745
Комп'ютери збити людей в тесті дієтичних IQ
Більше сотні років тому німецький психолог Вільям Стерн запропонував перевірити людський інтелект, який був викликаний тестом IQ. З того часу тест IQ став досить поширеним як стандартний метод оцінювання інтелекту дітей при вступі в школу, а також для оцінки кандидатів на роботу дорослих.
Тести IQ зазвичай містять три типи питань: (1) логічні питання, де потрібно розпізнати шаблон в послідовності зображень; (2) математичні питання, де потрібно визначити шаблон в послідовності чисел; (3) словесні проблеми на основі аналогій і класифікації, як синонімів і антонимів.
Дослідники з Microsoft Research в Пекіні спільно з колегами з Університету науки і техніки Китаю розробили технологію AI, здатну розв’язати третій тип завдань, перерахованих вище.
Комп'ютери ніколи не змогли зрозуміти і вирішувати проблеми, розроблені дієслово. Не менше, ніж люди. Microsoft Research змінює речі. За перший раз, їх глибока програма навчання перевершила середній людський рахунок на тесті дієслового IQ.
В останні роки науковці використовували методи обробки даних для аналізу великих обсягів текстів для пошуку конкретних з'єднань між словами. Зокрема, дана методика дозволяє компілювати словник з статистичними показниками, як часто викладаються певні слова по одному. Це дозволяє визначити взаємозв'язок слів з кожним іншим.
В результаті кожне слово в такій системі сприймається як вектор в багатовимірному просторі параметрів. Таку систему векторів можна обробити математичними методами: порівняти їх, додати їх, відняти один від одного, як звичайні вектори. Наприклад, подібного рівня стає можливим: «корока – людина + жінка = королева».
Цей підхід є ефективним. Наприклад, Google використовує видобуток даних в автоматизованій системі текстового перекладу, порівнюючи вектори слів на різних мовах.
Але в разі словесних IQ тестів завдання ускладнено, тому що тут одне слово може мати декілька значень. Тест-підготовки спеціально для того, щоб ускладнити завдання.
Команда дослідників з Microsoft Research виявила рішення на цю проблему за допомогою того ж видобутку даних: їхня програма визначає, які слова найбільш поширені з кожним словом в масиві текстів, а потім визначає можливі значення цього слова, на основі отриманої інформації. Це робиться шляхом обчислення векторів з отриманих вироків. Для програми спочатку скомпільовано матрицю частоти виникнення слів, а потім, на основі корпусу текстів (викіпедії статті), вектор виникнення інших слів вказується для кожного слова.
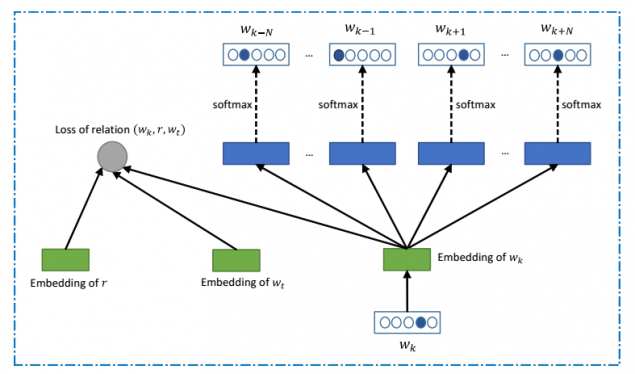
Вчені говорять, що програма показує кращий результат, ніж більшість людей. Проведено опитування на сайті Механічна Турка.
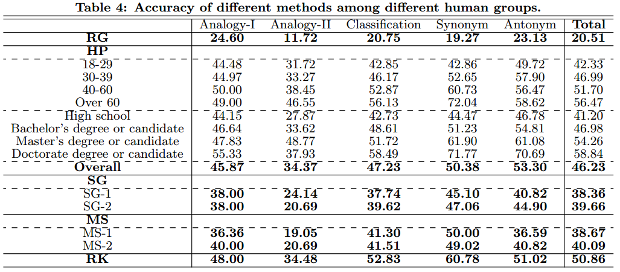
Відповідно до таблиці, його результат приблизно в середині між результатами, які показують середні результати холостяка і тримачів магістра.
Джерело: geektimes.ru/post/252196/
Тести IQ зазвичай містять три типи питань: (1) логічні питання, де потрібно розпізнати шаблон в послідовності зображень; (2) математичні питання, де потрібно визначити шаблон в послідовності чисел; (3) словесні проблеми на основі аналогій і класифікації, як синонімів і антонимів.
Дослідники з Microsoft Research в Пекіні спільно з колегами з Університету науки і техніки Китаю розробили технологію AI, здатну розв’язати третій тип завдань, перерахованих вище.
Комп'ютери ніколи не змогли зрозуміти і вирішувати проблеми, розроблені дієслово. Не менше, ніж люди. Microsoft Research змінює речі. За перший раз, їх глибока програма навчання перевершила середній людський рахунок на тесті дієслового IQ.
В останні роки науковці використовували методи обробки даних для аналізу великих обсягів текстів для пошуку конкретних з'єднань між словами. Зокрема, дана методика дозволяє компілювати словник з статистичними показниками, як часто викладаються певні слова по одному. Це дозволяє визначити взаємозв'язок слів з кожним іншим.
В результаті кожне слово в такій системі сприймається як вектор в багатовимірному просторі параметрів. Таку систему векторів можна обробити математичними методами: порівняти їх, додати їх, відняти один від одного, як звичайні вектори. Наприклад, подібного рівня стає можливим: «корока – людина + жінка = королева».
Цей підхід є ефективним. Наприклад, Google використовує видобуток даних в автоматизованій системі текстового перекладу, порівнюючи вектори слів на різних мовах.
Але в разі словесних IQ тестів завдання ускладнено, тому що тут одне слово може мати декілька значень. Тест-підготовки спеціально для того, щоб ускладнити завдання.
Команда дослідників з Microsoft Research виявила рішення на цю проблему за допомогою того ж видобутку даних: їхня програма визначає, які слова найбільш поширені з кожним словом в масиві текстів, а потім визначає можливі значення цього слова, на основі отриманої інформації. Це робиться шляхом обчислення векторів з отриманих вироків. Для програми спочатку скомпільовано матрицю частоти виникнення слів, а потім, на основі корпусу текстів (викіпедії статті), вектор виникнення інших слів вказується для кожного слова.

Вчені говорять, що програма показує кращий результат, ніж більшість людей. Проведено опитування на сайті Механічна Турка.

Відповідно до таблиці, його результат приблизно в середині між результатами, які показують середні результати холостяка і тримачів магістра.
Джерело: geektimes.ru/post/252196/






















Космічний апарат в сонячній системі: від Венери до Плуто
Структура сітки з негативною еластичністю допоможе розробити новий тип захисту від ударів