3230
Reconocimiento de habitaciones: de A a 9
Ya un par de veces en el Habré surgió una discusión sobre la manera de reconocer los números ahora trabaja. Pero el artículo, que muestran diferentes enfoques para el reconocimiento de los números, hasta que Habré no lo era. Así que aquí vamos a tratar de entender cómo funciona todo. Y luego, si el artículo será de interés, y seguirá publicando un modelo de trabajo que pueden ser poissledovat.

Software VS Hierro h4> Uno de los parámetros clave para el establecimiento de un sistema de reconocimiento - de hierro utilizado para la fotografía. El sistema de iluminación más potente y mejor, mejor es la cámara, más probable para reconocer el número. Buena infrarrojos (IR) Iluminador puede iluminar incluso el polvo y la suciedad que se encuentra disponible en la habitación, eclipsar a todos los factores de confusión. Creo que alguien llegó similares "cartas en cadena", que además de la sala no puede ver nada.
La estructura del algoritmo h4> • Búsqueda Avanzada - área de detección que contiene un número
Análisis de las fronteras y formas, el análisis del contorno h5> El método más obvio de salas de aislamiento - encontrar un contorno rectangular. Funciona sólo en situaciones en las que hay un esquema claramente legible no vallada, con lo suficientemente alta resolución y con un límite suave.
El análisis de sólo una parte de las fronteras h5> Mucho más interesante, más estable y un enfoque más práctico parece , donde el ámbito de los análisis sólo parte de ella. Contornos resaltados y luego buscaron todas las líneas verticales. Para cualquier par de líneas situadas cerca uno del otro, con un ligero cambio a lo largo del eje y, con la proporción correcta de la distancia entre ellos a su longitud, una hipótesis que es espacio entre ellos. De hecho, este enfoque es similar al método simplificado HOG .
análisis del histograma de las regiones h5> Uno de los métodos más populares de enfoque es el análisis del histograma de la imagen ( 1 , 2 ). El enfoque se basa en la suposición de que la característica de frecuencia de la región con un número diferente de la respuesta de frecuencia de la vecindad.
Análisis estadístico, clasificadores h5> ¿Qué es menos todos los métodos anteriores? El hecho de que en lo real, manchado de barro habitaciones expresó hay fronteras, no hay estadísticas pronunciadas. Desde abajo muestra algunos ejemplos de tales números. Y tengo que decir, para Moscú, tales ejemplos no son la peor opción.
El punto de h5> débil Muchos métodos de algoritmos reales están directamente o indirectamente basa en la presencia de los límites de la habitación. Incluso si los límites no se utilizan para la detección de la habitación, que puede ser utilizado para un análisis adicional.
Parte 2: algoritmos de normalización h4> La mayor parte de la serie de exposiciones por encima de los algoritmos no es exacta y requiere una mayor clarificación de su posición, y la mejora de la calidad de la imagen. Por ejemplo, en este caso requiere la rotación y recorte de los bordes:
Números de rotación en una orientación horizontal h5> cuando se le deja solo habitaciones vecinales, límites de aislamiento empieza a funcionar mucho mejor, ya que todas las líneas horizontales de largo, que lograron extraer - esta será la frontera de la habitación.
Incrementar el contraste h5> Y la mejor manera o la otra para mejorar el contraste de la imagen resultante. En sentido estricto, es necesario reforzar la región de interés de frecuencias espaciales:
La partición en las letras h5> Después de la rotación, tenemos una sala con unas horizontales bordes izquierdo y derecho definitivas inexactas. Precisamente cortar innecesaria ahora no necesariamente suficiente para cortar simplemente las letras están disponibles en la habitación y trabajar con ellos durante el reconocimiento.
Debilidades h5> con un número significativo picos de contaminación periódicos en una partición en los símbolos no sólo puede aparecer, aunque los personajes pueden ser visualmente muy legible.
Parte 3: algoritmos de reconocimiento de caracteres h4> El problema de reconocimiento de texto o caracteres individuales (reconocimiento óptico de caracteres, OCR), por un lado es difícil, pero por el otro - bastante clásica. Hay muchos algoritmos para resolverlo, algunos de los cuales llegaron a la perfección . Por otro lado, los mejores algoritmos en el dominio público no. Hay, por supuesto Tesseract OCR y varios de sus compañeros, pero estos algoritmos no resuelven todos los problemas. En general, los métodos de reconocimiento de texto se pueden dividir en dos clases: métodos basados en la morfología y el circuito de análisis estructural frente a los métodos de imagen y raster binarizadas basadas en el análisis de la imagen directa. Esto a menudo utiliza una combinación de métodos estructurales y raster
A diferencia de las tareas estándar OCR h5> En primer lugar, en todo caso, en Rusia, el número de coche, un tipo de letra estándar. Es sólo un regalo para el sistema de reconocimiento automático de señales. 90% de los esfuerzos gasta en OCR de escritura a mano.
Tesseract OCR h5> Este es un software de código abierto que realiza el reconocimiento automático como una sola letra y de inmediato texto. Tesseract es conveniente, ya que es, para cualquier sistema operativo se ejecuta de forma estable y fácilmente entrenable. Pero funciona muy mal con zamylennym, roto, sucio texto y deforme. Cuando traté de hacerlo en el reconocimiento de las habitaciones - en la fuerza de sólo 20 a 30% de las habitaciones de la base de datos reconocido correctamente. El más claro y directo. Aunque, por supuesto, y cuando se utilizan bibliotecas de ready-made algo depende del radio de curvatura de las manos.
K-cercano h5> Muy fácil de entender el método de reconocimiento de caracteres, que, a pesar de su primitiva, a menudo no pueden ganar a la aplicación de mayor éxito de SVM o métodos de redes neuronales.
h5 correlación> La mayoría de los métodos que se utilizan en el reconocimiento de imágenes, construidas en un enfoque empírico. Pero nadie prohíbe utilizar el aparato matemático de la teoría de la probabilidad, que acaba de ser pulido en problemas de la detección de la señal en los sistemas de radar. El tipo de letra de los números de automóviles que conocemos, el ruido o el polvo en la sala de la cámara no puede ser llamado un Gauss. Hay un poco de incertidumbre sobre la ubicación del símbolo y su pendiente, pero estos parámetros puede repetir. Si dejamos la imagen se digitalizan, todavía desconocido, y la amplitud de la señal, t E. El brillo del símbolo..
Redes neuronales h5>
Conclusión h4> El artículo describe los métodos básicos de reconocimiento, sus fallos y errores típicos. Tal vez esto le ayudará a hacer de su habitación un poco más legible cuando se viaja por la ciudad, o viceversa.
Referencias h4> 1) Ondrej Martinsky - Artículo de revisión.
»,
Krasheninnikov VR
Fuente: habrahabr.ru/post/221891/

