识别号:A到9
 Bashny.Net
Bashny.Net
已经是情侣对哈布雷次出现如何识别号码现在工作的讨论。但在本文中,这将显示出不同的方法来识别号码,直到哈布雷不是。所以在这里,我们将试着去了解所有的工作原理。然后,如果文章会感兴趣,并会继续公布的工作模式,可以poissledovat。

软件VS铁 H4>的一个重要参数,建立识别的系统 - 铁用于摄影。更强大的和更好的照明系统中,相机越好,越可能识别的数目。良好的红外(IR)照明可以启发甚至灰尘和脏物,可在室内,风头盖过所有的干扰因素。我觉得有人来了类似的“连锁信”,其中除了房间什么都看不到。
算法的结构 H4>•高级搜索次数 B> - 检测区域,其中包含了一些
的边界和形状,轮廓分析分析 H5>的隔离房间,最明显的方法 - 找一个矩形轮廓。仅在情况下,当有一个清晰可读的轮廓没有围栏,具有足够高的分辨率和光滑边界。
边框 H5>只有部分的分析,更有趣,更稳定,更实用的方法似乎 ,其中,它的分析的范围的一部分。强调轮廓,然后找遍了所有的垂直线。用于位于彼此接近,具有沿轴y的轻微移位,与它们之间的距离,以它们的长度正确的比例,一个假设,即在它们之间的房间任何两行。其实,这种做法类似于简化的方法 HOG 。
地区 H5>其中的一个方法是最常用的方法直方图分析图像直方图分析( 1 ,的 2 )。该方法是基于这样的假设与一些来自附近的频率响应不同的区域的频率特性。
统计分析,分类 H5>什么是减去所有以前的方法?事实上,在真正的,沾满了泥巴房表示没有国界,没有显着的统计数据。从下面示出了这样的数字的一些例子。我必须说,莫斯科,这样的例子还不是最糟糕的选择。
的 h5的>的薄弱点在实际的算法的很多方法都直接或间接地基于该室的边界的存在。即使不使用用于检测室的限制,它可以被用于进一步的分析。
第2部分:标准化的算法 H4>最上面的算法展品数量不准确,需要进一步澄清了他的立场,并提高图像质量。例如,在这种情况下,需要旋转和裁剪边缘如下:
在水平方向上旋转数 h5的>当单独留下邻里间,隔离边界开始工作好得多,因为所有的长条水平线,其设法提取 - 这将是在房间的边界。
增加对比度 h5的>而最好的方式或其他改善得到的图像的对比度。严格来说,有必要加强的空间频率的感兴趣区域方法:
上的字母分区 H5>旋转之后,我们有一个带横向不准确明确的左右两边。正是削减不必要的,现在不一定够简单地削减字母在房间里提供的识别过程中与他们一起工作。
弱点 H5>有了显著数周期性的污染峰上的符号分区不能随便露面,虽然字符可以在视觉上相当的可读性。
第3部分:字符识别算法 H4>识别,一方面文本或单个字符(光学字符识别,OCR)的问题是困难的,但另一方面 - 相当经典。有许多算法来解决它,其中一些达到完美 的。另一方面,在公共领域的最佳算法不。当然有相当的tesseract OCR和他的几个同龄人,但这些算法不能解决所有的问题。在一般情况下,文字识别的方法可分为两类:基于结构形态和电路分析处理的基础上,直接图像的分析的二值化图像和光栅的方法的方法。这通常使用的结构和光栅方法的组合
与标准的任务OCR H5>首先,在俄罗斯,汽车数量,标准字体的任何情况。它只是为标志的自动识别系统的礼物。 90%的努力花在OCR手写。
的tesseract OCR H5>这是执行自动识别为一个字母,马上文本开源软件。 的tesseract 很方便,因为它是,对于任何操作系统运行稳定,易于接受训练的。但是,它的工作原理非常差与zamylennym,破,脏,变形的文字。当我试图做到这一点就承认房间 - 就只有20-30%的客房从数据库中强度正确识别。最清晰和直接。当然,虽然,当你使用现成的库依赖的东西的手曲率半径。
K-最近的 H5>很容易理解的文字识别,其中,尽管它的原始,往往不能赢得最成功实施SVM和神经网络方法的方法。
相关 H5>大多数方法,这些方法在图像识别中使用的,建立在实证的方法。但是,没有人禁止使用概率论,这只是抛光信号检测的雷达系统问题的数学工具。在我们知道赛车号码字体,相机室内噪声和灰尘难以被称为高斯。上有符号和斜率的位置一定的不确定性,但这些参数可以重复。如果我们离开图像进行二值化,但我们仍然未知,并且信号的振幅,吨; E.符号的亮度。
神经网络 H5>
结论 H4>本文介绍了识别的基本方法,它们的典型故障和错误。或许,这将帮助你周围的城市旅游,或反之亦然,当让你的房间有点更具可读性。
引用 H4> 1)算法和数学原理的自动车牌识别系统的Ondrej MARTINSKY - 评论文章。

