1085
Synesthesia Máquina: audioanaliz el uso de algoritmos de procesamiento de imágenes

Si lo que desea es mirar el código para Python, siga el repositorio en GitHub .
Para la preparación de los materiales utilizados IPython Notebook. Se puede descargar en la ссылке.
Audioanaliz utilizando algoritmos de procesamiento de imágenes h4> procesadores gráficos fueron diseñados con un solo propósito - para simular las propiedades físicas de la luz, pero ahora tenemos que utilizar para una variedad de otros, una variedad de tareas. ¿Es posible utilizar algoritmos de procesamiento de imagen, fuera de la zona habitual? ¿Por qué no usarlos para el procesamiento de señales?
Para investigar esta cuestión, decidí usar el método de hacer coincidir las plantillas y las imágenes para determinar el audio. Algoritmos clásicos toma una foto y la plantilla y de retorno a cualquier grado de similitud de la parte del patrón de la imagen. Mi tarea fue identificar la canción en una base de datos, que es parte de las muestras de audio, usando un método de la comparación de la máscara (Eso es lo que hace que Shazam o SoundCloud).
Pre-tratamiento de datos h4> Los datos de audio se representa como una matriz unidimensional de muestras discretas distribuidas de manera uniforme en el tiempo. Single-imagen está generalmente almacenada y procesada como matrices bidimensionales, así que tuve que introducir algún modo de grabación de audio en dos dimensiones. La forma más primitiva - se acaba de formatear en una matriz bidimensional unidimensional
.
Sin embargo, en la práctica esto debe hacerse con cautela. Supongamos que empezamos a capturar el audio de una fuente de la mitad de un segundo después del inicio de los registros en la base de datos - que resulta matrices bidimensionales de estas dos entradas será muy diferente. Los dos picos se encuentran cerca, puede ser accidentalmente en extremos opuestos de la muestra.
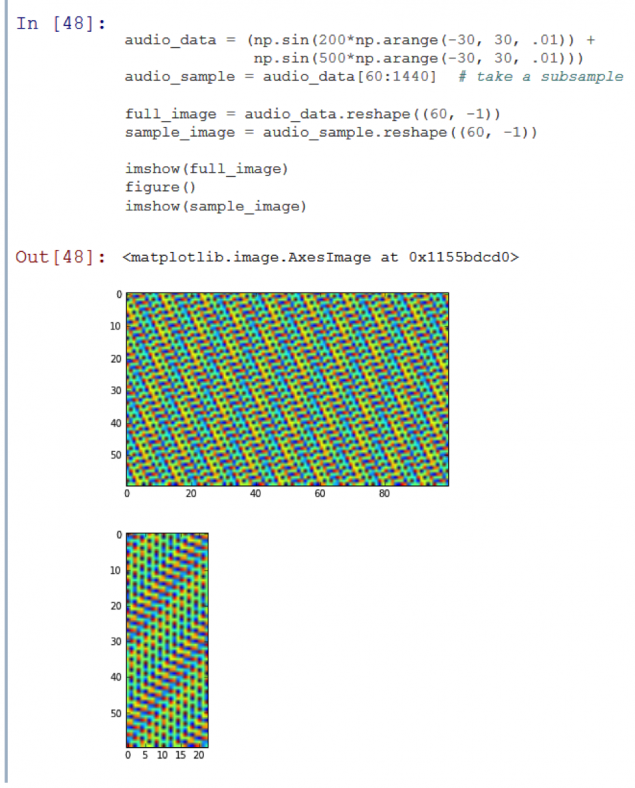
Obvio que la segunda imagen es una parte (submuestra) de la primera.
Un algoritmo simple comparación con máscara pone constantemente la máscara sobre la imagen y las comparaciones (donde esto ha sido una función match_template i> skimage.feature i>). Los algoritmos empleados de esta manera, no será capaz de reconocer la imagen más pequeña presentada anteriormente por más.
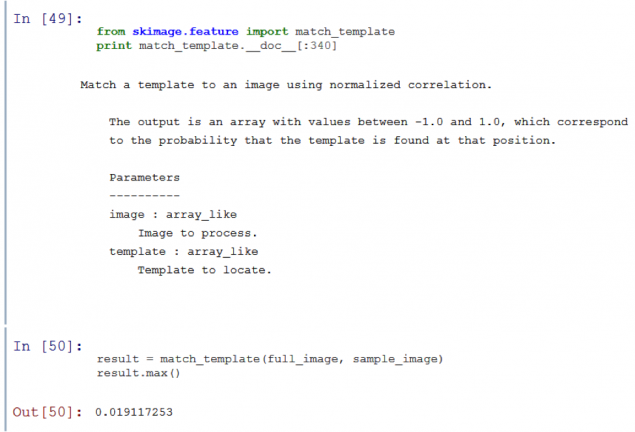
Como se puede ver, match_template i> da una muy baja posibilidad de hacer coincidir la plantilla con cualquier parte de la imagen.