Software VS Hierro h4> Uno de los parámetros clave para el establecimiento de un sistema de reconocimiento - de hierro utilizado para la fotografía. El sistema de iluminación más potente y mejor, mejor es la cámara, más probable para reconocer el número. Buena infrarrojos (IR) Iluminador puede iluminar incluso el polvo y la suciedad que se encuentra disponible en la habitación, eclipsar a todos los factores de confusión. Creo que alguien llegó similares "cartas en cadena", que además de la sala no puede ver nada.

Cuanto mejor sea el sistema de tiro - la fiabilidad de los resultados. Mejor algoritmo sin un buen tiro es inútil: siempre se puede encontrar una habitación que no es reconocido. Aquí hay dos imágenes muy diferentes:

Este artículo aborda exactamente la parte de software, con énfasis está en el caso de que el número se ve mal y distorsionado (sólo filmó "con las manos" de cualquier cámara).


La estructura del algoritmo h4> • Búsqueda Avanzada - área de detección que contiene un número
• número Normalización - la definición de los límites exactos de la habitación, la normalización konstrastom
• OCR - la lectura de todo lo que se encontró en el
imagen normalizada
Esta estructura básica. Por supuesto, en una situación en la que el número de forma lineal situado y bien iluminado, y a su disposición una gran algoritmo de reconocimiento de texto , los dos primeros artículos desaparecer . En algunos algoritmos se pueden combinar búsqueda de número y su normalización.
Parte 1: Algoritmos Búsqueda Avanzada h4>
Análisis de las fronteras y formas, el análisis del contorno h5> El método más obvio de salas de aislamiento - encontrar un contorno rectangular. Funciona sólo en situaciones en las que hay un esquema claramente legible no vallada, con lo suficientemente alta resolución y con un límite suave.

