташуванням приміщення.
Даний підхід має значний недолік – машина повинна бути порівняна за розміром до розміру рами, так як фон може містити написи або інші деталі.
Які недоліки всіх попередніх методів? Справа в тому, що на реальних, брудних числах немає виражених меж, не виражених статистичних даних. Нижче наведено кілька прикладів цих чисел. Для Москви такі приклади не найгірші варіанти.


Найкращі методи, хоча не зазвичай використовуються, є на основі різних класифікаторів. Наприклад, добре працює каскад Хаар. Ці методи дозволяють аналізувати площу для наявності відносин, точок або градієнтів, характерних для її кількості. Найкрасивіший метод, здається, мені бути одним на основі спеціально синтезованої трансформації. Я не спробував, але на перший погляд він повинен працювати.
Такі методи дозволяють знайти не тільки номер, але і ряд у складних і нетипових умовах. Так само Хаар каскад для основи, зібраної взимку в центрі Москви, виготовили близько 90% правильних виявів кількості і 2-3% від помилкового захоплення. Неповторний алгоритм виявлення або йоготограма може виробляти таку якість виявлення з таких бідних зображень.
Багато методів в реальних алгоритмах прямо або непрямо на наявність кількості меж. Навіть якщо межі не використовуються при виявленні кількості, їх можна використовувати в подальшому аналізі.
Несподівано, для статистичних алгоритмів, навіть порівняно чистий номер в хромі (світло) каркас на білій машині може бути складний випадок, так як він набагато рідше, ніж брудні числа і може не зустрітися досить часу під час тренувань.
Частина 2: алгоритми нормалізації Більшість вищевказаних алгоритмів не виявляти номер точно і вимагають подальшого уточнення його положення, а також покращення якості зображення. Наприклад, в такому випадку потрібно перевернути і обрізати краю:

Коли залишилося тільки райони приміщення, виділення кордонів починає працювати набагато краще, так як всі довгі горизонтальні лінії, які змогли виділитися межі приміщення.
Найлегший фільтр, здатний виділити такі прямі лінії, є Хіба трансформація:
3250Р. 3700Р.
Перетворення Huff дозволяє швидко ідентифікувати дві основні лінії і обрізати зображення на них:

Краще вдосконалити контрастність отриманого зображення в одному або іншому вигляді. Строго кажучи, нам необхідно зміцнити площу просторових частот інтересу до нас:

Після повороту ми маємо горизонтальний номер з неточними лівими і правими краями. Точно відрізати зайвий зараз не потрібно, досить просто вирізати листи в кімнаті і працювати при розпізнаванні їх.
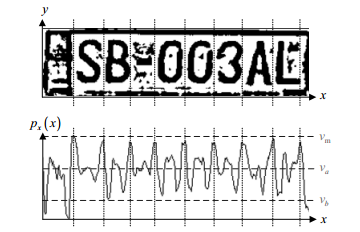
(Ринок вже здійснено бінарну операцію, тобто використовується деяке правило для поділу пікселів на два класи. При поділі кількості в символи ця операція не при необхідності, а в подальшому може бути шкідливим.
Тепер досить знайти максимуми горизонтальної діаграми, це буде інтервали в буквах. Якщо ми очікуємо певну кількість символів і відстань між знаками буде приблизно однаково, то розділення в листи гістограмою буде чудово працювати.
Залишилося лише вирізати наявні листи і перейти в процедуру їх визнання.
При значному забрудненні приміщення періодичні максимуми при поділі на символи можуть просто не з'являтися, хоча самі символи можуть бути візуально зрозумілими.
Горизонтальний кордон приміщення не завжди хороший довідник. Номери можуть бути вигнуті в звичайному режимі (Mercedes C-Class), можуть бути ретельно переглянуті в недорогому майже квадратному триманні для номерів на американських автомобілях. І верхня межа задньої кімнати просто часто покривається елементами тіла.
Природно, врахувати всі такі проблеми – завдання для серйозних систем розпізнавання номерів.
Частина 3: Алгоритми розпізнавання символів Завдання розпізнавання тексту або окремих символів (OCR) є складним на одній руці, і досить класним з іншого. Є багато алгоритмів для його вирішення, деякі з яких досягали досконалості. Але, з іншого боку, кращі алгоритми відкритого доступу. Є, звичайно, Tesseract OCR і кілька його аналогів, але ці алгоритми не вирішують всі проблеми. В цілому методи розпізнавання тексту можна розділити на два класи: структурні методи на основі морфології та контурного аналізу, що виникають з бінарним зображенням, а методи растрових досліджень на основі прямого аналізу зображень. Часто використовується поєднання структурних і растрових методів.
По-перше, в будь-якому випадку в Росії використовується стандартний шрифт. Це просто подарунок для системи автоматичного розпізнавання знаків. 90% зусиль ОКР витрачаються на рукописний текст.
По-друге, бруд.
857754
Саме там, де ви повинні відкинути величезну більшість відомих методів розпізнавання персонажів, особливо якщо по дорозі зображення незрівняно для перевірки з'єднання зон, поділу символів.
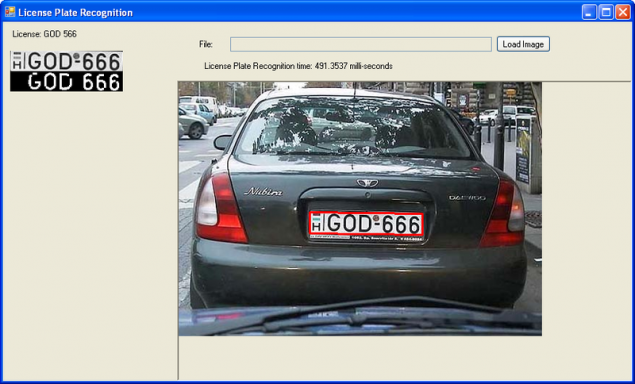
Tesseract OCR є відкритим вихідним програмним забезпеченням, яке автоматично визнає як єдиний лист, так і текст. Tesseract зручний для будь-якої ОС, стабільної та легкої поїздки. Але він дуже погано працює з розмитим, зламаним, брудним і деформованим текстом. Коли я спробував зробити розпізнавання номеру на ньому лише 20-30% номерів в базі даних. Найчистіший і простий. Хоча, звичайно, при використанні готових бібліотек, щось залежить від радіуса викривлення рук.
K-nearest - це дуже простий спосіб розпізнавання персонажа, який, незважаючи на його примітивність, може часто перемогти не найуспішніші впровадження SVM або нейромережних методів.
Працює таким чином:
1) попередньо запишіть пристойну кількість зображень реальних символів вже коректно розділити на заняття своїми очима і руками.
2) ввести захід відстані між символами (якщо зображення є бінарним, то операцію XOR буде оптимальним)
(3) Потім, коли ми намагаємося розпізнати символ, ми по черзі розраховуємо відстань між ним і усіма символами в базі даних. Серед найближчих сусідів можуть бути члени різних класів. Звісно, представники якого класу більше серед сусідів, впізнаваний символ слід віднести до цього класу.
У теорії, якщо ви пишете дуже велику базу даних з прикладами символів, знятих з різних кутів, освітлення, з усіма можливими манжетами, то K-nearest все необхідне. Але потім потрібно розрахувати відстань між зображеннями дуже швидко, і, отже, перезбавити його і використовувати XOR. Але потім це в разі забруднених або рубцевих кімнат, які будуть проблеми. Бінаризація змінює символ непередбачуваним.
Метод має одну дуже важливу перевагу: він простий і прозорий, що означає, що його легко відхиляти і регулювати до оптимального результату. У багатьох випадках важливо розуміти, як працює алгоритм.
