780
Штучний інтелект вперше в світі перемогв чемпіона
Це був AlphaGo від Google.
Найкращий підрозділ Google заявив, що штучний інтелект компанії вдалося перемогти чемпіона Європи в настільній грі Go. AlphaGo збиває людей 5 з 5 ігор. Перед тим, як було одне з небагатьох логічних ігор, які професійні гравці виграли на комп'ютери.
Одним з чітких показників розвитку штучного інтелекту є перемога в логічних іграх. АІ може перемогти чемпіона будь-якої логічної гри, яка продемонструвати, що алгоритм може вирішити проблему краще, ніж людина. З роками зростає кількість завойованих ігор: як касети, так і шахи. У 1996 році алгоритм вперше завоював на кращий шаховий програвач: він був дуелом глибокого синього комп'ютера від Kasparov. І в 2005 році людина отримала кращий алгоритм. З тих пір комп'ютерні програми можуть побити будь-який шахрайський програвач. Інші ігри є потужними: IBM Watson грали і виграв Jeopardy, а в 2014 році пошуковий гігант штучного інтелекту Google освоїв 49 старих ігор Atari на власній основі.
Але деякі ігри ще не були підкорені. Один з неприйнятих протягом тривалого часу залишився Go. Це настільна гра, яка виникла в Стародавньому Китаї кілька тисяч років тому. прямокутна дошка 19х19 заповнюється чорними і білими каменями. Кожна з гравців має завдання огородити більшу територію на ігровій дошці з камінням, ніж опонент. У грі є кілька правил, які важко створити ефективну систему штучного інтелекту, щоб перемогти людей. Наприклад, можливі позиції каменів на стандартній дошці більше 10,100 разів більше, ніж у шахи. Більше можливостей у Всесвіті. Просто неможливо розрахувати всі переміщення, і поки кращі комп'ютерні системи грають на рівні аматора.
Багато переходів в Go визначаються простою інтуїцією, і це важко вписуватися в алгоритм. Це складність, яка привертає увагу фахівців штучного інтелекту. DeepMind — розробник штучного інтелекту, який придбав Google у 2014 році. DeepMind вдалося створити програмне забезпечення, яке може перемогти чемпіонів.
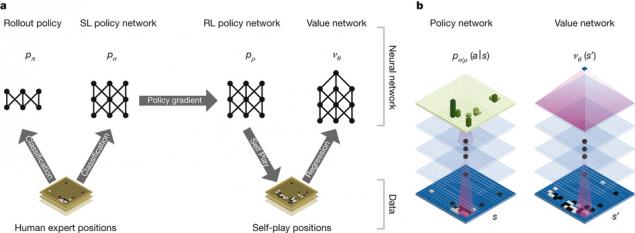
Створення пошукового дерева не працює тут, тому створено систему AlphaGo. На основі пошуку Монте-Карло та глибоких нейронних мереж. Неуралні мережі пропускають опис стану дошки Г через 12 різних шарів, що складаються з мільйонів нейроподібних з'єднань. Одна з мереж, «політика мережі» вибирає наступний рух. «мережа цінності» прогнозує переможця.
Нейромережа навчалася на 30 млн переїздах реальних людей. Результатом правильної прогнозування наступного руху було досягнуто в 57% випадків. До AlphaGo кращий результат був 44%. Але мета була перемогою, не тільки імітація чоловіка. Афіша Вивчайте це тисячами пакетів між власними нейромережами та покращуючи зв’язки під час навчання армуванням. У той же час весь процес вимагає значної потужності обробки, тому все ran в хмарі Google Cloud Platform.
Спочатку отриманий продукт був протестований з іншими кращими рішеннями. Афіша Go виграв 499 матчі з 500. Тоді запрошували суддю з Британської Федерації, редактора журналу «Природний» та триразового чемпіона Європи Фан Хуі. Цей професійний програвач був грати в азіатські настільні ігри йти з 12 років. За закритими дверималями в лондонському офісі Google за останні жовтень.
Для запуску алгоритму, він взяв обчислювальний кластер 170 карт графіки і 1,200 процесорів (докладно індивідуальні ядра). Вболівальник дивився, щоб знайти, що він втратив на комп'ютер в першій грі. Переможець на власний неагресивний стиль. Він подумав, що це просто теплий і почав грати більш агресивно. Але вболівальник втратив всі чотири наступні ігри. Алгоритм АльфаGo виграло в п'ять ігор.
Як кажуть в Google, це перший раз програма здатна перемогти професійного гравця в Go. Наступний логічний крок - матч в Сеул в березні проти легендарного корейського go-professsional Lee Sedol - кращий гравець Go в останнє десятиліття. Для цього матчу продуктивність системи буде покращена, щоб вона може працювати на більш скромному обладнанні.
Відіграли десятки мільйонів людей по всьому світу. Поступово завойовує ще одну логічну гру. Але це також цікаво, що AlphaGo не був побудований за допомогою ручних правил. Машинне навчання допомогли виграти.
Google сподівається використовувати свою експертизу для вирішення реальних проблем. Застосування методів загального призначення означає, що такі алгоритми можуть використовуватися в багатьох системах, від моделювання клімату та аналізу хвороб до біржових торгів.
У середу результати дослідження були опубліковані в науковій журналі Nature.