软件VS铁 H4>的一个重要参数,建立识别的系统 - 铁用于摄影。更强大的和更好的照明系统中,相机越好,越可能识别的数目。良好的红外(IR)照明可以启发甚至灰尘和脏物,可在室内,风头盖过所有的干扰因素。我觉得有人来了类似的“连锁信”,其中除了房间什么都看不到。

结果的可靠性 - 拍摄的系统更好。最好的算法,如果没有良好的拍摄是没有用的:你总能找到无法识别一个房间。下面是两个非常不同的画面:

本文讨论了完全软件的一部分,重点是其中的数字被严重可见,扭曲(只拍过“手”的任何镜头)的情况下。


算法的结构 H4>•高级搜索次数 B> - 检测区域,其中包含了一些
•正常化号 B> - 房间的确切边界的定义,标准化konstrastom
• OCR B> - 阅读所有被发现的归一化图像
这个基本结构。当然,在一个情况下的数量呈线性位置和光线充足,并在您的处置有很大识别算法文字,前两项消失。在一些算法可以组合号码搜索和规范化。
第1部分:算法高级搜索 H4>
的边界和形状,轮廓分析分析 H5>的隔离房间,最明显的方法 - 找一个矩形轮廓。仅在情况下,当有一个清晰可读的轮廓没有围栏,具有足够高的分辨率和光滑边界。

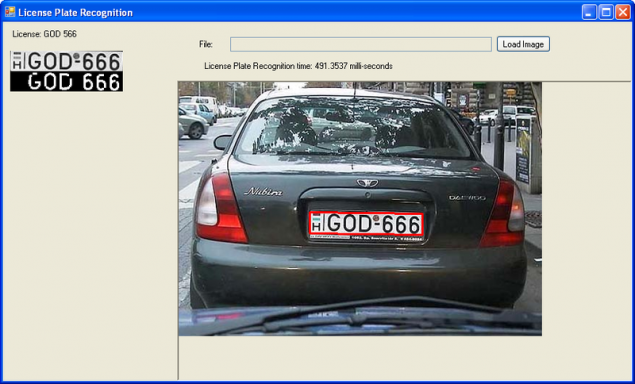
要过滤的图像找到<一href="http://ru.wikipedia.org/wiki/%D0%92%D1%8B%D0%B4%D0%B5%D0%BB%D0%B5%D0%BD%D0%B8%D0%B5_%D0%B3%D1%80%D0%B0%D0%BD%D0%B8%D1%86">границ 然后分配都发现自己的轮廓和<a href="http://robocraft.ru/blog/computervision/640.html">分析。几乎与图像处理的所有学生的作业都做了这种方式。在互联网全例子。工作不正常,但不知何故。


边框 H5>只有部分的分析,更有趣,更稳定,更实用的方法似乎 ,其中,它的分析的范围的一部分。强调轮廓,然后找遍了所有的垂直线。用于位于彼此接近,具有沿轴y的轻微移位,与它们之间的距离,以它们的长度正确的比例,一个假设,即在它们之间的房间任何两行。其实,这种做法类似于简化的方法 HOG 。
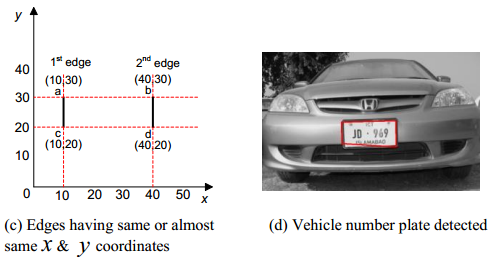

地区 H5>其中的一个方法是最常用的方法直方图分析图像直方图分析( 1 ,的 2 )。该方法是基于这样的假设与一些来自附近的频率响应不同的区域的频率特性。


分配的图像边界(图像的高空间分量的分配)。我们构造上的轴y的投影图像(有时在轴x)。获得最大突起可与室内的位置相重合。
这种方法有一个缺点显著 - 机器的尺寸应与帧的大小相当,即A.背景可以包含铭文或其它细节的物体。