Нерідко методи, які використовуються в розпізнавання образів, будуються на емпіричних підходах. Але ніхто не забороняє використання математичного апарату теорії ймовірностей, що було просто поліровано в задачах виявлення сигналів в радіолокаційні системи. Ми знаємо шрифт на автомобільному номері, шум камери або пилу на кімнаті можна назвати Гаусаном. Є деякі невизначеності про розташування символу і його нахилу, але ці параметри можуть бути перевидані. Якщо ми залишаємо зображення незрівняним, ми ще не знаємо амплітуду сигналу, тобто яскравість символу.
Я не хочу потрапити в суворе рішення цієї проблеми в рамках статті. По суті, все зводиться до операції обчислення коефіцієнта вхідного сигналу з гіпотетичним (з урахуванням наданих зміщень і перетворень):
X - вхідний сигнал, Y - гіпотеза. Е є математичним очікуванням.
Якщо необхідно вибрати з різних символів, то для кожного символу будуються гіпотези для обертання і зміщення. Якщо ми знаємо напевно, що вхідний образ містить символ, максимальне співвідношення всіх гіпотез дозволить визначити символ, його зміщення і нахил. Ось, звичайно, є проблема близькість зображень різних символів ("p" і "c", "o" і "c", і т.д.). Найпростіше ввести вагову матрицю коефіцієнтів для кожного символу.
Іноді ці методи називають шаблоном, що повністю відображає їх сутність. Встановити зразки - порівняти вхідне зображення з зразками. Якщо існує деяка невизначеність на параметрах, то або ми йдемо через всі можливі варіанти, або ми використовуємо адаптивні підходи, хоча тут ви повинні знати і розуміти математику.
Переваги методу:
Точні і добре продумані результати, якщо шум навіть трохи відповідає обраній моделі.
Якщо шрифт встановлюється строго, як і в нашому випадку він здатний бачити сильно пилососний / брудний / синовий символ.
Недоліки:
- розрахунок вартості.
Неуралні мережі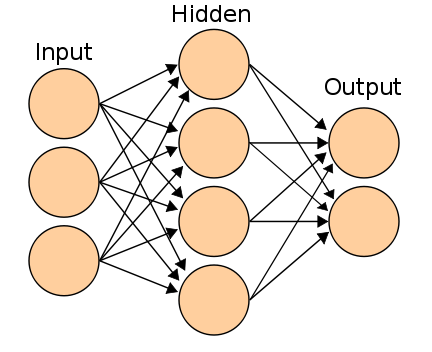
Багато вже написано про штучні нейромережі на Хабра. Зараз діляться на два покоління:
Класичні 2-3-шарові нейромережі, які навчаються градієнтовними методами з запобіжністю помилок (3-шарова нейромережа зображена на малюнку);
Поглиблені нейромережі та зв’язані мережі.
Друге покоління нейромереж за останні 7 років виграло різні змагання з розпізнавання зображень, що дає результат трохи краще, ніж інші методи.
Є відкриті бази даних рукописних цифр. У таблиці результатів дуже чітко продемонстровано еволюцію різних методів, зокрема алгоритмів на основі нейромереж.
Також варто відзначити, що для друкованих шрифтів, найпростіша одношарова або двошарова (питання термінології) мережа працює ідеально, що в сутності не відрізняється від шаблонно-знімних підходів.
Переваги методу:
З правильним навчанням та навчанням, це може працювати краще, ніж інші відомі методи.
З великим навчальним масивом даних стійкий до спотворення символів.
Недоліки:
найскладніші для описаних методів;
Діагностика аномальної поведінки в багатошарових мережах просто неможливо.
У статті розглянуто основні методи розпізнавання, характерні риси та помилки. Можливо, це допоможе вам зробити номер трохи більш читабельним при подорожі по місту або навпаки.
Я також сподіваюся показати, що немає магії в задачі розпізнавання номерів. Все зрозуміло і інтуїтивно зрозуміле. Це абсолютно не страшне завдання для курсової роботи студента за відповідною спеціальністю.
І в кілька днів ЗлодійБаал виведе невелике число визнання, на основі нашої роботи, на якій написано цю статтю. Вона може бути катування.
З.С. Усі номери у статті отримані з Google та Yandex за допомогою простих запитів.
АЛГОРИТИЧНІ ТА МАТЕМАТИЧНІ ПРИНЦИПИ АВТОМАТИЧНОЇ СИСТЕМИ ПЛАТЕЗУВАННЯ ПЛАТЕГНІЮ ОНДРІЙ МАРТИНСЬКИЙ.
(2) Реал-час Мобільний транспортний розв'язок та розпізнавання Kuo-Ming Hung та Ching-Tang Hsieh
(3) Виявлення робочої пластини з використанням коваріаційного дескриптора в рамці Неурал Мережа Fatih Porikli, Tekin Kocak
(4) Автоматичне розпізнавання номерної пластини з використанням Hough Lines і шаблонів Saqib Rasheed, Asad Naeem і Omer Ishaq - пошук номерів через HOG вертикальні лінії дескриптори
(5) Огляд методів розпізнавання символів Сулухі Г. Дєгаонкар, Алялі А. Шандавал, Ашок М. Сапкал – коротка стаття огляду на букові та цифри розпізнавання
7) Навчальний посібник "Базова теорія обробки зображень", Крашенніков В. Р.
Джерело: habrahabr.ru/post/221891/

