2311
思维的逻辑。部分16批次演示
本系列文章介绍了大脑的电波模式与传统模式完全不同。我们强烈建议那些谁刚刚加入,从开始的 第一部分阅读。
信息,其大脑使用,应,一方面充分地描述所发生的事情,另一方面,应该存储,以便允许由大脑所需的操作的执行。原则上,信息及其处理算法的描述的格式 - 事情是紧密相连的。第一很大程度上决定了第二。因此,谈到数据如何被组织,存储由大脑,我们希望它与否,很大程度上决定思维过程的后续制度。由于只对如何确保当前和后续存储的描述的完整性谈论的思维,我们稍后会,但现在我们将重点的原则。在这种情况下,这意味着,如果,达到思想之前,它原来所选择的数据格式下所需要的算法来了,这意味着我们是幸运的,我们走到正确的道路上。
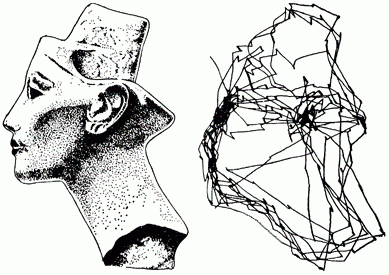
要了解什么样的格式描述用于脑跟踪视觉感知的序列。看着这张照片,我们是他的快速眼球运动“扫描”,被称为扫视(上KDPV图)。他们每个人都被放置在图像的片段之一的中心。上的视觉皮层区域有对应于我们在这一点上在他所看到的中心所看到的与外围设备的位移,作为刚做完扫视结果的描述。每下一个扫视生成新的图像。这些描述跟随对方一个接一个。
这样,看着面前,我们首先,例如,可以清楚地看到并识别一只眼睛,一个目的是看。被引导到相对的外周面的其余元件 - 鼻,口等,我们发现较少,但相同的是高概率。之后每个扫视中央片段而异,但一组共同认可的元素保持不变。
原则上,每个扫视之间发生的这些个别的描述,足以说这人在我们的面前,甚至可以找出它属于谁。但是,每一个描述可靠只说对象,这对他来说是在凝视的方向。其余对象确定有足够的了解。
如果我们想获得面对一个更加完整和详细的图片,那么这将满足设定的扫描过程中发生的所有描述。这将是很重要的东西,这些对象的认可有关在望伴随转变不只是一个描述,但也信息。在这里,我们就来一个很重要的一点。什么是概括的描述,这应该产生视觉分析?只是一些概念的活动的图像?这相当于我们所看到的,现在的描述只是一部分。但对于其他人呢?事实证明,正确的,不丢失信息,说明 - 一包的连续简单的描述。其中,每个所述临时密封的层仅描述了一些获得怎样的收集的完整描述的信息。这是真实的,只要在包中的所有描述对应于一个事件,那就是,起身向全球转移我们的注意力。
如果取大脑皮质的活性的快照,正在发生的事情的描述可以与活性概念在其每个区域的列表进行比较。但这样的描述具有显著缺点。假设我们想要描述的静物,如下图所示。
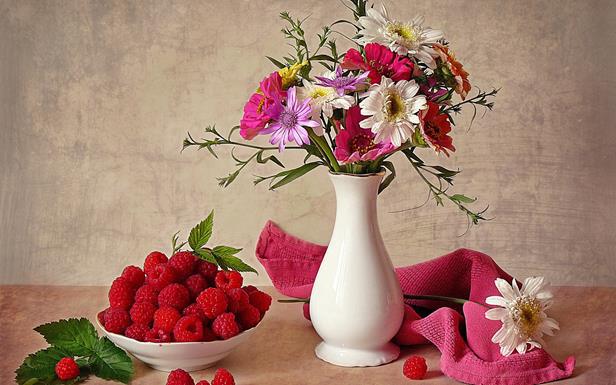
我们可以做到这一点是这样的:
- 在花瓶稍右中心;
- 一个花束插在花瓶里;
- 花瓶的毛巾权利;
- 白的花放在毛巾;
- 在一碗左侧树莓;
- 莓板材到碗里的左侧;
- 三面前一碗覆盆子的;
- 花瓶的树莓权 ul>概述由一组简短描述的。每一个简短的描述可以,有一些理由,来代替包含在它的概念转移。但是,如果我们要收集汇总的说明,只需添加所有参与短期上市的概念,我们就会失败。用加入了一些信息会消失,如将变得清楚的是什么。但是,除此之外,它出现的一些必要的概念来使用数次。例如,覆盆子和它的左,右,和一个碗的前面。如果我们想用它“只是建立”如何静物作为皮层的区域中描述的比喻,事实证明了“树莓”的泛化,我们有一个描述,它不能同时“积极的三倍。”摆脱这种局面,这似乎很合乎逻辑的,我 - 是使用包描述。每一个简单的描述可能包括有源概念平庸上市。完整的描述是作为一组简单的描述。因为简单描述在时间上间隔开,一方面,很显然,什么应用和,另一方面,同样的概念可以多次出现在封装在各种上下文中的不同层。