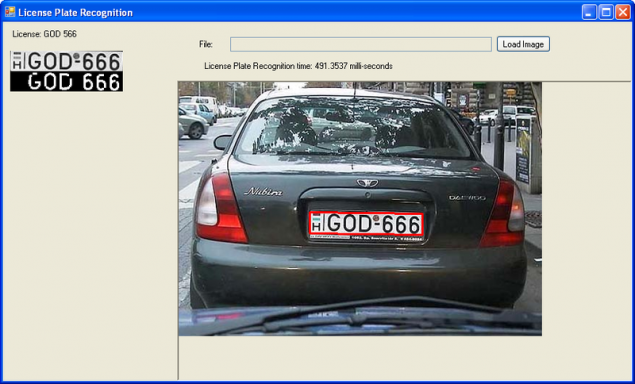
Para filtrar la imagen para encontrar границ entonces asigna todos sus contornos encontrado y análisis . Casi todo el trabajo del estudiante con el procesamiento de imágenes se hace de esta manera. Ejemplos en la completo . Funciona mal, pero de alguna manera.


El análisis de sólo una parte de las fronteras h5> Mucho más interesante, más estable y un enfoque más práctico parece , donde el ámbito de los análisis sólo parte de ella. Contornos resaltados y luego buscaron todas las líneas verticales. Para cualquier par de líneas situadas cerca uno del otro, con un ligero cambio a lo largo del eje y, con la proporción correcta de la distancia entre ellos a su longitud, una hipótesis que es espacio entre ellos. De hecho, este enfoque es similar al método simplificado HOG .
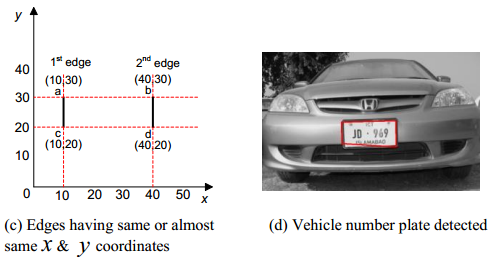

análisis del histograma de las regiones h5> Uno de los métodos más populares de enfoque es el análisis del histograma de la imagen ( 1 , 2 ). El enfoque se basa en la suposición de que la característica de frecuencia de la región con un número diferente de la respuesta de frecuencia de la vecindad.


El borde de la imagen asignada (asignación de componentes de alto espacial de la imagen). Construimos la imagen de proyección en el eje y (a veces en el eje x). Proyección máxima obtenida puede coincidir con la ubicación de la habitación.
Este enfoque tiene un inconveniente importante - la máquina de tamaño debe ser comparable con el tamaño de la trama, es decir, A. Antecedentes puede contener inscripciones u otros objetos detallados..


Análisis estadístico, clasificadores h5> ¿Qué es menos todos los métodos anteriores? El hecho de que en lo real, manchado de barro habitaciones expresó hay fronteras, no hay estadísticas pronunciadas. Desde abajo muestra algunos ejemplos de tales números. Y tengo que decir, para Moscú, tales ejemplos no son la peor opción.


Las mejores prácticas, aunque no con la suficiente frecuencia utilizan, estos métodos basados en diferentes clasificadores. Por ejemplo, funciona bien entrenado Haar cascada . Estos métodos permiten analizar el área de la presencia de sus números característicos de las relaciones, puntos o gradientes. La más bella creo que el método basado en un синтезированном convertir . Es cierto, yo no lo he probado, pero, a primera vista, debería trabajar de manera constante.
Estos métodos permiten encontrar no sólo un número de habitación y un complejo y condiciones atípicas. La misma base de Haar cascada recogido en el invierno en el centro de Moscú dio aproximadamente el 90% de las detecciones correctas habitaciones y 2-3% de falsos captura. Ni las fronteras del algoritmo de detección o histogramas no pueden emitir tanta calidad en la detección de tan mala imagen.