Одним з ключових параметрів створення системи розпізнавання є залізо, що використовується для фотографії. Чим більш потужна і краща система освітлення, тим краще камера, тим більше шансів дізнатися кількість. Хороший інфрачервоний (IR) точковий світильник може висвітлювати навіть пил і бруду, доступні на кімнаті, закріпити всі фактори інтерферизації. Я думаю, що хтось отримав подібну «віддачу щастя», де можна побачити нічого, але номер.

Чим краще знімальна система, тим надійніше результат. Кращий алгоритм без хорошої системи зйомки: ви завжди можете знайти номер, який не визнається. Ось два дуже різні постріли:
 Р
РУ цій статті розглядається програмна частина, і акцент поміщається саме на випадок, коли число помітно погано і при спотворенні (просто знімається з рук будь-якої камери).
Алгоритм структура • Попередній пошук номеру Знаходження ділянки, в якій міститься кількість
• Нормалізація кількості Визначення точних меж приміщення, нормалізація констрасті
• Визнання тексту Прочитати все в нормалізації зображення
Це базова структура. Звісно, в ситуації, де кількість знаходиться лінійно і добре освітлено, і у вас є відмінний алгоритм розпізнавання тексту у вашому розпорядженні, зникнуть перші дві точки. Деякі алгоритми можуть поєднувати пошук і нормалізацію номеру.
Частина 1: алгоритми попереднього пошуку Аналіз меж і форм, контурний аналіз Найбільш очевидним способом виділити число є пошук прямокутного контуру. Працює тільки в ситуаціях, де є чіткий читальний контур, ненав'язаний, з досить високою роздільною здатністю і з плоским кордоном.


Знімок фільтрується, щоб знайти межі, після чого виділяються всі знайдені контури. Практично всі студентські роботи з обробкою зображень Веб-сайт Погано працює, але якось.
Більш цікавим, стійким і більш практичним є підхід, де проаналізовано лише частина його з рами. Виділяють контури, після чого всі вертикальні лінії. Для будь-яких двох ліній, розташованих в безпосередній близькості один до одного, з невеликим зсувом вздовж осі, з правильним співвідношенням відстані між ними до їх довжини, розглянуто гіпотезу, що число знаходиться між ними. Насправді цей підхід схожий на спрощений метод HOG.
 Р
РОдним з найпопулярніших методів підходу є аналіз гістограм образу (1,2). Підхід ґрунтується на припущення, що частота характерна для регіону з числом відрізняється від частоти, характерних для навколишнього середовища.


