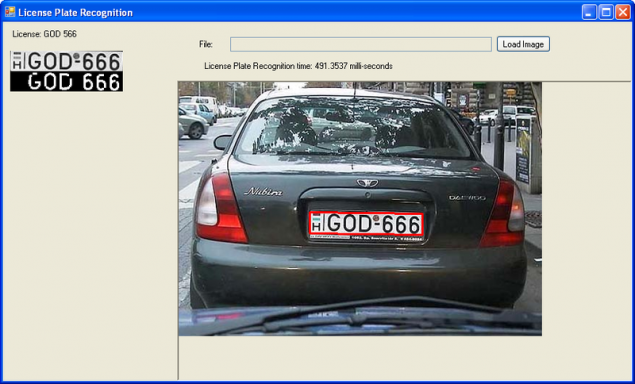
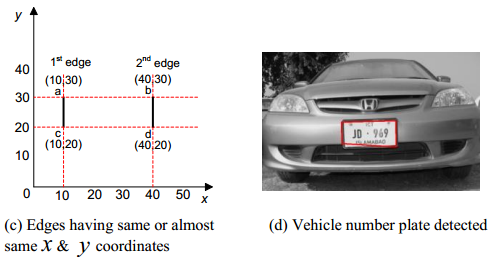
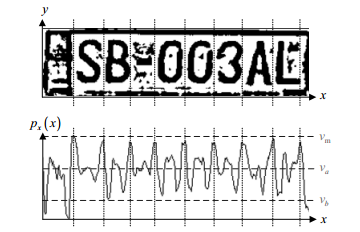
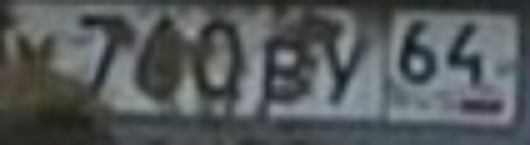3221
识别号:A到9
已经是情侣对哈布雷次出现如何识别号码现在工作的讨论。但在本文中,这将显示出不同的方法来识别号码,直到哈布雷不是。所以在这里,我们将试着去了解所有的工作原理。然后,如果文章会感兴趣,并会继续公布的工作模式,可以poissledovat。

软件VS铁 H4>的一个重要参数,建立识别的系统 - 铁用于摄影。更强大的和更好的照明系统中,相机越好,越可能识别的数目。良好的红外(IR)照明可以启发甚至灰尘和脏物,可在室内,风头盖过所有的干扰因素。我觉得有人来了类似的“连锁信”,其中除了房间什么都看不到。
算法的结构 H4>•高级搜索次数 B> - 检测区域,其中包含了一些
的边界和形状,轮廓分析分析 H5>的隔离房间,最明显的方法 - 找一个矩形轮廓。仅在情况下,当有一个清晰可读的轮廓没有围栏,具有足够高的分辨率和光滑边界。
边框 H5>只有部分的分析,更有趣,更稳定,更实用的方法似乎 ,其中,它的分析的范围的一部分。强调轮廓,然后找遍了所有的垂直线。用于位于彼此接近,具有沿轴y的轻微移位,与它们之间的距离,以它们的长度正确的比例,一个假设,即在它们之间的房间任何两行。其实,这种做法类似于简化的方法 HOG 。
地区 H5>其中的一个方法是最常用的方法直方图分析图像直方图分析( 1 ,的 2 )。该方法是基于这样的假设与一些来自附近的频率响应不同的区域的频率特性。
统计分析,分类 H5>什么是减去所有以前的方法?事实上,在真正的,沾满了泥巴房表示没有国界,没有显着的统计数据。从下面示出了这样的数字的一些例子。我必须说,莫斯科,这样的例子还不是最糟糕的选择。
的 h5的>的薄弱点在实际的算法的很多方法都直接或间接地基于该室的边界的存在。即使不使用用于检测室的限制,它可以被用于进一步的分析。
第2部分:标准化的算法 H4>最上面的算法展品数量不准确,需要进一步澄清了他的立场,并提高图像质量。例如,在这种情况下,需要旋转和裁剪边缘如下:
在水平方向上旋转数 h5的>当单独留下邻里间,隔离边界开始工作好得多,因为所有的长条水平线,其设法提取 - 这将是在房间的边界。