Аналогічний розвиток здійснюється на Facebook. Марк Заккерберг повідомляє Середу, що його дослідники знаходяться поруч, щоб завоювати китайська гра. Zuckerberg буквально спостерігає процес розробки: автор проекту сидить шість метрів від столу Генерального директора Facebook.
Дослідження Facebook: arXiv:1511.06410 [cs.LG]
Джерело: geektimes.ru/post/269990/
Найкращий підрозділ Google заявив, що штучний інтелект компанії вдалося перемогти чемпіона Європи в настільній грі Go. AlphaGo збиває людей 5 з 5 ігор. Перед тим, як було одне з небагатьох логічних ігор, які професійні гравці виграли на комп'ютери.
Одним з чітких показників розвитку штучного інтелекту є перемога в логічних іграх. АІ може перемогти чемпіона будь-якої логічної гри, яка продемонструвати, що алгоритм може вирішити проблему краще, ніж людина. З роками зростає кількість завойованих ігор: як касети, так і шахи. У 1996 році алгоритм вперше завоював на кращий шаховий програвач: він був дуелом глибокого синього комп'ютера від Kasparov. І в 2005 році людина отримала кращий алгоритм. З тих пір комп'ютерні програми можуть побити будь-який шахрайський програвач. Інші ігри є потужними: IBM Watson грали і виграв Jeopardy, а в 2014 році пошуковий гігант штучного інтелекту Google освоїв 49 старих ігор Atari на власній основі.
Але деякі ігри ще не були підкорені. Один з неприйнятих протягом тривалого часу залишився Go. Це настільна гра, яка виникла в Стародавньому Китаї кілька тисяч років тому. прямокутна дошка 19х19 заповнюється чорними і білими каменями. Кожна з гравців має завдання огородити більшу територію на ігровій дошці з камінням, ніж опонент. У грі є кілька правил, які важко створити ефективну систему штучного інтелекту, щоб перемогти людей. Наприклад, можливі позиції каменів на стандартній дошці більше 10,100 разів більше, ніж у шахи. Більше можливостей у Всесвіті. Просто неможливо розрахувати всі переміщення, і поки кращі комп'ютерні системи грають на рівні аматора.
Багато переходів в Go визначаються простою інтуїцією, і це важко вписуватися в алгоритм. Це складність, яка привертає увагу фахівців штучного інтелекту. DeepMind — розробник штучного інтелекту, який придбав Google у 2014 році. DeepMind вдалося створити програмне забезпечення, яке може перемогти чемпіонів.
Створення пошукового дерева не працює тут, тому створено систему AlphaGo. На основі пошуку Монте-Карло та глибоких нейронних мереж. Неуралні мережі пропускають опис стану дошки Г через 12 різних шарів, що складаються з мільйонів нейроподібних з'єднань. Одна з мереж, «політика мережі» вибирає наступний рух. «мережа цінності» прогнозує переможця.

Нейромережа навчалася на 30 млн переїздах реальних людей. Результатом правильної прогнозування наступного руху було досягнуто в 57% випадків. До AlphaGo кращий результат був 44%. Але мета була перемогою, не тільки імітація чоловіка. Афіша Вивчайте це тисячами пакетів між власними нейромережами та покращуючи зв’язки під час навчання армуванням. У той же час весь процес вимагає значної потужності обробки, тому все ran в хмарі Google Cloud Platform.
Спочатку отриманий продукт був протестований з іншими кращими рішеннями. Афіша Go виграв 499 матчі з 500. Тоді запрошували суддю з Британської Федерації, редактора журналу «Природний» та триразового чемпіона Європи Фан Хуі. Цей професійний програвач був грати в азіатські настільні ігри йти з 12 років. За закритими дверималями в лондонському офісі Google за останні жовтень.
Для запуску алгоритму, він взяв обчислювальний кластер 170 карт графіки і 1,200 процесорів (докладно індивідуальні ядра). Вболівальник дивився, щоб знайти, що він втратив на комп'ютер в першій грі. Переможець на власний неагресивний стиль. Він подумав, що це просто теплий і почав грати більш агресивно. Але вболівальник втратив всі чотири наступні ігри. Алгоритм АльфаGo виграло в п'ять ігор.
Як кажуть в Google, це перший раз програма здатна перемогти професійного гравця в Go. Наступний логічний крок - матч в Сеул в березні проти легендарного корейського go-professsional Lee Sedol - кращий гравець Go в останнє десятиліття. Для цього матчу продуктивність системи буде покращена, щоб вона може працювати на більш скромному обладнанні.
Відіграли десятки мільйонів людей по всьому світу. Поступово завойовує ще одну логічну гру. Але це також цікаво, що AlphaGo не був побудований за допомогою ручних правил. Машинне навчання допомогли виграти.
Google сподівається використовувати свою експертизу для вирішення реальних проблем. Застосування методів загального призначення означає, що такі алгоритми можуть використовуватися в багатьох системах, від моделювання клімату та аналізу хвороб до біржових торгів.
У середу результати дослідження були опубліковані в науковій журналі Nature.
Аналогічний розвиток здійснюється на Facebook. Марк Заккерберг повідомляє Середу, що його дослідники знаходяться поруч, щоб завоювати китайська гра. Zuckerberg буквально спостерігає процес розробки: автор проекту сидить шість метрів від столу Генерального директора Facebook.
Дослідження Facebook: arXiv:1511.06410 [cs.LG]
Джерело: geektimes.ru/post/269990/