Зображення висвітлює межі (високочастотні просторові компоненти зображення). Зображення проводиться на осі я (разом на осі x). Максимальний проекція, отримана може збігатися з розташуванням приміщення.
Даний підхід має значний недолік – машина повинна бути порівняна за розміром до розміру рами, так як фон може містити написи або інші деталі.
Які недоліки всіх попередніх методів? Справа в тому, що на реальних, брудних числах немає виражених меж, не виражених статистичних даних. Нижче наведено кілька прикладів цих чисел. Для Москви такі приклади не найгірші варіанти.


Найкращі методи, хоча не зазвичай використовуються, є на основі різних класифікаторів. Наприклад, добре працює каскад Хаар. Ці методи дозволяють аналізувати площу для наявності відносин, точок або градієнтів, характерних для її кількості. Найкрасивіший метод, здається, мені бути одним на основі спеціально синтезованої трансформації. Я не спробував, але на перший погляд він повинен працювати.
Такі методи дозволяють знайти не тільки номер, але і ряд у складних і нетипових умовах. Так само Хаар каскад для основи, зібраної взимку в центрі Москви, виготовили близько 90% правильних виявів кількості і 2-3% від помилкового захоплення. Неповторний алгоритм виявлення або йоготограма може виробляти таку якість виявлення з таких бідних зображень.
Багато методів в реальних алгоритмах прямо або непрямо на наявність кількості меж. Навіть якщо межі не використовуються при виявленні кількості, їх можна використовувати в подальшому аналізі.
Несподівано, для статистичних алгоритмів, навіть порівняно чистий номер в хромі (світло) каркас на білій машині може бути складний випадок, так як він набагато рідше, ніж брудні числа і може не зустрітися досить часу під час тренувань.
Частина 2: алгоритми нормалізації Більшість вищевказаних алгоритмів не виявляти номер точно і вимагають подальшого уточнення його положення, а також покращення якості зображення. Наприклад, в такому випадку потрібно перевернути і обрізати краю:

Коли залишилося тільки райони приміщення, виділення кордонів починає працювати набагато краще, так як всі довгі горизонтальні лінії, які змогли виділитися межі приміщення.
Найлегший фільтр, здатний виділити такі прямі лінії, є Хіба трансформація:
3250Р. 3700Р.
Перетворення Huff дозволяє швидко ідентифікувати дві основні лінії і обрізати зображення на них:

Краще вдосконалити контрастність отриманого зображення в одному або іншому вигляді. Строго кажучи, нам необхідно зміцнити площу просторових частот інтересу до нас:

Після повороту ми маємо горизонтальний номер з неточними лівими і правими краями. Точно відрізати зайвий зараз не потрібно, досить просто вирізати листи в кімнаті і працювати при розпізнаванні їх.