Usamos la transformada de Fourier h4> Sensibilidad para cambiar el rango de tiempo se puede reducir a un mínimo, si se ignora la línea de tiempo e ir al nivel de la señal. Esto se hace mediante el uso de la Transformada Discreta de Fourier (DFT), y hazlo pronto - usando una transformada rápida de Fourier o FFT (Si necesita más información sobre la FFT y DFT, se puede ver el después Vanderplasa Jake (Jake Vanderplas)).
Si aplicamos la transformada de Fourier de cada columna a formatear nuestra señal, nos hacemos una idea de cómo los armónicos varían con el tiempo. Resulta que esta es una técnica muy común ampliamente utilizado al crear espectrogramas.
En su esencia, la transformada de Fourier nos dice que de la frecuencia de la señal tiene las más altas energías. Desde audio armónica generalmente cambia con el tiempo, entonces el espectrograma contiene tiempo propiedad y dominio de la frecuencia.
Veamos el sonido segmento espectrograma prueba:
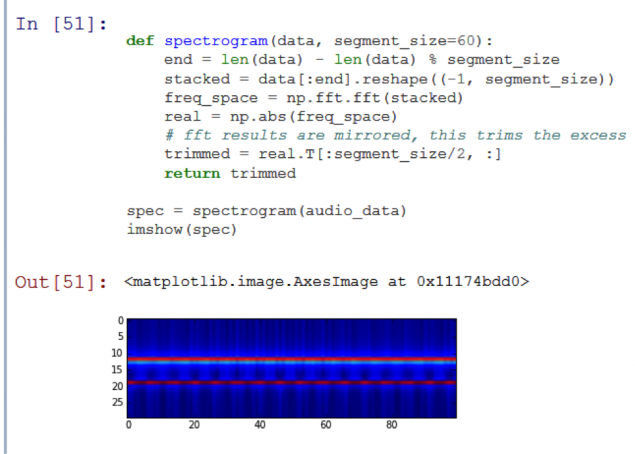
Como puede ver, la imagen muestra dos líneas horizontales. Esto significa que el audio consiste en un conjunto de dos señales inmutables. Dio la casualidad, ya que el registro de la prueba - no es más que la suma de dos señales sinusoidales de diferentes frecuencias
.
Ahora tenemos algo como la imagen y, en teoría, nuestro enfoque funciona bien con una submuestra, desplazado en el tiempo. Vamos a probar nuestra teoría:

Éxito! La función de match_template i> nos dice que estos dos "imágenes" tienen una fuerte correlación. Sin embargo, si el algoritmo trabaja con el sonido, que es algo más que una suma de señales sinusoidales?


Los datos reales h4> Quiero asegurarme de que mi equipo es capaz de determinar qué predeterminado episodio de la serie se está reproduciendo. Como ejemplo, usaré la temporada 1 de la serie de animación Adventure Tiempo. Ahorré 11 archivos WAV (uno para cada episodio) en el subdirectorio adv_time i>.
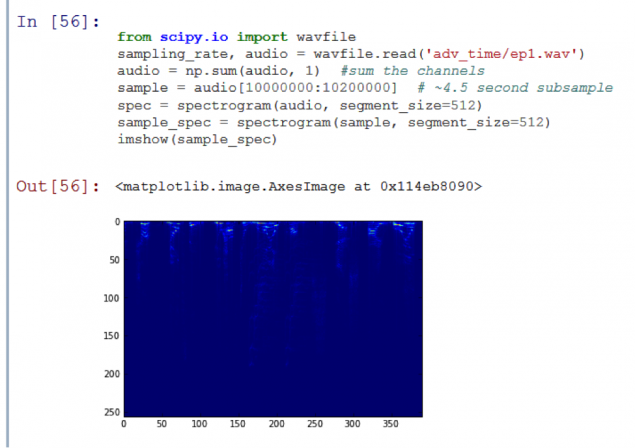
En el pico gráfico resultante aparecido! La función de match_template i> para definir exactamente lo submuestra es parte de la pista de audio original. Sin embargo, la comparación del algoritmo tomó 20 segundos demasiado largo. Para acelerarlo, tenemos que "perder" algunos datos.

