Computadoras hombres anuladas en test de inteligencia verbal
 Bashny.Net
Bashny.Net
Hace más de cien años, el psicólogo alemán William Stern (William Stern) propuso una prueba de evaluación de la inteligencia humana, que fue nombrado test de inteligencia. Desde entonces, la prueba de coeficiente intelectual era bastante generalizado como un método estándar para estimar la inteligencia de los niños al ingresar a la escuela, así como para la evaluación de los candidatos adultos para el trabajo.
Los tests de inteligencia general contienen tres tipos de preguntas: 1) preguntas de la lógica en que es necesario reconocer un patrón en la secuencia de imágenes; 2) cuestiones matemáticas, donde se define un patrón en una secuencia de números; 3) tareas verbales basadas en analogías y clasificaciones como sinónimos y antónimos.
Los investigadores de la división Microsoft Research en Beijing, junto con colegas de la Universidad de Ciencia y Tecnología de China desarrollaron la tecnología de la IA capaz de resolver los problemas del tercer tipo de los anteriores ( artículo científico < / a>).
Computadoras nunca podrían tener una buena comprensión y resolver problemas formulados en forma verbal. Por lo menos, lo hicieron las personas mucho peores. Microsoft Research Development cambia las cosas. Su programa se basa en un sistema de aprendizaje profundo (aprendizaje profundo), la primera vez superó los resultados promedios mostrados por la gente en la solución de problemas de palabras de test de inteligencia.
En años anteriores, los científicos han utilizado la técnica de minería de datos para analizar grandes cantidades de texto para encontrar conexiones específicas entre las palabras. En particular, esta técnica le permite compilar un diccionario de indicadores estadísticos de la frecuencia con palabras cierto se encuentran cerca. Esto le permite determinar la relación de las palabras entre sí.
Como resultado, cada palabra en un sistema de este tipo es visto como un vector en un espacio de parámetro multidimensional. Tal sistema de vectores puede ser manejado por métodos matemáticos: comparar ellos, sumar, restar una de la otra, como vectores convencionales. Por ejemplo, es posible una ecuación similar: ". King - hombre + mujer = Reina»
Este enfoque ha demostrado ser eficaz. Por ejemplo, Google utiliza el sistema de extracción de datos de traducción automática de textos mediante la comparación de los vectores de las palabras en diferentes idiomas.
Pero en el caso de las pruebas de coeficiente intelectual verbal el problema se complica porque no es una palabra puede tener varios significados. Los compiladores de las pruebas hechas especialmente para que complican la tarea.
Un grupo de investigadores de la división Microsoft Research encontró una solución para este problema mediante el uso de la misma-Minería de datos: su programa determina qué palabras más a menudo se encuentran cada palabra en el conjunto de los textos, y luego determina el posible significado de la palabra, sobre la base de la información recibida. Esto se hace mediante el cálculo de los vectores de las propuestas recibidas. Para el primer programa en una matriz de frecuencia de ocurrencia de las palabras, y luego basado en el corpus (artículo de Wikipedia) para cada ocurrencia de la palabra indica un vector de TI con otras palabras.
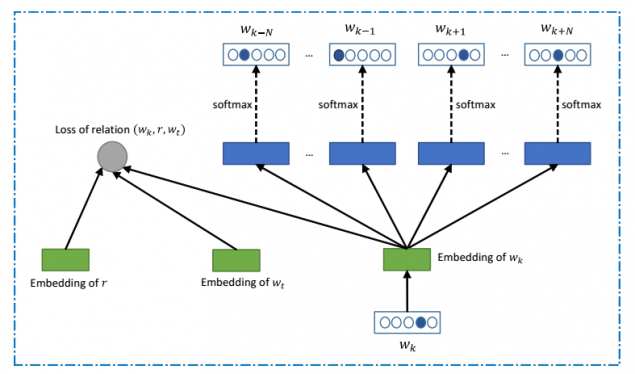
Los científicos dicen que el programa muestra un mejor resultado que la mayoría de la gente. La encuesta se llevó a cabo la gente en línea Mechanical Turk.