El punto de h5> débil Muchos métodos de algoritmos reales están directamente o indirectamente basa en la presencia de los límites de la habitación. Incluso si los límites no se utilizan para la detección de la habitación, que puede ser utilizado para un análisis adicional.
Sorprendentemente, pero para los algoritmos estadísticos casos complejos puede ser incluso una habitación relativamente limpio en cromo (luz) marco en el coche blanco, ya que se produce con mucha menos frecuencia habitaciones sucias y no puede cumplir con un número suficiente de veces en el entrenamiento.
Parte 2: algoritmos de normalización h4> La mayor parte de la serie de exposiciones por encima de los algoritmos no es exacta y requiere una mayor clarificación de su posición, y la mejora de la calidad de la imagen. Por ejemplo, en este caso requiere la rotación y recorte de los bordes:


Números de rotación en una orientación horizontal h5> cuando se le deja solo habitaciones vecinales, límites de aislamiento empieza a funcionar mucho mejor, ya que todas las líneas horizontales de largo, que lograron extraer - esta será la frontera de la habitación.
El filtro simple es capaz de liberar tales directa - conversión Хафа:

Convertir Huff permite distinguir rápidamente dos líneas principales y recortar la imagen en ellos:



Incrementar el contraste h5> Y la mejor manera o la otra para mejorar el contraste de la imagen resultante. En sentido estricto, es necesario reforzar la región de interés de frecuencias espaciales:


La partición en las letras h5> Después de la rotación, tenemos una sala con unas horizontales bordes izquierdo y derecho definitivas inexactas. Precisamente cortar innecesaria ahora no necesariamente suficiente para cortar simplemente las letras están disponibles en la habitación y trabajar con ellos durante el reconocimiento.
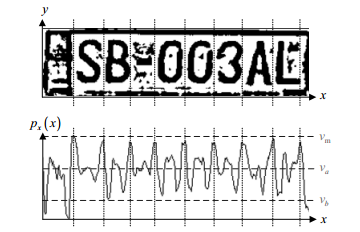
(La cifra ya se ha llevado a cabo una operación de binarización, t. E. Se utiliza una regla de la separación de píxeles en dos clases. En la separación de las habitaciones en los personajes, no es necesaria esta operación, y en el futuro puede resultar perjudicial)
Ahora bien, es suficiente para encontrar las listas de máximos horizontales, y será lagunas letras. Sobre todo si se espera una cierta cantidad de caracteres y la distancia entre las marcas será de aproximadamente el mismo, entonces la partición de las letras en el histograma funcionará perfectamente.
Sólo se puede cortar con la letra y vaya al procedimiento para su identificación.