Pidamos al Nyquist h4> Un hombre llamado Harry Nyquist nos mostró que la tasa más alta que podemos identificar de forma fiable, igual a la mitad de la frecuencia de muestreo.

La frecuencia de muestreo de 44,1 kHz significa que podemos determinar las frecuencias de audio de hasta 22 kHz. Esto es suficiente, ya que el oído humano percibe frecuencias dentro de sólo el 20 kHz .
Sin embargo, en el espectrograma anterior demuestra que la práctica totalidad de los datos de interés se encuentran en la mitad superior, y el mayor número de - entre los ocho primeros. Parece que el alcance de la información útil contenida en la banda sonora de Adventure Time, incluso cerca del límite superior de la percepción humana. Esto significa que podemos producir un paso remuestreo 8, y no perder demasiada información importante.
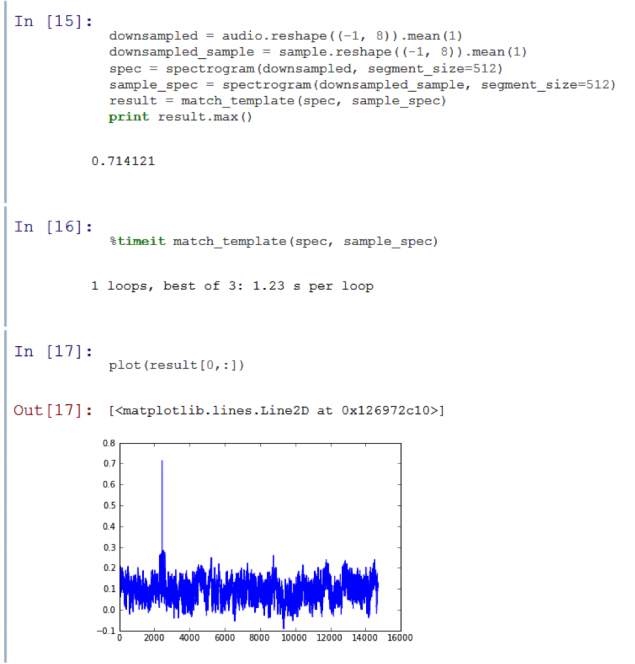
Mucho mejor. Sub Muestreo acelerar función 15 veces, sin dejar de dar una clara señal a ruido ambiental de fondo, que es el 71%. Sin embargo, quiero acelerar aún más el proceso, vuelva a cortar la cantidad de datos. Si nos pasamos más tiempo en el momento de submuestreo, entonces comenzamos a perder una importante información de alta frecuencia. Pero es posible llevar a cabo la cuantificación.
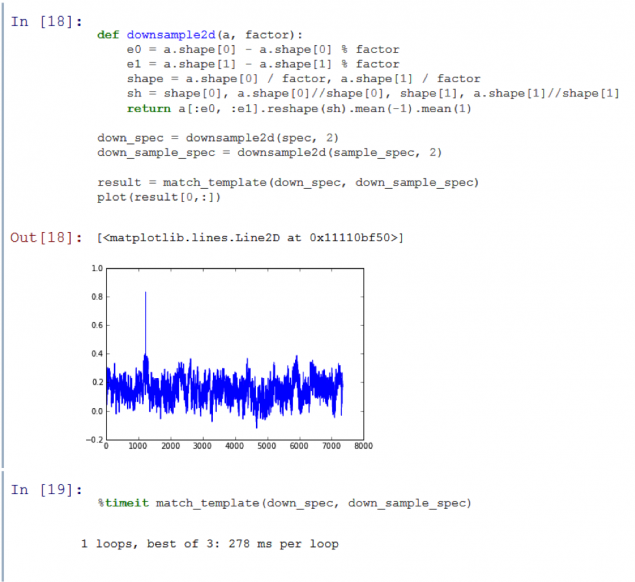
Una vez más, hemos acelerado hasta 4 veces, que todavía mantiene una buena relación / ruido de la señal! Estoy muy contento con la velocidad del algoritmo. Ahora puedo hacer una muestra de comparación con una de cinco segundos pista de audio de dos horas en menos de un segundo. Pero había una última prueba. Hasta el momento, hemos utilizado una submuestra labrado registros de la base de datos. Necesito entender si las muestras de algoritmo, registraron utilizando un micrófono.
El resultado del experimento se presenta después de que el código de abajo. En primer lugar, he preparado una pista de audio de cada episodio, y mantenerlos en el directorio Tienda i>. Luego utiliza la pyaudio en su ordenador portátil para grabar el sonido del episodio Adventure Time desde el televisor.
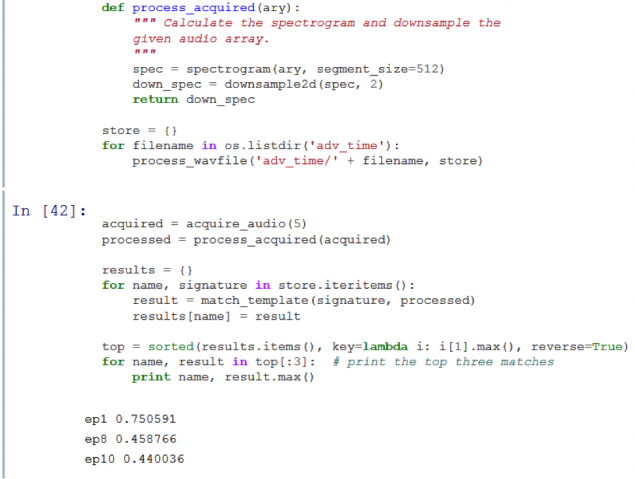
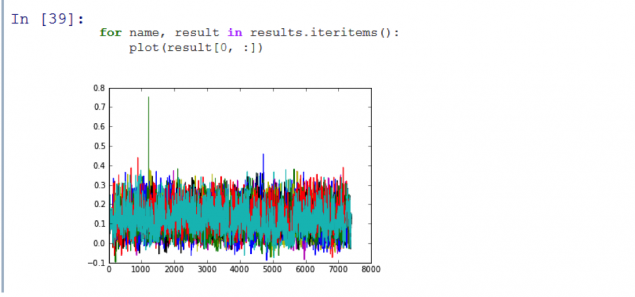
Funciona! Como se puede ver, en el gráfico resultante muestra un pico, lo que significa que el programa se reconoce correctamente el primer episodio de la temporada. Escribí el código fue capaz de identificar los primeros 11 episodios de la serie Adventure Time con suficiente precisión y en menos de 3 segundos.