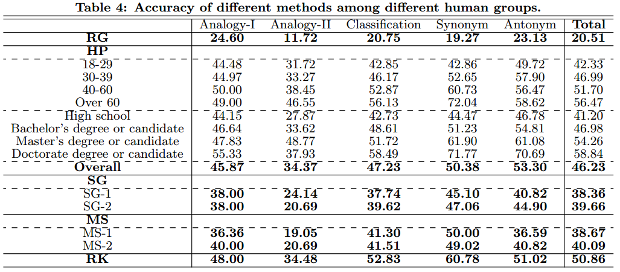
De acuerdo con la tabla, su resultado está a medio camino entre los resultados, que muestran resultados promedio solteros y titulares de maestría.
Fuente: geektimes.ru/post/252196/
Los tests de inteligencia general contienen tres tipos de preguntas: 1) preguntas de la lógica en que es necesario reconocer un patrón en la secuencia de imágenes; 2) cuestiones matemáticas, donde se define un patrón en una secuencia de números; 3) tareas verbales basadas en analogías y clasificaciones como sinónimos y antónimos.
Los investigadores de la división Microsoft Research en Beijing, junto con colegas de la Universidad de Ciencia y Tecnología de China desarrollaron la tecnología de la IA capaz de resolver los problemas del tercer tipo de los anteriores ( artículo científico < / a>).
Computadoras nunca podrían tener una buena comprensión y resolver problemas formulados en forma verbal. Por lo menos, lo hicieron las personas mucho peores. Microsoft Research Development cambia las cosas. Su programa se basa en un sistema de aprendizaje profundo (aprendizaje profundo), la primera vez superó los resultados promedios mostrados por la gente en la solución de problemas de palabras de test de inteligencia.
En años anteriores, los científicos han utilizado la técnica de minería de datos para analizar grandes cantidades de texto para encontrar conexiones específicas entre las palabras. En particular, esta técnica le permite compilar un diccionario de indicadores estadísticos de la frecuencia con palabras cierto se encuentran cerca. Esto le permite determinar la relación de las palabras entre sí.
Como resultado, cada palabra en un sistema de este tipo es visto como un vector en un espacio de parámetro multidimensional. Tal sistema de vectores puede ser manejado por métodos matemáticos: comparar ellos, sumar, restar una de la otra, como vectores convencionales. Por ejemplo, es posible una ecuación similar: ". King - hombre + mujer = Reina»
Este enfoque ha demostrado ser eficaz. Por ejemplo, Google utiliza el sistema de extracción de datos de traducción automática de textos mediante la comparación de los vectores de las palabras en diferentes idiomas.
Pero en el caso de las pruebas de coeficiente intelectual verbal el problema se complica porque no es una palabra puede tener varios significados. Los compiladores de las pruebas hechas especialmente para que complican la tarea.
Un grupo de investigadores de la división Microsoft Research encontró una solución para este problema mediante el uso de la misma-Minería de datos: su programa determina qué palabras más a menudo se encuentran cada palabra en el conjunto de los textos, y luego determina el posible significado de la palabra, sobre la base de la información recibida. Esto se hace mediante el cálculo de los vectores de las propuestas recibidas. Para el primer programa en una matriz de frecuencia de ocurrencia de las palabras, y luego basado en el corpus (artículo de Wikipedia) para cada ocurrencia de la palabra indica un vector de TI con otras palabras.

Los científicos dicen que el programa muestra un mejor resultado que la mayoría de la gente. La encuesta se llevó a cabo la gente en línea Mechanical Turk.

De acuerdo con la tabla, su resultado está a medio camino entre los resultados, que muestran resultados promedio solteros y titulares de maestría.
Fuente: geektimes.ru/post/252196/
Tags
Vea también
Sergey Anchutkin: "Creo que el mundo es diferente"
Esta prueba de cinco minutos le dirá que el subconsciente se esconde de usted
Conciencia - el viento, no podemos verlo, pero podemos distinguir entre los resultados
Viacheslav ivanov: el universo mira con los ojos de la gente
A veces la gente está buscando toda la vida, y a veces encuentran por día...
Prisión holandesa
Engaños
Engaños
El puesto está hecha donrumata
SOLO SIN MANOS. Y no sólo