(Ринок вже здійснено бінарну операцію, тобто використовується деяке правило для поділу пікселів на два класи. При поділі кількості в символи ця операція не при необхідності, а в подальшому може бути шкідливим.
Тепер досить знайти максимуми горизонтальної діаграми, це буде інтервали в буквах. Якщо ми очікуємо певну кількість символів і відстань між знаками буде приблизно однаково, то розділення в листи гістограмою буде чудово працювати.
Залишилося лише вирізати наявні листи і перейти в процедуру їх визнання.
При значному забрудненні приміщення періодичні максимуми при поділі на символи можуть просто не з'являтися, хоча самі символи можуть бути візуально зрозумілими.
Горизонтальний кордон приміщення не завжди хороший довідник. Номери можуть бути вигнуті в звичайному режимі (Mercedes C-Class), можуть бути ретельно переглянуті в недорогому майже квадратному триманні для номерів на американських автомобілях. І верхня межа задньої кімнати просто часто покривається елементами тіла.
Природно, врахувати всі такі проблеми – завдання для серйозних систем розпізнавання номерів.
Частина 3: Алгоритми розпізнавання символів Завдання розпізнавання тексту або окремих символів (OCR) є складним на одній руці, і досить класним з іншого. Є багато алгоритмів для його вирішення, деякі з яких досягали досконалості. Але, з іншого боку, кращі алгоритми відкритого доступу. Є, звичайно, Tesseract OCR і кілька його аналогів, але ці алгоритми не вирішують всі проблеми. В цілому методи розпізнавання тексту можна розділити на два класи: структурні методи на основі морфології та контурного аналізу, що виникають з бінарним зображенням, а методи растрових досліджень на основі прямого аналізу зображень. Часто використовується поєднання структурних і растрових методів.
По-перше, в будь-якому випадку в Росії використовується стандартний шрифт. Це просто подарунок для системи автоматичного розпізнавання знаків. 90% зусиль ОКР витрачаються на рукописний текст.
По-друге, бруд.
857754
Саме там, де ви повинні відкинути величезну більшість відомих методів розпізнавання персонажів, особливо якщо по дорозі зображення незрівняно для перевірки з'єднання зон, поділу символів.
Tesseract OCR є відкритим вихідним програмним забезпеченням, яке автоматично визнає як єдиний лист, так і текст. Tesseract зручний для будь-якої ОС, стабільної та легкої поїздки. Але він дуже погано працює з розмитим, зламаним, брудним і деформованим текстом. Коли я спробував зробити розпізнавання номеру на ньому лише 20-30% номерів в базі даних. Найчистіший і простий. Хоча, звичайно, при використанні готових бібліотек, щось залежить від радіуса викривлення рук.
K-nearest - це дуже простий спосіб розпізнавання персонажа, який, незважаючи на його примітивність, може часто перемогти не найуспішніші впровадження SVM або нейромережних методів.
Працює таким чином:
1) попередньо запишіть пристойну кількість зображень реальних символів вже коректно розділити на заняття своїми очима і руками.
2) ввести захід відстані між символами (якщо зображення є бінарним, то операцію XOR буде оптимальним)
(3) Потім, коли ми намагаємося розпізнати символ, ми по черзі розраховуємо відстань між ним і усіма символами в базі даних. Серед найближчих сусідів можуть бути члени різних класів. Звісно, представники якого класу більше серед сусідів, впізнаваний символ слід віднести до цього класу.
У теорії, якщо ви пишете дуже велику базу даних з прикладами символів, знятих з різних кутів, освітлення, з усіма можливими манжетами, то K-nearest все необхідне. Але потім потрібно розрахувати відстань між зображеннями дуже швидко, і, отже, перезбавити його і використовувати XOR. Але потім це в разі забруднених або рубцевих кімнат, які будуть проблеми. Бінаризація змінює символ непередбачуваним.
Метод має одну дуже важливу перевагу: він простий і прозорий, що означає, що його легко відхиляти і регулювати до оптимального результату. У багатьох випадках важливо розуміти, як працює алгоритм.
Нерідко методи, які використовуються в розпізнавання образів, будуються на емпіричних підходах. Але ніхто не забороняє використання математичного апарату теорії ймовірностей, що було просто поліровано в задачах виявлення сигналів в радіолокаційні системи. Ми знаємо шрифт на автомобільному номері, шум камери або пилу на кімнаті можна назвати Гаусаном. Є деякі невизначеності про розташування символу і його нахилу, але ці параметри можуть бути перевидані. Якщо ми залишаємо зображення незрівняним, ми ще не знаємо амплітуду сигналу, тобто яскравість символу.
Я не хочу потрапити в суворе рішення цієї проблеми в рамках статті. По суті, все зводиться до операції обчислення коефіцієнта вхідного сигналу з гіпотетичним (з урахуванням наданих зміщень і перетворень):
X - вхідний сигнал, Y - гіпотеза. Е є математичним очікуванням.
Якщо необхідно вибрати з різних символів, то для кожного символу будуються гіпотези для обертання і зміщення. Якщо ми знаємо напевно, що вхідний образ містить символ, максимальне співвідношення всіх гіпотез дозволить визначити символ, його зміщення і нахил. Ось, звичайно, є проблема близькість зображень різних символів ("p" і "c", "o" і "c", і т.д.). Найпростіше ввести вагову матрицю коефіцієнтів для кожного символу.
Іноді ці методи називають шаблоном, що повністю відображає їх сутність. Встановити зразки - порівняти вхідне зображення з зразками. Якщо існує деяка невизначеність на параметрах, то або ми йдемо через всі можливі варіанти, або ми використовуємо адаптивні підходи, хоча тут ви повинні знати і розуміти математику.
Переваги методу:
Точні і добре продумані результати, якщо шум навіть трохи відповідає обраній моделі.
Якщо шрифт встановлюється строго, як і в нашому випадку він здатний бачити сильно пилососний / брудний / синовий символ.
Недоліки:
- розрахунок вартості.
Неуралні мережі