统计分析,分类 H5>什么是减去所有以前的方法?事实上,在真正的,沾满了泥巴房表示没有国界,没有显着的统计数据。从下面示出了这样的数字的一些例子。我必须说,莫斯科,这样的例子还不是最糟糕的选择。

1304086
最佳做法,虽然不经常不够用,根据不同的分类方法,这。例如,效果很好训练有素哈尔级联。这些方法使您能够分析该地区的关系,分梯度她的特征数的存在。最美丽的,我认为基于一个专门синтезированном转换。诚然,我没有试过,但是,乍看之下,应该稳步推进。
这些方法允许发现不仅仅是一个房间号和一个复杂的和非典型的条件。同样的级联哈尔基地收集在冬天在莫斯科的中心了约90%的正确检测室和2-3%的假捕获。无论检测算法边框或直方图不能发出这样的质量检测上如此糟糕的画面。

的 h5的>的薄弱点在实际的算法的很多方法都直接或间接地基于该室的边界的存在。即使不使用用于检测室的限制,它可以被用于进一步的分析。
令人惊讶的,但对于统计学算法复杂的情况下,它可以是,即便是比较干净的房间中铬(光)帧上的白色汽车,因为它发生得较不频繁脏的房间以及不能满足在训练足够次数。
第2部分:标准化的算法 H4>最上面的算法展品数量不准确,需要进一步澄清了他的立场,并提高图像质量。例如,在这种情况下,需要旋转和裁剪边缘如下:


在水平方向上旋转数 h5的>当单独留下邻里间,隔离边界开始工作好得多,因为所有的长条水平线,其设法提取 - 这将是在房间的边界。
最简单的过滤器,能够释放这种直接的 - 转换<一href="http://ru.wikipedia.org/wiki/%D0%9F%D1%80%D0%B5%D0%BE%D0%B1%D1%80%D0%B0%D0%B7%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D0%B5_%D0%A5%D0%B0%D1%84%D0%B0">Хафа:

转换一怒之下允许快速区分两条主线和裁剪图像上他们:



增加对比度 h5的>而最好的方式或其他改善得到的图像的对比度。严格来说,有必要加强的空间频率的感兴趣区域方法:


上的字母分区 H5>旋转之后,我们有一个带横向不准确明确的左右两边。正是削减不必要的,现在不一定够简单地削减字母在房间里提供的识别过程中与他们一起工作。
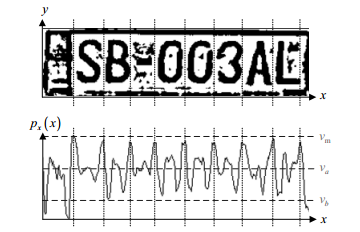
(这个数字已经进行了二值化操作,T。E.使用的像素分离的一些规则分为两类,在对人物的客房分离,则不需要此操作,并在未来可能被证明是有害的)
现在就足够了找到的最大水平的图表,并且这将是空白的字母。特别是如果我们希望有一定量的字符和标记之间的距离将是大约相同的,则在该直方图中的字母分区将很好地工作。
人们只能切配信,去为他们的鉴定程序。