这个包演示文稿很好的相关性与对人的关注范围的争论。心理学家研究关注的性能,发现有一个限制位点,人们可以同时集中的数量。通常情况下,这个极限不超过7的对象。使用机械注意力速示器第一体积测量做实验心理学冯特的创始人。

Tahitoskop - 一种装置,可以让你产生一致的视觉刺激 I>
估计的注意力程度是很简单的。看看以前的静物并尝试计算有多少个人的元素,你不能,不记得了,那是不同的,但同时记住。或乘坐7位电话号码,如1145618,尽量“保持”了他的头部。最有可能的,他不是走了,你就必须重复循环自己。如果在数字位数大于7,这是一个很好的机会,让他们全部在内存中将会失败。同时感知物体静物或数字的最大数目给你的关注量的估计值。
我们对在大脑皮质的分组信息的假设使我们能够关联的每个中的注意信息包的层中的一个保持的对象。
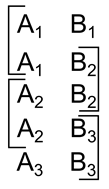
如果您提交的地壳由少数概念,能够制定对两个对象“A”和“B”,对应的思想包很简单的想法:“躺在蓝色的物体B”的红色物体,就会出现如图下文。
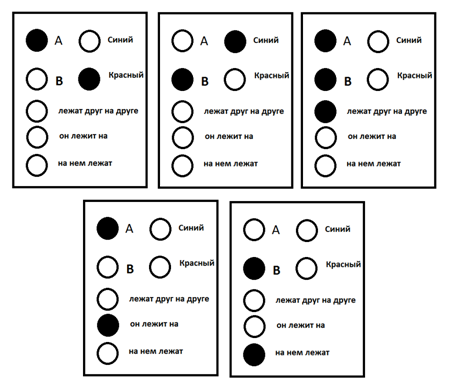
例如信息包 I>
复杂的描述编码
让我们回到内存,并试图组织,什么类型的信息,并说明可以与我们的大脑处理的,因此类型。
第一类型 - 是一个对应于皮质的活性的瞬时图像进行简单的描述。它是那些由大脑检测到现在这些概念的组合。
第二类 - 一套对应一个事件,一个想法的简单描述。包是无关紧要的序列的描述。重新排列的包层不会改变发声的一般含义。记住包 - 是一系列连续的简单描述恢复
。
第三类型 - 的位置的描述。在本说明书中,一个对象到另一个的连接,位于它们在关系的一个特定的系统。例如,一个版本的这样的描述 - 空间描述。当我们不只是固定其在空间中的位置,并与其他物体的某些描述的位置联系起来。
第四类 - 的过程描述。这样的描述,这是在该图像的变化和随之而来的时间间隔的重要序列。例如,语音的感知声音的序列,其中的间隔的比形成语调,这是高度依赖于听到短语的一般含义来确定。回味的程序 - 图像的相应序列的再现
和第五类型 - 按时间顺序描述。固定的时间以什么顺序,什么时间间隔很长一段发生或事件。机会召回年代记忆 - 这还不是全部打一次属于一个年代,从一个描述到另一个,相关的一般时间序列的能力
。
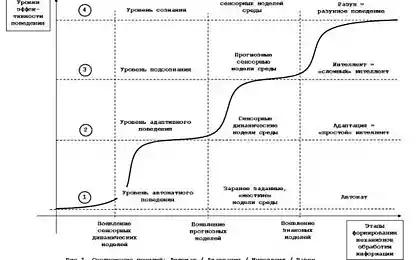
这是很容易注意到,许多描述或另一种方式连接到时间。批次描述 - 这是一系列连续的图像。程序步骤说明考虑事件的顺序。年代描述需要考虑到时间的事件的定位。
从时间这种依赖的描述引起了相应的机型的外观。其中最有名的 - 由杰夫·霍金斯分层时间记忆(HTM)(霍金斯,2011)推动的概念。他和他的同事们基于该事件的时间变化的事实 - 唯一的东西,使得有可能涉及个人信息的图像。从此可以得出结论,该基本信息单元应当不与静态图像操作皮质,用时间序列。概念HTM细胞储存 - 部署在信号的时间序列。识别 - 两个序列的一致的定义。特别强调的HTM到预测的能力。一旦神经元学会他所知的序列开始,他成为能够预测想起我的经验,他们继续。当前画面HTM的描述 - 是那些回应时事的变化神经元的活动
。
在这种方法的复杂性是显而易见的。一,遵守时间的要求尺度。在收到该数据略微加速或拖延可能破坏识别算法。其次,需要翻译的所有静态图象在时间序列之前树皮可以与他们进行操作。等等。
在我们的模型系统标识符为我们提供了同样适用来描述所有可能的类型的存储器的多功能工具。基本的想法很简单 - 每一个简单的描述是一个复合的ID,包括您需要指定的整套作为关联和时间关系的一切
。
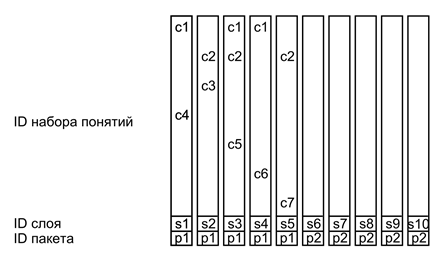