Багато вже написано про штучні нейромережі на Хабра. Зараз діляться на два покоління:
Класичні 2-3-шарові нейромережі, які навчаються градієнтовними методами з запобіжністю помилок (3-шарова нейромережа зображена на малюнку);
Поглиблені нейромережі та зв’язані мережі.
Друге покоління нейромереж за останні 7 років виграло різні змагання з розпізнавання зображень, що дає результат трохи краще, ніж інші методи.
Є відкриті бази даних рукописних цифр. У таблиці результатів дуже чітко продемонстровано еволюцію різних методів, зокрема алгоритмів на основі нейромереж.
Також варто відзначити, що для друкованих шрифтів, найпростіша одношарова або двошарова (питання термінології) мережа працює ідеально, що в сутності не відрізняється від шаблонно-знімних підходів.
Переваги методу:
З правильним навчанням та навчанням, це може працювати краще, ніж інші відомі методи.
З великим навчальним масивом даних стійкий до спотворення символів.
Недоліки:
найскладніші для описаних методів;
Діагностика аномальної поведінки в багатошарових мережах просто неможливо.
У статті розглянуто основні методи розпізнавання, характерні риси та помилки. Можливо, це допоможе вам зробити номер трохи більш читабельним при подорожі по місту або навпаки.
Я також сподіваюся показати, що немає магії в задачі розпізнавання номерів. Все зрозуміло і інтуїтивно зрозуміле. Це абсолютно не страшне завдання для курсової роботи студента за відповідною спеціальністю.
І в кілька днів ЗлодійБаал виведе невелике число визнання, на основі нашої роботи, на якій написано цю статтю. Вона може бути катування.
З.С. Усі номери у статті отримані з Google та Yandex за допомогою простих запитів.
АЛГОРИТИЧНІ ТА МАТЕМАТИЧНІ ПРИНЦИПИ АВТОМАТИЧНОЇ СИСТЕМИ ПЛАТЕЗУВАННЯ ПЛАТЕГНІЮ ОНДРІЙ МАРТИНСЬКИЙ.
(2) Реал-час Мобільний транспортний розв'язок та розпізнавання Kuo-Ming Hung та Ching-Tang Hsieh
(3) Виявлення робочої пластини з використанням коваріаційного дескриптора в рамці Неурал Мережа Fatih Porikli, Tekin Kocak
(4) Автоматичне розпізнавання номерної пластини з використанням Hough Lines і шаблонів Saqib Rasheed, Asad Naeem і Omer Ishaq - пошук номерів через HOG вертикальні лінії дескриптори
(5) Огляд методів розпізнавання символів Сулухі Г. Дєгаонкар, Алялі А. Шандавал, Ашок М. Сапкал – коротка стаття огляду на букові та цифри розпізнавання
7) Навчальний посібник "Базова теорія обробки зображень", Крашенніков В. Р.
Джерело: habrahabr.ru/post/221891/