弱点 H5>有了显著数周期性的污染峰上的符号分区不能随便露面,虽然字符可以在视觉上相当的可读性。
水平边框的房间 - 并不总是一个很好的基准。客房名义上可以随意弯曲(奔驰C级),可仔细沉没在了错误的近方形凹槽,用于室内的美国车。及背面室的上限值是身体的只是一部分被包括的元素。
当然,考虑到所有这些问题 - 这是承认数字的系统,一个严重的问题
。
第3部分:字符识别算法 H4>识别,一方面文本或单个字符(光学字符识别,OCR)的问题是困难的,但另一方面 - 相当经典。有许多算法来解决它,其中一些达到完美 的。另一方面,在公共领域的最佳算法不。当然有相当的tesseract OCR和他的几个同龄人,但这些算法不能解决所有的问题。在一般情况下,文字识别的方法可分为两类:基于结构形态和电路分析处理的基础上,直接图像的分析的二值化图像和光栅的方法的方法。这通常使用的结构和光栅方法的组合
与标准的任务OCR H5>首先,在俄罗斯,汽车数量,标准字体的任何情况。它只是为标志的自动识别系统的礼物。 90%的努力花在OCR手写。
第二,污垢。
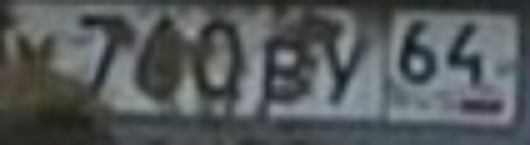
此处则必须把用于字符识别的已知方法的绝对多数,特别是当图像的路径进行二值化来检查的分隔区的连通性。
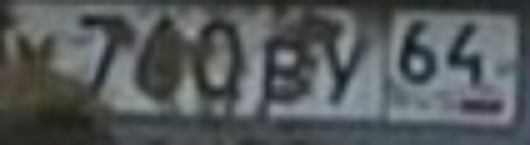
的tesseract OCR H5>这是执行自动识别为一个字母,马上文本开源软件。 的tesseract 很方便,因为它是,对于任何操作系统运行稳定,易于接受训练的。但是,它的工作原理非常差与zamylennym,破,脏,变形的文字。当我试图做到这一点就承认房间 - 就只有20-30%的客房从数据库中强度正确识别。最清晰和直接。当然,虽然,当你使用现成的库依赖的东西的手曲率半径。
K-最近的 H5>很容易理解的文字识别,其中,尽管它的原始,往往不能赢得最成功实施SVM和神经网络方法的方法。
它的工作原理如下:
1)预先记录的字符已经正确划分阶级用自己的眼睛和双手
真实图像的体面的数额
2)引入的码元之间的距离的量度(如果图像进行二值化,XOR操作是最佳的层)
3)然后,当我们试图识别的符号,进而算出其与数据库中的所有的字符之间的距离。其中k个最近的邻居可能是不同类别的代表。当然,更多的类的邻里之间的成员,该类应该包括识别符号。
从理论上讲,如果我们写了一个非常大的数据库,从不同的角度,灯光拍摄,所有的摩擦字符的例子中,K-最近的 - 这是你所需要的。不过,你需要快速计算出图像,因此,二值化,它的使用XOR之间的距离。但随后是在被污染或磨损的房间将是问题的情况下。二值化处理不可预知的改变性格。
该方法具有一个很重要的优点:它是简单和透明的,并因此便于调试和调谐到最佳的结果。在许多情况下,重要的是了解你的算法是重要的。
相关 H5>大多数方法,这些方法在图像识别中使用的,建立在实证的方法。但是,没有人禁止使用概率论,这只是抛光信号检测的雷达系统问题的数学工具。在我们知道赛车号码字体,相机室内噪声和灰尘难以被称为高斯。上有符号和斜率的位置一定的不确定性,但这些参数可以重复。如果我们离开图像进行二值化,但我们仍然未知,并且信号的振幅,吨; E.符号的亮度。
我并不想进入这个问题的制品内的精确解。实际上它仍然是一切都归结为计算输入信号的协方差与假设(考虑设置位移和旋转)的操作:
X - 输入信号,Y - 一个假设。代号E - 期望
如果有必要从不同的符号来选择,设定为旋转和位移作图对于每个符号。如果我们知道,在输入图像中包含的符号,所有假设的最大协方差定义一个符号,它的偏移量和斜率。当然,这里也提出了不同的字符的接近的图像的问题(“p”和“c”的,“○”和“c”等)。最简单的 - 你输入的每一个字符的权重系数矩阵
。
有时,这些方法被称为«模板匹配»,这充分体现了他们的本质。定的模式 - 输入图像与样品相比较。如果在参数中的任何不确定性,那么无论是遍历所有可能的选项,或者使用<一个href="http://fit.tstu.ru:8080/jspui/bitstream/123456789/10163/1/%D0%A3%D1%87%D0%B5%D0%B1%D0%BD%D0%BE%D0%B5%20%D0%BF%D0%BE%D1%81%D0%BE%D0%B1%D0%B8%D0%B5%20%D0%9E%D1%81%D0%BD%D0%BE%D0%B2%D1%8B%20%D1%82%D0%B5%D0%BE%D1%80%D0%B8%D0%B8%20%D0%BE%D0%B1%D1%80%D0%B0%D0%B1%D0%BE%D1%82%D0%BA%D0%B8%20%D0%B8%D0%B7%D0%BE%D0%B1%D1%80%D0%B0%D0%B6%D0%B5%D0%BD%D0%B8%D0%B9.pdf">адаптивные接近,虽然这里已经知道和理解数学有。
该方法的优点:
- 可预测的和充分研究的结果,如果一个小噪声对应于所选择的模式;
- 如果字体设置严格,在我们的例子中,它能够识别多灰尘/脏污/戴字符
。
缺点:
- 计算上非常昂贵
。
神经网络 H5> 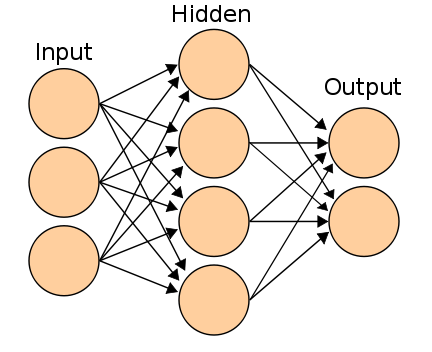
关于人工神经网络哈布雷已经写了很多 。现在,他们被分为两代:
- 2-3层经典神经网络研究与错误(3层图中所示的神经网络)的反向传播梯度法;
- 所谓的深度学习神经网络和卷积网络
。
第二代神经网络在过去的7年,对获奖的图像识别的各种比赛,给人的结果是比其他方法略好。
还有手写体数字图像的打开的数据库。表 的结果很清楚地表明了各种方法的演变,包括基于神经网络算法。
另外值得特别一提的是,字体印刷工作得很好,单层或双层(术语的问题)网络,基本上是没有什么不同于模板匹配的方法。
该方法的优点:
- 当正确配置和培训可能比其它已知的方法更好;
- 随着越来越多的数据集学习性,以人物的变形
。
缺点:
- 最困难的这些方法;
- 行为异常的多层网络诊断是根本不可能的
。