下图显示了这样一个简单的描述的示意图。一个简单的描述 - 这波拎着几台不同类型的标识符。主要内容是由一组概念描述的正在发生的事情的本质标识符进行编码。层的识别标记为主要内容,从简单的描述其余分离。包标识符结合属于同一复杂描述的多个层。的地点,时间和顺序的ID来创建复杂的描述之间建立适当的联系制度。
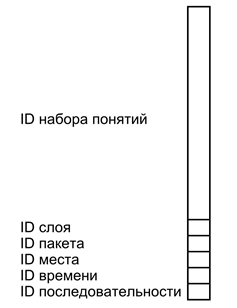
的 i>的
一个简单的描述格式
走在前面的例子,让相应的使用(概念)的概念浪标识符,如C1 ... C7(下图)。
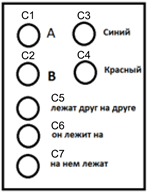
使用的术语来形容 I>
那么什么是“红色的对象A的描述是一个蓝色的物体B”会出现如下图所示。
举例说明复杂 I>
在本实施例中,每个袋子的各层的是一个简单的描述,以该层的标识符。所有层有一个总包包标识符P1。当确实1络合物的说明中,等等,下面是从一个包识别符P2(概念第二描述中未示出)的不同。
这种设计是可行的,大脑需要一个相当复杂的创造形成包装标识制度。并为每个的皮层区域可能需要一组不同的标识符相关她。
例如,采取视觉感知的序列。突然微动眼,称为microsaccades,导致眼来扫描落在视网膜的中心的图像的一小部分。在这样的扫描的过程中获得的所有的图像,可以预期到加入共同标识符。微动作控制眼睛的上凸块四叠体。可以假定它们编码这样的标识符。经过数microsaccades是强跳跃所谓扫视(与奈费尔提蒂头部的上图中示出扫视)。每个扫视原因改变ID microsaccades。
我们可以假设,microsaccades是基本的初级视觉皮层。常见的标识符报道地壳的一系列连续的描述相同的对象,但在,让您将它们组合成一个单一的说明和实施,以不变的视网膜识别的位置视网膜的不同位置。
较长的事件 - 一系列扫视。由于该系列是指单张图片的推敲,你会得到同样的描述可以连接在一起另一种常见的标识符 - 扫视的标识符。但是,这个身份是不是为视觉皮层,其中后处理信息的中小学和更深的层次是必不可少的。标识符,告诉在一系列扫视的外壳,所有我们看到的 - 都是同一个画面,允许那些在视网膜的不同的地方看到相同的图像关联
。
改变扫视的标识符时,画面显著的变化,研究应该发生。例如,与头部的强烈转,移位注意,计划改变或场景在电影中。移注意力可以被编码脑和蔓延的边缘系统的要素多,它是依赖于,皮层区。在同一时间,在本描述标识符海马编码事件时空描述。总之,该系统的标识符定义包中,可以说是相当复杂的,并通过其具有处理的皮质的每个特定区域的信息的特征。
使用的ID很容易组织活动的锁定序列。例如,如果你把一个标识符,由两片,然后交替变化的其中之一,你可以得到一个关联关联邻国描述(见下图)。
的编码序列 I>
每一个这样的元素将包含前一个和随后的识别符的识别符。记住图像的时间序列,这样的标识符为每个图像,我们就能找到他的两个邻居在时间轴上。这是很容易复杂化标识符可编码不仅总体一致性,而且时间的流动的方向。
应当注意的是,在我们的模型中,每一个存储器具有丰富的标识符的系统。这允许通过各种非常不同的协会的对存储器的访问。您可以根据重合洗净描述记得了。与其相关联的信息可想象的地点或描述的事件的时间。可以起到属于同一事件的图像序列。不难看出,这样的访问内存有许多共同之处,用于创建传统的关系型数据库的方法。
参考
前面的部分:
第1部分神经元
第2部分因素
第3部分:感知器,卷积网络
第4部分后台活动
第5部分脑电波
第6部分预测的系统</A>
部分7.人机界面
第8部分:分配因素波网
第9部分:神经探测器的模式。背投
第10空间自组织
第11部分动态神经网络。关联
部分12.下列内存
第13联想记忆
第14海马
部分15.巩固记忆
阿列克谢Redozubov (2014)
来源: habrahabr.ru/post/216825/