Debilidades h5> con un número significativo picos de contaminación periódicos en una partición en los símbolos no sólo puede aparecer, aunque los personajes pueden ser visualmente muy legible.
Habitaciones fronteras horizontales - no siempre es un buen punto de referencia. Las habitaciones pueden ser doblados nominalmente (Mercedes Clase C), puede ser hundido cuidadosamente en el hueco equivocado casi cuadrada de la habitación en los coches americanos. Y el límite superior de las habitaciones traseras son sólo una parte del cuerpo está cubierto por los elementos.
Por supuesto, tener en cuenta todos estos problemas - este es un serio problema para un sistema de reconocimiento de números
.
Parte 3: algoritmos de reconocimiento de caracteres h4> El problema de reconocimiento de texto o caracteres individuales (reconocimiento óptico de caracteres, OCR), por un lado es difícil, pero por el otro - bastante clásica. Hay muchos algoritmos para resolverlo, algunos de los cuales llegaron a la perfección . Por otro lado, los mejores algoritmos en el dominio público no. Hay, por supuesto Tesseract OCR y varios de sus compañeros, pero estos algoritmos no resuelven todos los problemas. En general, los métodos de reconocimiento de texto se pueden dividir en dos clases: métodos basados en la morfología y el circuito de análisis estructural frente a los métodos de imagen y raster binarizadas basadas en el análisis de la imagen directa. Esto a menudo utiliza una combinación de métodos estructurales y raster
A diferencia de las tareas estándar OCR h5> En primer lugar, en todo caso, en Rusia, el número de coche, un tipo de letra estándar. Es sólo un regalo para el sistema de reconocimiento automático de señales. 90% de los esfuerzos gasta en OCR de escritura a mano.
En segundo lugar, la suciedad.
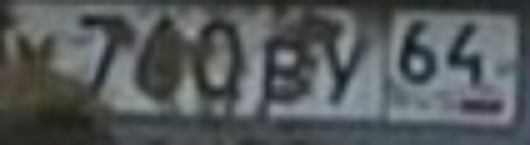
Aquí, pues, hay que lanzar una mayoría absoluta de los métodos conocidos para el reconocimiento de caracteres, sobre todo cuando el camino de la imagen se digitalizan para comprobar la conectividad de las áreas delimitadas.
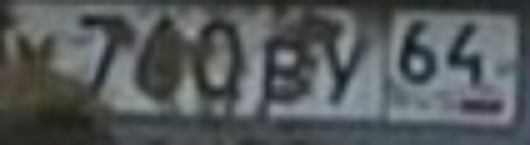
Tesseract OCR h5> Este es un software de código abierto que realiza el reconocimiento automático como una sola letra y de inmediato texto. Tesseract es conveniente, ya que es, para cualquier sistema operativo se ejecuta de forma estable y fácilmente entrenable. Pero funciona muy mal con zamylennym, roto, sucio texto y deforme. Cuando traté de hacerlo en el reconocimiento de las habitaciones - en la fuerza de sólo 20 a 30% de las habitaciones de la base de datos reconocido correctamente. El más claro y directo. Aunque, por supuesto, y cuando se utilizan bibliotecas de ready-made algo depende del radio de curvatura de las manos.
K-cercano h5> Muy fácil de entender el método de reconocimiento de caracteres, que, a pesar de su primitiva, a menudo no pueden ganar a la aplicación de mayor éxito de SVM o métodos de redes neuronales.
Funciona de la siguiente manera:
1) pre-registra una buena cantidad de imágenes reales de los personajes ya divididas correctamente en las clases con sus propios ojos y manos
2) establecer una medida de la distancia entre los símbolos (si la imagen se digitalizan, la operación XOR es óptimo)
3) Luego, cuando tratamos de reconocer el símbolo, a su vez calcula la distancia entre éste y todos los personajes de la base de datos. Entre los k vecinos más cercanos pueden ser representantes de diferentes clases. Naturalmente, los miembros de la clase más entre los vecinos, la clase debe incluir el símbolo reconocible.
En teoría, si escribimos una gran base de datos con ejemplos de personajes desde ángulos diferentes, la iluminación, con todo el roce, el K-más cercano - es todo lo que necesita. Pero entonces usted necesita para calcular rápidamente la distancia entre las imágenes y, por lo tanto, Binarización y su uso XOR. Pero entonces es en el caso de problemas contaminados o habitaciones desgastadas serán. Binarización alterar de manera impredecible el carácter.
El método tiene una ventaja muy importante: es simple y transparente, y por lo tanto fácil de depurar y sintonizar el resultado óptimo. En muchos casos, es importante comprender cómo su algoritmo.
h5 correlación> La mayoría de los métodos que se utilizan en el reconocimiento de imágenes, construidas en un enfoque empírico. Pero nadie prohíbe utilizar el aparato matemático de la teoría de la probabilidad, que acaba de ser pulido en problemas de la detección de la señal en los sistemas de radar. El tipo de letra de los números de automóviles que conocemos, el ruido o el polvo en la sala de la cámara no puede ser llamado un Gauss. Hay un poco de incertidumbre sobre la ubicación del símbolo y su pendiente, pero estos parámetros puede repetir. Si dejamos la imagen se digitalizan, todavía desconocido, y la amplitud de la señal, t E. El brillo del símbolo..
Yo no quiero entrar en la solución exacta de este problema dentro del artículo. De hecho está aún todo se reduce a la operación de cálculo de la covarianza de la señal de entrada con una hipotética (teniendo en cuenta el conjunto de desplazamientos y rotaciones):
X - señal de entrada, Y - una hipótesis. Designación E -. Expectación
Si es necesario seleccionar entre los diferentes símbolos, la hipótesis para la rotación y el desplazamiento traza para cada símbolo. Si sabemos que la imagen de entrada contiene el símbolo, la covarianza máximo de todas las hipótesis a definir un símbolo, su pendiente y offset. Aquí, por supuesto, plantea el problema de las imágenes de proximidad de los diferentes personajes ("p" y "c", "o" y "c", etc.). El más simple - se introduce para cada personaje matriz de coeficientes de ponderación
.
A veces, estos métodos se denominan «plantilla de coincidencia», que refleja plenamente su esencia. Patrón dado - comparar la imagen de entrada con las muestras. Si hay alguna incertidumbre en los parámetros, entonces o bien recorrer todas las opciones posibles, o utilice el адаптивные enfoques , aunque aquí ya saben y entender las matemáticas tienen.
Las ventajas del método:
- Resultado predecible y bien estudiado, aunque un poco de ruido corresponde al modelo elegido;
- Si la fuente se ajusta estrictamente, como en nuestro caso, es capaz de discernir mucho carácter polvoriento / sucio / desgastado
.
Desventajas:
- Computacionalmente muy caro
.
Redes neuronales h5> 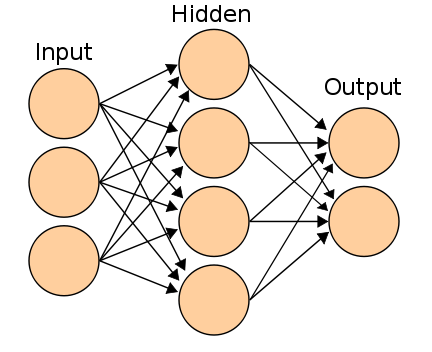
Red neuronal artificial Acerca de Habré ya había escrito un montón . Ahora ellos están divididos en dos generaciones:
- Red 2-3 capas clásico neural estudiar métodos de gradiente con retropropagación de errores (de 3 capas de redes neuronales se muestra en la figura);
- La llamada red neuronal y la red de convolución-aprendizaje profundo
.
La segunda generación de redes neuronales para los últimos 7 años, ganando varios concursos en el reconocimiento de imágenes, que dan el resultado es un poco mejor que los otros métodos.
Hay una base de datos abierta de las imágenes de los dígitos escritos a mano. Resultados de la Tabla href="http://yann.lecun.com/exdb/mnist/"> demuestra muy claramente la evolución de los diversos métodos, incluyendo algoritmos basados en redes neuronales.
También digno de mención especial de que las fuentes para la impresión de obras de una sola capa o bien de doble capa (una cuestión de terminología) red , que es esencialmente nada difiere de los enfoques de la plantilla de coincidencia.
Las ventajas del método:
- Cuando se ha configurado correctamente y la formación puede funcionar mejor que otros métodos conocidos;
- Con más de aprendizaje conjunto de datos resistente a la distorsión de caracteres
.
Desventajas:
- Lo más difícil para estos métodos;
- Diagnóstico de comportamiento anormal en las redes de múltiples capas es simplemente imposible
.