结论 H4>本文介绍了识别的基本方法,它们的典型故障和错误。或许,这将帮助你周围的城市旅游,或反之亦然,当让你的房间有点更具可读性。
不过,我希望能表现出完全没有魔法,以表彰数的问题。一切都非常清楚和直观。这不是在相关专业学生的课程学习一个可怕的问题。
几天后 ZlodeiBaal 放小raspoznavalka号码,根据我们上这文章写的工作。它可以是一个圈套。
ZY所有的房间,这是列在文章 - 从谷歌和Yandex的简单的请求中提取
引用 H4> 1)算法和数学原理的自动车牌识别系统的Ondrej MARTINSKY - 评论文章。
2)实时移动车牌检测与识别 Kuo-明红和青唐谢承认的数字
-gistogrammny方法
3)<一href="http://www.porikli.com/mysite/pdfs/porikli_2006_avss_-_robust_license_plate_detection_using_covariance_descriptor_in_a_neural_network_framework.pdf">Robust车牌检测的神经网络框架法提赫Porikli,特勤本地产采用协方差描述 - 找到房间的神经网络方法
4)自动车牌识别方法霍夫线和模板匹配 Saqib拉希德,阿萨德纳伊姆和奥马尔·伊沙克 - 通过HOG-描述垂直线
找房
5)方法用于字符识别的调查的Suruchi G. Dedgaonkar,综合外电A. Chandavale,阿肖克M 。Sapkal - 关于表彰山毛榉和数字
小的综述文章
7)教材«<一href="http://fit.tstu.ru:8080/jspui/bitstream/123456789/10163/1/%D0%A3%D1%87%D0%B5%D0%B1%D0%BD%D0%BE%D0%B5%20%D0%BF%D0%BE%D1%81%D0%BE%D0%B1%D0%B8%D0%B5%20%D0%9E%D1%81%D0%BD%D0%BE%D0%B2%D1%8B%20%D1%82%D0%B5%D0%BE%D1%80%D0%B8%D0%B8%20%D0%BE%D0%B1%D1%80%D0%B0%D0%B1%D0%BE%D1%82%D0%BA%D0%B8%20%D0%B8%D0%B7%D0%BE%D0%B1%D1%80%D0%B0%D0%B6%D0%B5%D0%BD%D0%B8%D0%B9.pdf">Основа图像处理»,克拉舍宁尼科夫VR
理论
资料来源: habrahabr.ru/post/221891/
标签
另请参见
里面有什么
"可怕的"利益:当接近充满热情,有关"恐怖"
作为你的身体形式的命运
如何停止休假,开始工作
如何做空中交通管制
阿尔法男性,你在哪里?
纸牌游戏
前15名的国家和有趣的网站在互联网上(注意在一些非常粘)
为什么俄罗斯几乎没有民用/商用高科技制造业?