增加对比度 h5的>而最好的方式或其他改善得到的图像的对比度。严格来说,有必要加强的空间频率的感兴趣区域方法:
上的字母分区 H5>旋转之后,我们有一个带横向不准确明确的左右两边。正是削减不必要的,现在不一定够简单地削减字母在房间里提供的识别过程中与他们一起工作。
弱点 H5>有了显著数周期性的污染峰上的符号分区不能随便露面,虽然字符可以在视觉上相当的可读性。
第3部分:字符识别算法 H4>识别,一方面文本或单个字符(光学字符识别,OCR)的问题是困难的,但另一方面 - 相当经典。有许多算法来解决它,其中一些达到完美 的。另一方面,在公共领域的最佳算法不。当然有相当的tesseract OCR和他的几个同龄人,但这些算法不能解决所有的问题。在一般情况下,文字识别的方法可分为两类:基于结构形态和电路分析处理的基础上,直接图像的分析的二值化图像和光栅的方法的方法。这通常使用的结构和光栅方法的组合
与标准的任务OCR H5>首先,在俄罗斯,汽车数量,标准字体的任何情况。它只是为标志的自动识别系统的礼物。 90%的努力花在OCR手写。
的tesseract OCR H5>这是执行自动识别为一个字母,马上文本开源软件。 的tesseract 很方便,因为它是,对于任何操作系统运行稳定,易于接受训练的。但是,它的工作原理非常差与zamylennym,破,脏,变形的文字。当我试图做到这一点就承认房间 - 就只有20-30%的客房从数据库中强度正确识别。最清晰和直接。当然,虽然,当你使用现成的库依赖的东西的手曲率半径。
K-最近的 H5>很容易理解的文字识别,其中,尽管它的原始,往往不能赢得最成功实施SVM和神经网络方法的方法。
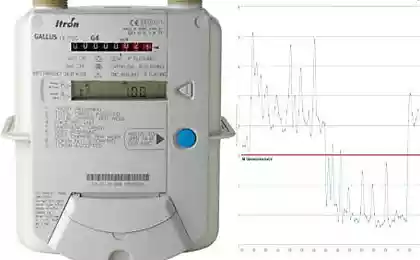
相关 H5>大多数方法,这些方法在图像识别中使用的,建立在实证的方法。但是,没有人禁止使用概率论,这只是抛光信号检测的雷达系统问题的数学工具。在我们知道赛车号码字体,相机室内噪声和灰尘难以被称为高斯。上有符号和斜率的位置一定的不确定性,但这些参数可以重复。如果我们离开图像进行二值化,但我们仍然未知,并且信号的振幅,吨; E.符号的亮度。
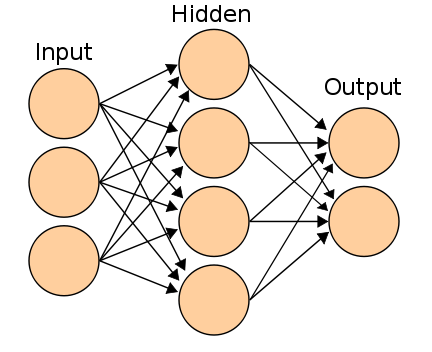
神经网络 H5>
结论 H4>本文介绍了识别的基本方法,它们的典型故障和错误。或许,这将帮助你周围的城市旅游,或反之亦然,当让你的房间有点更具可读性。
引用 H4> 1)算法和数学原理的自动车牌识别系统的Ondrej MARTINSKY - 评论文章。