Conclusión h4> I fue capaz de utilizar algoritmos de procesamiento de imágenes más allá de su aplicación normal. Tengo que crear una buena aplicación, reconociendo registro. Tal vez se dio cuenta de que no la mejor (estoy seguro Shazaam utiliza un algoritmo más eficiente), pero su creación me ha dejado un par de experiencias agradables. He probado otros métodos que utilizan una comparación con una máscara, por ejemplo, la modulación de la esquina y SURF (ver github ), pero el enfoque clásico fue el más obvio y fácil de realizar. Más trabajo puede ser dirigido al estudio de otros métodos.
Yo no escribí código limpio, la utilización eficaz de la memoria de la computadora, y creo que es posible para exprimir mucho más rendimiento. Además de las cuestiones relativas al trabajo con la memoria, estos algoritmos son todavía muchos problemas por resolver - No pasé un montón de optimización del tiempo. Más trabajo puede revelar toda la belleza de tiempo sub-muestreo y frecuencia. También me gustaría experimentar con la longitud de la muestra y su submuestreo.
Me gustaría probar la fiabilidad del algoritmo para trabajar con diferentes fuentes de audio. Muestreo me sujetaron no estaba atado a un tipo específico de audio me utilizado, pero podría estropearlo todo si se conecta otra fuente de audio.
Todo el código está disponible en github .
Fuente: geektimes.ru/company/audiomania/blog/251144/






















{kind=link}
A medida que Internet no está funcionando - páginas amarillas en lugar de herramientas modernas
No californianos ricos reciben paneles solares gratuitas