Conclusión h4> El artículo describe los métodos básicos de reconocimiento, sus fallos y errores típicos. Tal vez esto le ayudará a hacer de su habitación un poco más legible cuando se viaja por la ciudad, o viceversa.
Aún así, espero que haya sido capaz de mostrar una completa falta de magia en el problema del reconocimiento de los números. Todo es absolutamente clara e intuitiva. No es un problema terrible para el trabajo del curso del estudiante en la especialidad correspondiente.
Unos días más tarde poner un pequeño número raspoznavalka, basada en el trabajo en el que se escribió este artículo. Puede ser una trampa.
ZY Todas las habitaciones, que se enumeran en el artículo - extraídos de peticiones sencillas de Google y Yandex
Referencias h4> 1) Ondrej Martinsky - Artículo de revisión.
2) Kuo Ming Hung y Ching-Tang Hsieh enfoque -gistogrammny en el reconocimiento de números
3) Fatih Porikli, Tekin Kocak - enfoque de redes neuronales en la búsqueda de habitaciones
4) Saqib Rasheed, Asad Naeem y Omer Ishaq - encontrar habitaciones a través de HOG-descriptores líneas verticales
5) Suruchi G. Dedgaonkar, Anjali A. Chandavale, Ashok M . Sapkal - pequeño artículo de revisión sobre el reconocimiento de las hayas y los números
7) Libro de texto «Основа teoría del procesamiento de imágenes
», Krasheninnikov VR
Fuente: habrahabr.ru/post/221891/






















Colocación, ordinario y no muy
Los creadores de la computadora portátil libre Novena recogen fondos para el proyecto